
点云分割网络PointConv
PDF:《PointConv: Deep Convolutional Networks on 3D Point Clouds》
CODE: https://github.com/DylanWusee/pointconv
一、大体内容
PointConv是一种在非均匀采样下对3D点云进行卷积的运算,可以用来构建深度卷积网络,其将卷积核视为由权重函数和密度函数组成的三维点的局部坐标的非线性函数。对于给定的点,使用多层感知器网络和密度函数通过核密度估计来学习权重函数。为了更有效地计算权函数,还提出了一种新的改进方案,让其能够大幅扩展网络并显著提高其性能,这种卷积在3D空间中具有平移和旋转不变性。此外,PointConv还可以用作反卷积算子,将子采样点云的特征传播回其原始分辨率。在ModelNet40、ShapeNet和ScanNet数据集上取得了很好的效果。

二、贡献点
- 提出基于核密度估计的卷积运算PointConv
- 并提出加速版本(将PointConv用矩阵乘法和2d卷积实现)提升性能
- 将pointConv扩展到反卷积版本PointDeconv,可以获取更好的分割结果
三、细节
3.1 PointConv
点云处理的一些算法通常第一步就是对借助最远点采样对点云进行采样处理,可以减少样本数量并尽可能地保留点云原始的空间结构,但是这种采样是非均匀的,这样会导致某些局部区域点大量聚集,而某些区域的的点的数量又不足。另外3D点云不同于2D图像那样那么规则,点云具有更灵活的形状。点云中某个点的坐标不在固定网格上,而是可以采用任意连续值。因此,每个局部区域中不同点的相对位置是不同的。图像上的常规卷积滤波器无法直接应用于点云。

针对这些问题,本文提出PointConv来解决,其将卷积核视为由权重函数和密度函数组成的三维点的局部坐标的非线性函数,通过核密度估计可以避免非均匀采样带来的影响。PointConv结构如下:

如图a中所示为FPS采样后P0周围的采样点,将采样点坐标转换为局部相对坐标,特征记为,
图b中上半部分将相对坐标直接经过MLP1中,最终得到特征作为权重,
下半部分局部坐标先经过核密度估计(KDE)得到邻近点的密度(密度越大值越大),这里的采用密度的倒数,然后输入到MLP2得到S,并借助tile进行扩充后与输入特征进行相乘,这样就可以通过密度来干预特征的权重。
其中KDE可以参考源码的实现,其计算出每个点的高斯核密度。
# pts:一个形状为(batch_size, num_points, num_dimensions)的张量,包含了需要进行密度估计的点集。
# sigma:高斯核的带宽参数,控制核的宽度和平滑程度。
# kpoint:用于密度估计的邻居点的数量。如果点的数量少于kpoint,则将kpoint设置为点的数量减一。
# is_norm:一个布尔标志,指示是否对密度值进行归一化。
def kernel_density_estimation(pts, sigma, kpoint = 32, is_norm = False):
with tf.variable_scope("ComputeDensity") as sc:
batch_size = pts.get_shape()[0]
num_points = pts.get_shape()[1]
if num_points < kpoint:
kpoint = num_points.value - 1
with tf.device('/cpu:0'):
point_indices = tf.py_func(knn_kdtree, [kpoint, pts, pts], tf.int32)
batch_indices = tf.tile(tf.reshape(tf.range(batch_size), (-1, 1, 1, 1)), (1, num_points, kpoint, 1))
idx = tf.concat([batch_indices, tf.expand_dims(point_indices, axis = 3)], axis = 3)
idx.set_shape([batch_size, num_points, kpoint, 2])
grouped_pts = tf.gather_nd(pts, idx)
grouped_pts -= tf.tile(tf.expand_dims(pts, 2), [1,1,kpoint,1]) # translation normalization
R = tf.sqrt(sigma)
xRinv = tf.div(grouped_pts, R)
quadform = tf.reduce_sum(tf.square(xRinv), axis = -1)
logsqrtdetSigma = tf.log(R) * 3
mvnpdf = tf.exp(-0.5 * quadform - logsqrtdetSigma - 3 * tf.log(2 * 3.1415926) / 2)
mvnpdf = tf.reduce_sum(mvnpdf, axis = 2, keepdims = True)
scale = 1.0 / kpoint
density = tf.multiply(mvnpdf, scale)
if is_norm:
#grouped_xyz_sum = tf.reduce_sum(grouped_xyz, axis = 1, keepdims = True)
density_max = tf.reduce_max(density, axis = 1, keepdims = True)
density = tf.div(density, density_max)
return density
注意其中tile算子是为了让两个不同维度的张量能进行点乘运算,为了提高计算效率,通常把小维度张量进行扩充。
3.2 优化版本
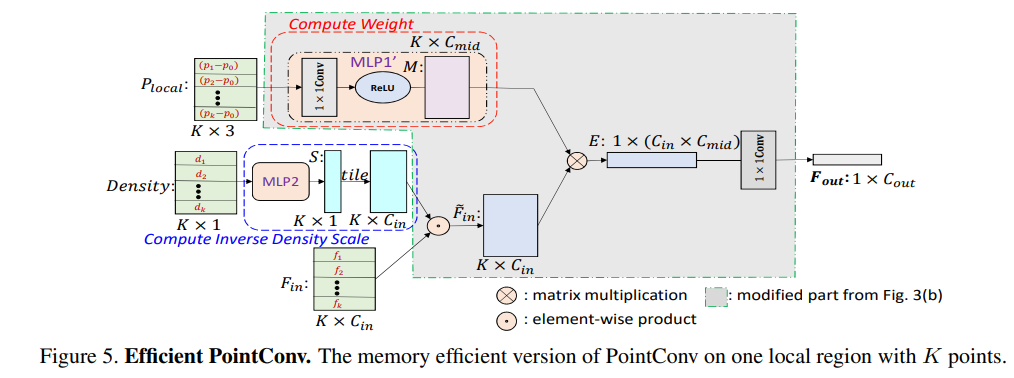
由3.1中介绍可以直到每个滤波器需要一个网络近似,如果多个PointConv组合会导致效率较低,太少性能又不太行,因此论文中提出了一种改进方案,将PointConv用矩阵乘法和2d卷积实现,具体的证明直接参考原文比较详细,这里直接给出图,大家对比下就清晰了。主要的改动是Compute Weight部分,把其中一个卷积移动到末尾了,它对GPU显存的需求比原来的少了64倍。
3.3 PointDeconv
对于分割任务,我们需要逐点预测,为了获得所有输入点的特征,需要一种将特征从子采样点云传播到原始的点云上。pointNet++中采用的是基于距离的插值,但没有充分利用反卷积操作的优势(从粗糙级别捕获传播信息的局部相关性),论文中提出pointDeconv(由插值和pointConv组成)来解决此问题。首先,采用插值法传播来自上一层的粗略特征。然后,使用skip-links将内插特征与来自具有相同分辨率的卷积层中的特征连接起来。连接后,我们对连接的特征应用PointDeConv以获得最终的特征输出。

四、效果
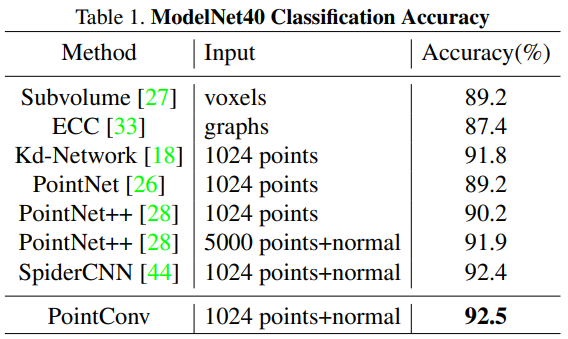
4.1 ModelNet40上分类效果
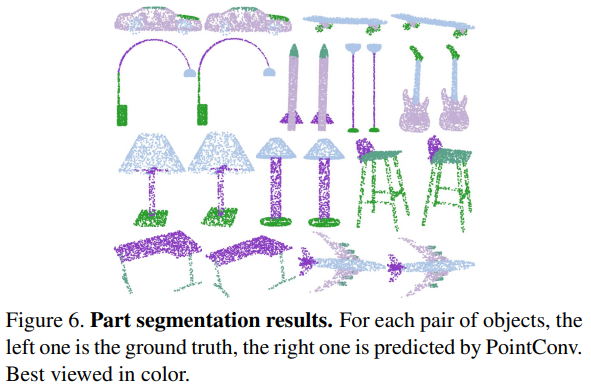
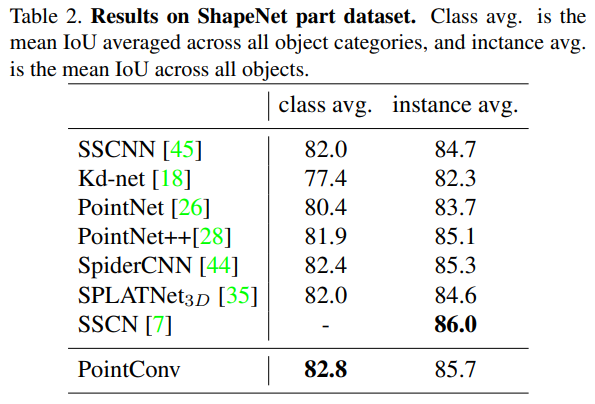
4.2 ShapeNet上部件分割效果
4.3 场景语义分割效果
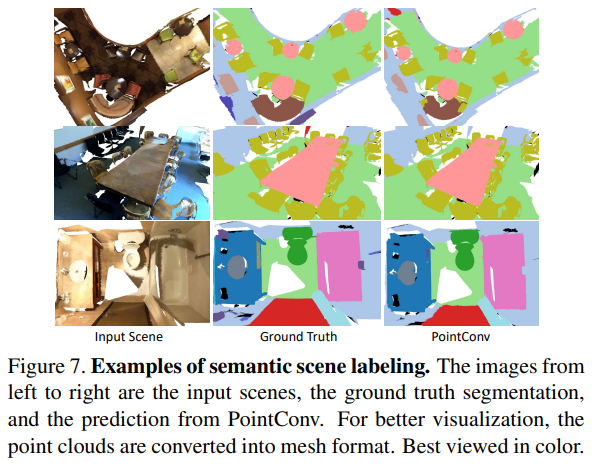
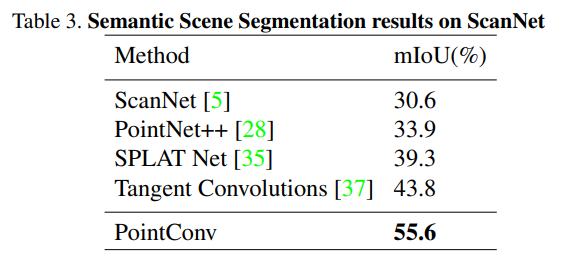


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端