
OpenPCDet模型导出ONNX
前面介绍了采用OpenPCDet架构和自定义数据集训练了pointRCNN模型,也已经跑通了测试流程,但在实际应用过程中通常需要把模型导出成ONNX格式,然后借助其他框架用C++进行推理。这里记录一下pointRCNN导出流程以及常见的一些错误。其大体分为以下几步:
- 弄清楚数据流
- 确定网络架构
- 改写网络
- 模型导出
一、OpenPCDet大体数据流
在模型导出时先要弄清楚数据流,OpenPCDet通过配置文件如pointrcnn.yaml来控制网络结构,一个网络通常由几个模块组成,像pointRCNN就由PointNet2MSG、PointHeadBox,PointRCNNHead三个模块组成,模块之间的数据通过一个字典batch_dict来控制衔接,如下是基本的推理接口:
def forward(self, batch_dict):
for cur_module in self.module_list:
batch_dict = cur_module(batch_dict)
这种情况下方如果直接导出模型机会报以下错误:
RuntimeError: Only tuples, lists and Variables supported as JIT inputs/outputs. Dictionaries and strings are also accepted but their usage is not recommended. But got unsupported type numpy.ndarray
其主要原因是导出时这种字典结构里面包含量numpy.ndaary内容,我找了一些资料如:https://github.com/open-mmlab/OpenPCDet/issues/228,但还是没能解决,最后处理方式是比较暴力,直接弄清楚模型的网络架构,得到每一个模块,然后将每一个模块进行改写,在加载对应权重后导出。接下来我们看下如何确定网络架构以及如何改写。
二、网络架构
网络架构好确定,主要是借助测试脚本,把模型按照OpenPCDet架构加载好之后,打印出网络结构,然后看下有哪几部分,下面以pointRCNN为例。在模型加载完成后,借助print(model.module_list)和print(len(model.module_list))两行代码得到模块内容和个数。
比如PointRCNN按前面配置输出后就有3个大模块PointNet2MSG,PointHeadBox,PointRCNNHead。
部分代码如下
model.load_params_from_file(filename=args.ckpt, logger=logger, to_cpu=dist_test,
pre_trained_path=args.pretrained_model)
model.cuda()
model.eval()
print("------------------")
print(dir(model))
print(model.module_list)
print(len(model.module_list))
print("******************")
弄清出网络模块后,接下来就到了关键步骤了,那就是改写网络结构。
三、网络改写
在改写之前便于更好的理解,可以以一个数据,通过调试的形式,把每个模块的输入输出以及中间流程搞清楚,这样在改写时会更加清晰。下面输入两个数量为7000的点云样本,特征通道我们默认为1,其值全为0,接下来分别对PointNet2MSG,PointHeadBox,PointRCNNHead进行分析。
pointNet2MSG
这个模块主要是借助pointNet++网络提取特征
- 输入输出
In: 坐标xyz(B: 2, N: 7000, C: 3), 特征feature(B: 2, C: 1, N: 7000)
Out: feature(B, 128, N), xyz(B, N, 3) - 数据流
数据经过处理后先来到pcdet/models/backbones_3d/pointnet2_backbone.py中的PointNet2MSG。主要包含SA_modules和FP_modules。
大体数据流是坐标xyz(B: 2, N: 7000, C: 3), 特征feature(B: 2, C: 1, N: 7000) ==>SA0->f(2, 96, 4096) > SA1 -> f(2,256,1024)> SA2 -> f(2, 512, 256) ==> SA3 -> f(2, 1024, 64) ==> FP3 -> f(2, 512, 256) ==> FP2 -> f(2, 512, 1024) ==> FP1 -> f(2, 256, 4096) ==> FP0 -> f(2, 128, 7000)。
PointHeadBox
- 输入输出
In: feature(B, 128, N)
Out: cls_feature(B, 1, N), box_feature(B, 8, N) - 数据流
经过前面的特征提取后得到特征再经过pcdet/models/dense_heads/pint_head_box.py中的PointHeadBox类。主要作用是用来判断前景点和框信息。
这一块比较简单,cls_layers和box_layers都是LBR(Linear + BatchNorm1d + ReLU)模块组成。两个模块是独立的,输入都是前一步提取的特征。
cls_layers输出类别(前景或背景),维度变换后为(BN, 1),box_layers输出框信息,维度为(BN,8),8表示框的7个维度:x_c, y_c, z_c, w, h, l, angle + 置信度score。
PointRCNNHead
- 输入输出
In: xyz(B, N, 3),point_feature(B, 128, N), cls_feature(B, 1, N), box_feature(B, 8, N)
Out: cls(B, 1, N_roi), box_feature(B, 7, N_roi)
再经过pcdet/models/roi_heads/pointrcnn_head.py中的PointRCNNHead类。包含有proposal_target_layer, SA_modules,xyz_up_layer,merge_down_layer,cls_layers, reg_layers和roipoint_pool3d_layer。其执行顺序是:
proposal_target_layer ==>roipoint_pool3d_layer ==> xyz_up_layer ==> merge_down_layer ==> SA_modules ==> cls_layers/reg_layers
在具体执行时先在proposal_layer方法中借助NMS对框进行过滤。输出指定个数N=100的roi(2, 100, 7), roi_scores(2, 100)以及roi_labels(2, 100)
改写pointNet2MSG
经过以上步骤我们就会弄清楚模型的结构以及数据流,那接下来导出也是分模块进行。这里以PointNet2MSG为例,看下主要改动点在哪些地方。
- 新建
在导出脚本中新建一个类叫做PointNet2MSGExport,首先把pointNet2MSG的内容全部copy过来。
class PointNet2MSGExport(nn.Module):
def __init__(self, model_cfg, input_channels, **kwargs):
super().__init__()
self.model_cfg = model_cfg
self.SA_modules = nn.ModuleList()
channel_in = input_channels - 3
self.num_points_each_layer = []
skip_channel_list = [input_channels - 3]
for k in range(self.model_cfg.SA_CONFIG.NPOINTS.__len__()):
mlps = self.model_cfg.SA_CONFIG.MLPS[k].copy()
channel_out = 0
for idx in range(mlps.__len__()):
mlps[idx] = [channel_in] + mlps[idx]
channel_out += mlps[idx][-1]
self.SA_modules.append(
pointnet2_modules.PointnetSAModuleMSG(
npoint=self.model_cfg.SA_CONFIG.NPOINTS[k],
radii=self.model_cfg.SA_CONFIG.RADIUS[k],
nsamples=self.model_cfg.SA_CONFIG.NSAMPLE[k],
mlps=mlps,
use_xyz=self.model_cfg.SA_CONFIG.get('USE_XYZ', True),
)
)
skip_channel_list.append(channel_out)
channel_in = channel_out
self.FP_modules = nn.ModuleList()
for k in range(self.model_cfg.FP_MLPS.__len__()):
pre_channel = self.model_cfg.FP_MLPS[k + 1][-1] if k + 1 < len(self.model_cfg.FP_MLPS) else channel_out
self.FP_modules.append(
pointnet2_modules.PointnetFPModule(
mlp=[pre_channel + skip_channel_list[k]] + self.model_cfg.FP_MLPS[k]
)
)
self.num_point_features = self.model_cfg.FP_MLPS[0][-1]
def break_up_pc(self, pc):
batch_idx = pc[:, 0]
xyz = pc[:, 1:4].contiguous()
features = (pc[:, 4:].contiguous() if pc.size(-1) > 4 else None)
return batch_idx, xyz, features
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size: int
vfe_features: (num_voxels, C)
points: (num_points, 4 + C), [batch_idx, x, y, z, ...]
Returns:
batch_dict:
encoded_spconv_tensor: sparse tensor
point_features: (N, C)
"""
batch_size = batch_dict['batch_size']
points = batch_dict['points']
# print("points size: ", points.shape, len(points[points[:, 0] == 0]), len(points[points[:, 0] == 1]))
batch_idx, xyz, features = self.break_up_pc(points)
# print("batch_size: ", batch_size)
xyz_batch_cnt = xyz.new_zeros(batch_size).int()
for bs_idx in range(batch_size):
xyz_batch_cnt[bs_idx] = (batch_idx == bs_idx).sum()
# print("min: ", xyz_batch_cnt.min(), " max: ", xyz_batch_cnt.max())
assert xyz_batch_cnt.min() == xyz_batch_cnt.max()
xyz = xyz.view(batch_size, -1, 3)
features = features.view(batch_size, -1, features.shape[-1]).permute(0, 2, 1).contiguous() if features is not None else None
l_xyz, l_features = [xyz], [features]
for i in range(len(self.SA_modules)):
li_xyz, li_features = self.SA_modules[i](l_xyz[i], l_features[i])
l_xyz.append(li_xyz)
l_features.append(li_features)
for i in range(-1, -(len(self.FP_modules) + 1), -1):
l_features[i - 1] = self.FP_modules[i](
l_xyz[i - 1], l_xyz[i], l_features[i - 1], l_features[i]
) # (B, C, N)
point_features = l_features[0].permute(0, 2, 1).contiguous() # (B, N, C)
batch_dict['point_features'] = point_features.view(-1, point_features.shape[-1])
batch_dict['point_coords'] = torch.cat((batch_idx[:, None].float(), l_xyz[0].view(-1, 3)), dim=1)
return batch_dict
-
改写__init__
这一块主要核对下配置参数能不能对得上,这里我没有做修改 -
改写forward
把data_dict替换,我这里替换成xyz和特征feature,当然也可以按照自己喜欢直接用xyz+feature。
def forward(self, l_xyz, l_features ):
for i in range(len(self.SA_modules)):
li_xyz, li_features = self.SA_modules[i](l_xyz[i], l_features[i])
l_xyz.append(li_xyz)
l_features.append(li_features)
for i in range(-1, -(len(self.FP_modules) + 1), -1):
l_features[i - 1] = self.FP_modules[i](
l_xyz[i - 1], l_xyz[i], l_features[i - 1], l_features[i]
) # (B, C, N)
point_features = l_features[0].permute(0, 2, 1).contiguous() # (B, N, C)
batch_dict['point_features'] = point_features.view(-1, point_features.shape[-1])
batch_dict['point_coords'] = torch.cat((batch_idx[:, None].float(), l_xyz[0].view(-1, 3)), dim=1)
return batch_dict
- 模型加载
将原先的权重导入到pointnet2MSG中,大体流程是加载权重,然后找出pointnet2MSG对应的权重,再将其赋给pointnet2MSGExport。
checkpoint = torch.load(ckpt_path, map_location='cuda')
dicts = {}
for key in checkpoint['model_state'].keys():
if "backbone3d" in key:
dicts[key[12:]] = checkpoint['model_state'][key] # remove prefix "vfe."
pointnet2MSGExport.load_state_dict(dicts)
四、模型导出
在导出之前还需要进行一个验证就是对比网络修改之后输入输出的值是否能对上,最快的方式是采用同一个输入数据,一个输入到原始模型中,经过pointnet2MSG后将输出值打印出来,然后再把数据输入到pointNet2MSGExport,看两边输出是否一致,如果一致就可以导出了。
直接调用torch.onnx.export进行导出,当然这里面可能会遇到一些不支持的算子,这一块可以参考https://zhuanlan.zhihu.com/p/673603436
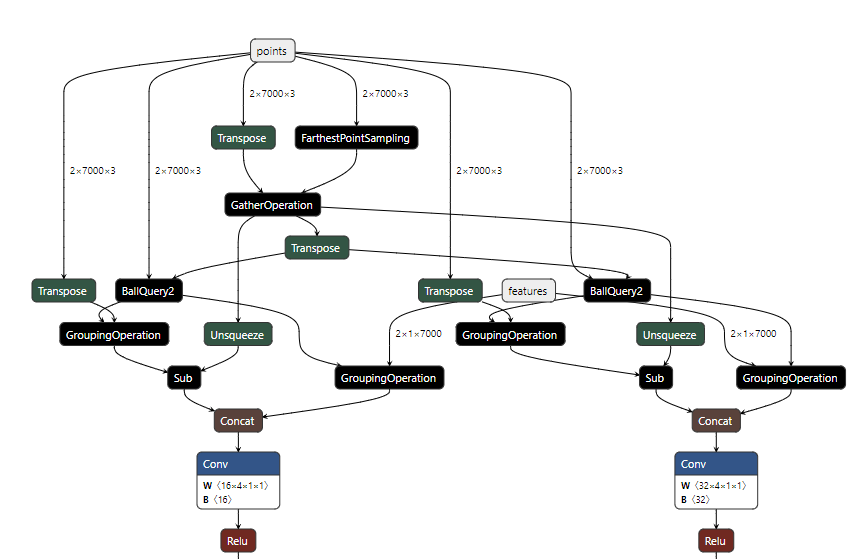
这个是我这边的导出结果,还可以进一步调用onnx_simplify进行简化。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端