
点云分割网络---Point Transformer V2
PDF: 《Point Transformer V2: Grouped Vector Attention and Partition-based Pooling》
CODE: https://github.com/Gofinge/PointTransformerV2
一、大体内容
前面一篇文章介绍了Point Transformer,这一篇在其基础上进行改进,提出了强大且高效的Point Transformer V2模型,考虑到原先的效率问题,提出了组向量注意力并继承了可学习权重编码和多头注意力的优点,提出一种新的分组权重编码层的分组向量注意力,来提升模型效率;通过额外的位置编码乘法器来增强位置信息;设计了一套新颖且轻量的分区池化方法,更好地实现了空间对齐和高效采样。通过实验表明在几个具有挑战性的3D点云场景理解基准上达到了最先进的水平,包括ScanNet v2和S3DIS上的3D点云和ModelNet40上的三维点云分类。
如下图可以看出V1和V2的差异点:
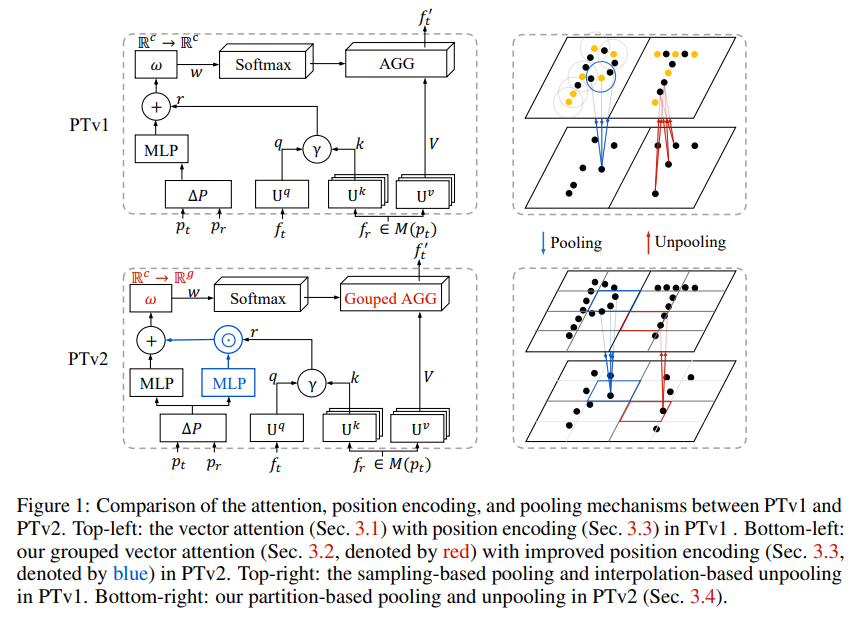
其分割网络结构还是类似V1呈Encoder-Decoder形式。

二、贡献点
- 提出一个高效的分组向量注意力(GVA),其具有新颖的权重编码层,使得能够在关注组内和关注组之间进行有效的信息交换。
- 引入一种改进的位置编码方案,可以更好地利用点云坐标,进一步提高模型空间推理能力
- 设计基于分区的池化策略,实现更高效、空间上更好的信息聚合
三、细节
3.1 分组向量注意力(GVA)
把向量拆分成不同的组,每个组里面共享权重,达到减少参数量的效果,进而提升效率

注意输入输出,V1输入和输出都是,但分组后由于只有个组,所以输出是
更加直观的理解就是原先的向量注意力(VA)是每个向量之间密集连接,分组向量注意力(GVA)组内共享权重,组之间才进行密集连接。
还有其他两种设计,如不同组之间不进行连接(GVA-MSA), 直接在组内用MLP进行连接(GVA-Grouped Linear)。

3.2 位置编码
对比下公式大家就清晰了,
原先V1采用的是
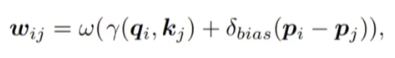
V2采用

3.3 分区池化

这个看图很明显,V1要通过KNN来查找最近邻,然后再做插值,这个计算量比较多,V2直接进行网格划分,同一个网格里面的点进行Pooling 和 Unpooling。
-
Pooling
还是采用最大池化,即同一个网格里面的点的特征进行最大池化操作,点进行平均池化
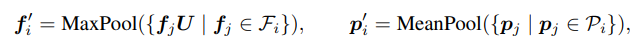
-
Unpooling
直接对同一个网格内的点进行特征复制
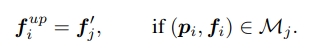
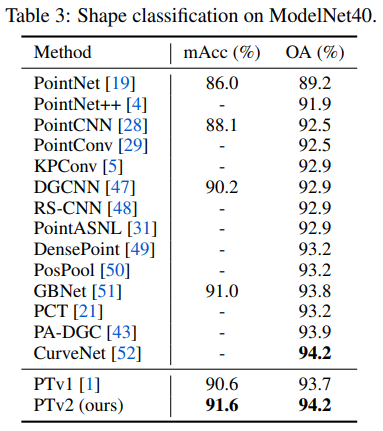
四、效果
4.1 分割
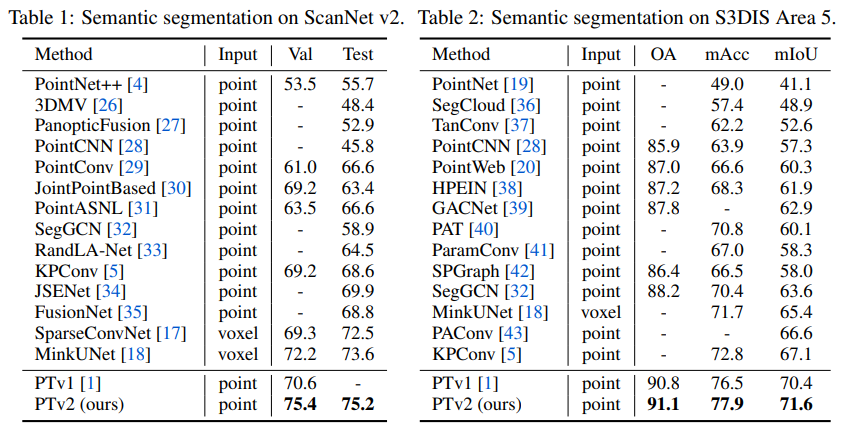
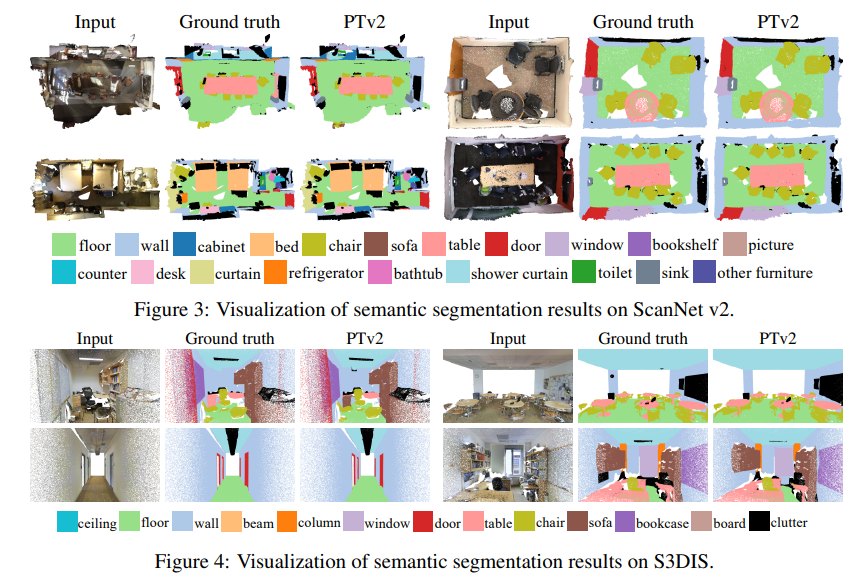
4.2 分类


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话
2022-07-03 ncnn编译与安装