

深度学习3D分割综述文献
前面介绍了3D目标检测的一些综述文献,这一篇接着介绍两篇3D分割的综述文献。第一篇是23年的《Deep Learning Based 3D Segmentation: A Survey》,第二篇是19年的《Deep Learning for 3D Point Clouds: A Survey》。第二篇主要是点云方面的文章,第一篇更加广泛全面,这里重点介绍第一篇。
一、《Deep Learning Based 3D Segmentation: A Survey》
PDF: https://arxiv.org/pdf/2103.05423
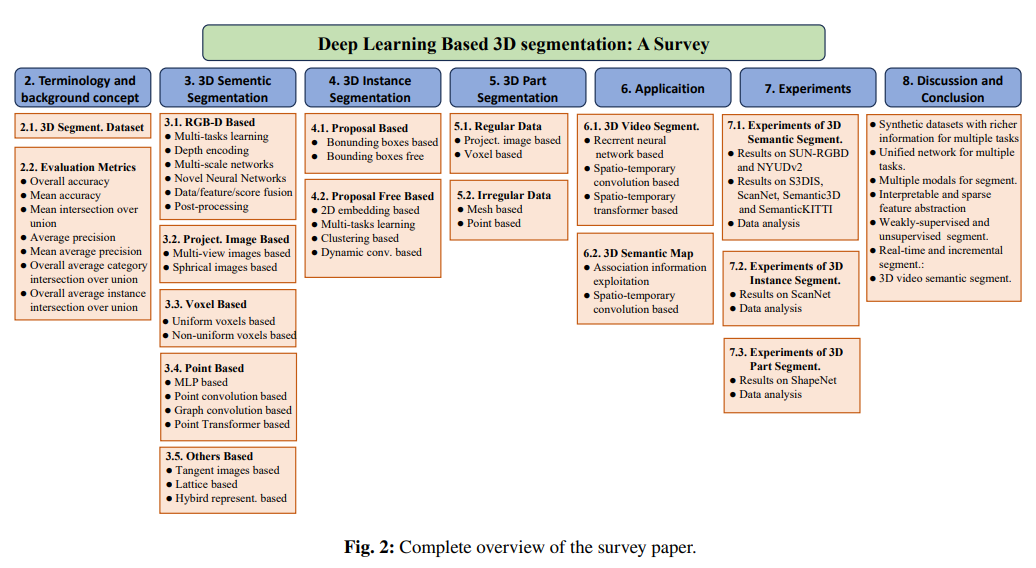
覆盖180篇文章,前面章节介绍了常用的数据集以及评价指标,然后从语义分割、实例分割和部件分割三部分展开,分别给出了对应的文献以及关键贡献点。

1.1 常用的公开数据集:
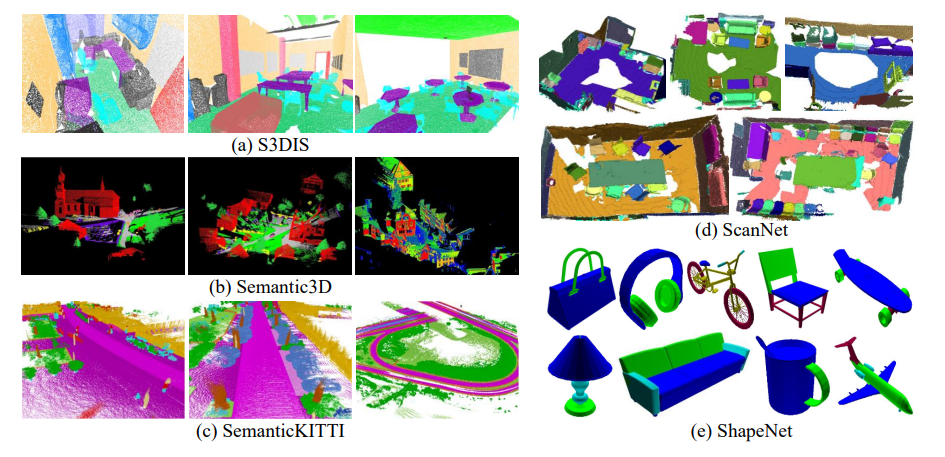
-
S3DIS
在这个数据集中,使用Matterport扫描仪在没有任何手动干预的情况下获得了完整的点云。该数据集由271个房间组成,属于来自3个不同建筑的6个大型室内场景(总面积6020平方米)。这些区域主要包括办公室、教育和展览空间以及会议室等。 -
Semantic3D
由静态地面激光扫描仪采集的总共约40亿个3D点组成,在真实世界的3D空间中覆盖160×240×30米。点云分为8类(如城市和农村),包含三维坐标、RGB信息和强度。与2D注释策略不同,3D数据标记很容易受到过度分割的影响,其中每个点都被单独分配给一个类标签。 -
SemanticKITTI
是一个大型户外数据集,包含28个类的去尾逐点注释。基于KITTI视觉基准Geiger、Lenz和Urtasun(2012),SemanticKITTI包含该基准的所有22个序列的注释,这些序列由43K扫描组成。此外,数据集包含旋转激光传感器的完整水平360视场的标签。 -
ScanNet
数据集对于场景理解的研究尤其有价值,因为它的注释包含估计的校准参数、相机姿态、3D表面重建、纹理网格、密集对象级语义分割和CAD模型。该数据集包括对真实世界环境的带注释的RGB-D扫描。在707个不同的地方采集的1513次扫描中有250万张RGB-D图像。在RGB-D图像处理之后,使用Amazon Mechanical Turk执行注释人类智能任务。 -
ShapeNet
数据集提供了一种新的可扩展方法,用于对大量三维形状集合进行高效准确的几何标注。新的技术创新明确地建模并减少了注释工作的人力成本。研究人员在ShapeNetCore中创建了形状类别中31963个模型的详细逐点标记,并将基于特征的分类器、点对点相关性和形状与形状的相似性结合到形状网络上的单个CRF优化中。
1.2 常用的度量指标
-
3D语义分割度量指标
对于3D语义分割常用的有:Overall Accuracy (OAcc), mean class Accuracy (mAcc) and mean class Intersection over Union (mIoU)。
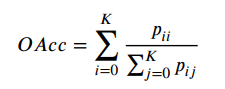
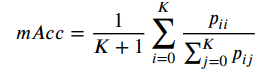
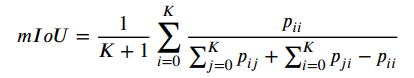
-
3D实例分割度量指标
对于3D实例分割常用的有:Average Precision (AP)和 mean class Average Precision (mAP) 。
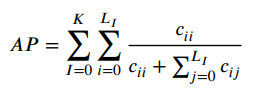
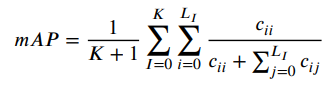
-
3D部件分割度量指标
对于3D部件分割常用的度量指标有:overall average category Intersection over Union () 和 overall average instance Intersection over Union ()
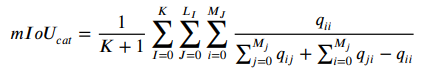
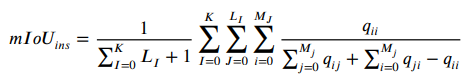
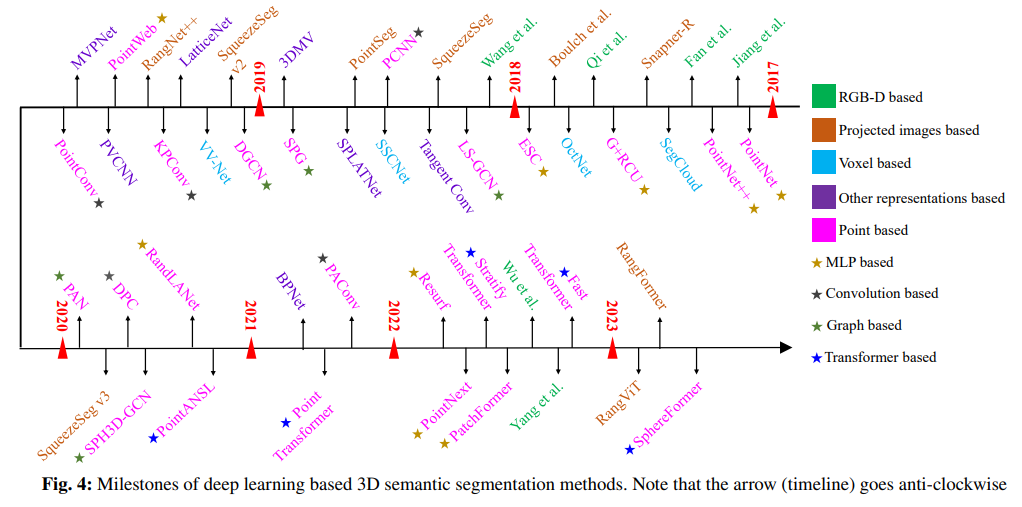
1.3 语义分割
语义分割这一块文中从输入数据出发,将其分为:RGB-D数据、投影成图片、体素数据、点云数据以及其他五部分,下图是17年至23年一些相关文献。
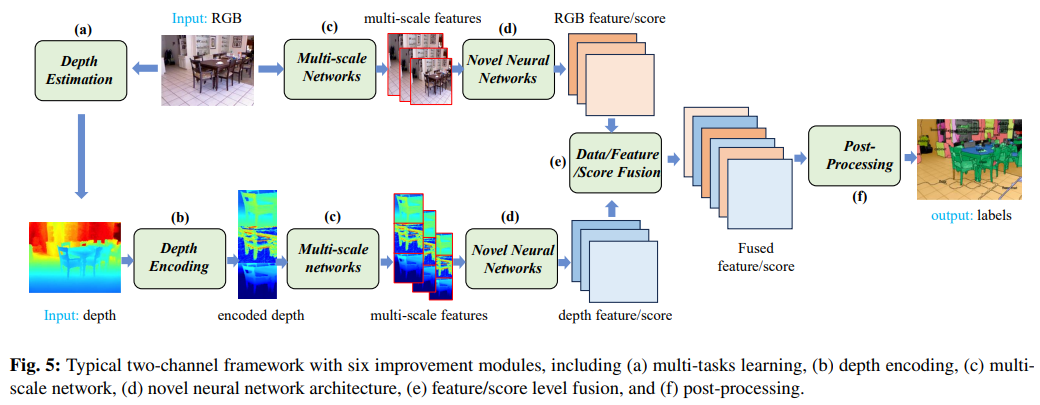
1.3.1 RGB-D数据
如下图所示,RGB-D数据检测框架大体如下:
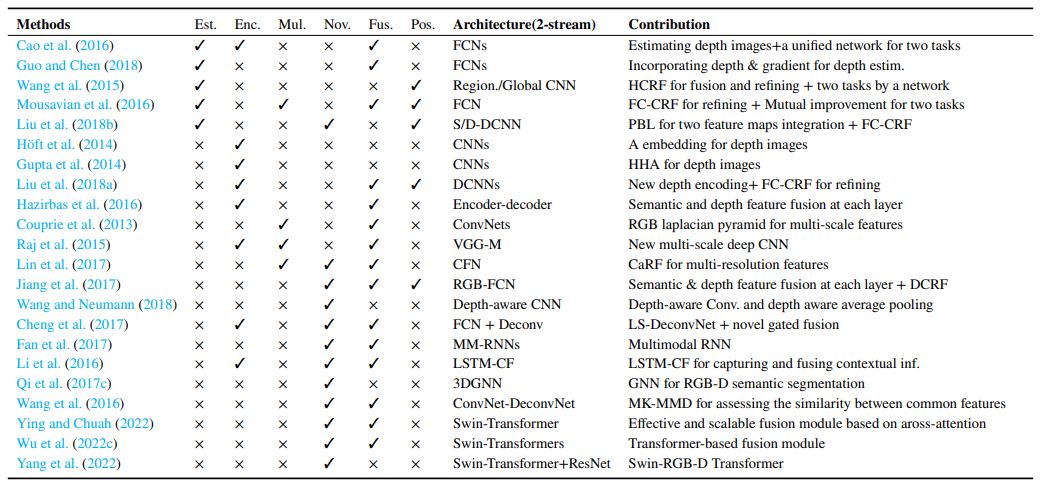
下表是相应文献及其主要贡献
1.3.2 投影成图片处理
有的文章直接把3D目标投影成图片进行处理
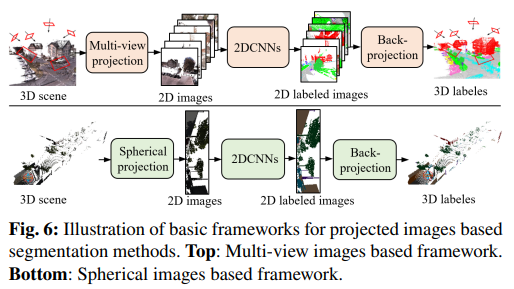
下表是相应文献及其主要贡献
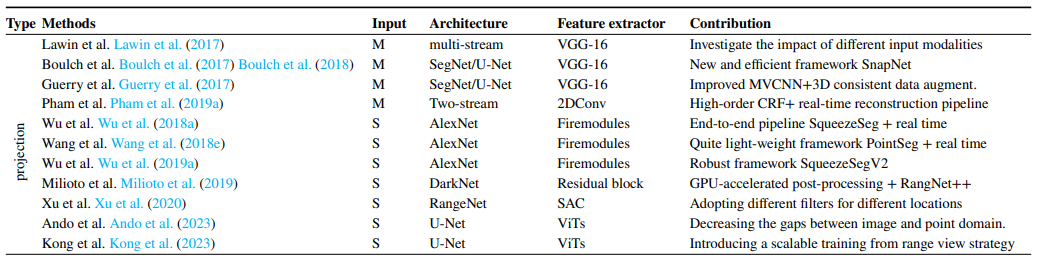
1.3.3 基于体素数据
下表是基于体素进行处理的相应文献及其主要贡献
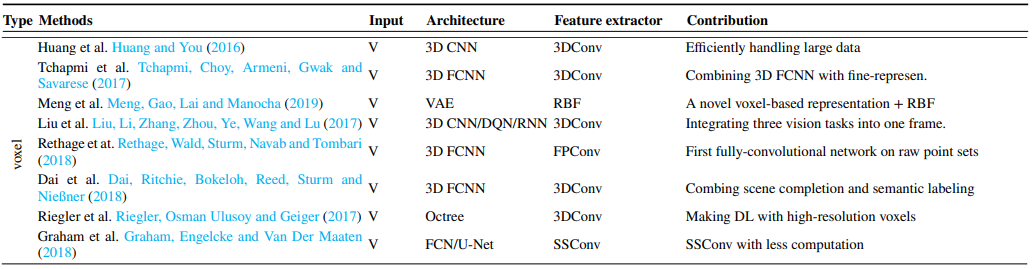
1.3.4 基于点云数据
下表是基于点云进行处理的相应文献及其主要贡献
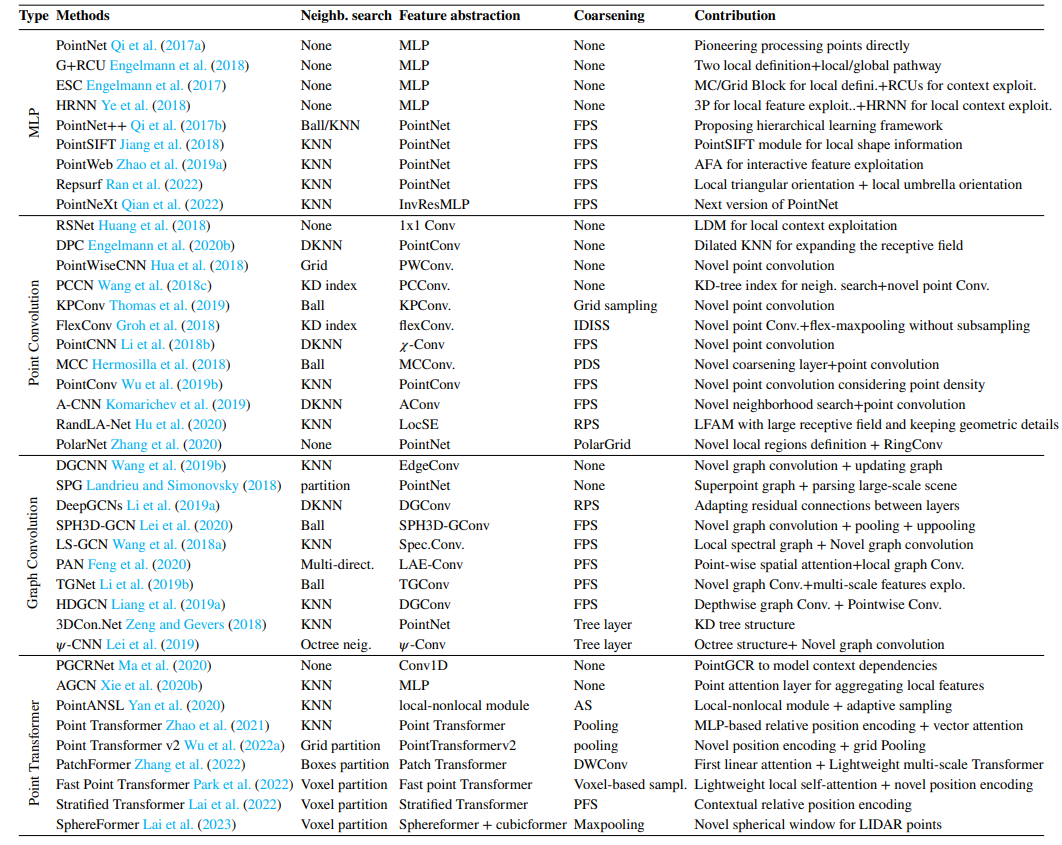
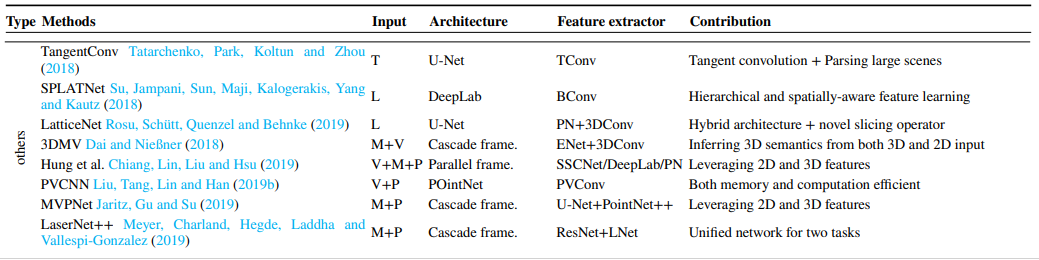
1.3.5 其他
还有一些其他数据和方法,这里将主要文献及其贡献都归纳在下表。
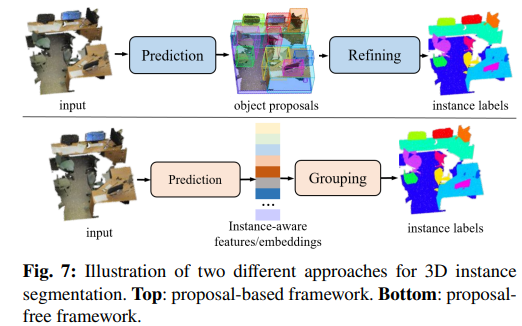
1.4 实例分割
作者从基于获选框和没有获选框这个点出发,将实例分割文献划分成两大类,类似于2D里面的Anchor-based和Anchor-free。
1.4.1 基于候选框
基于候选框的3D实例分割方法归纳如下:

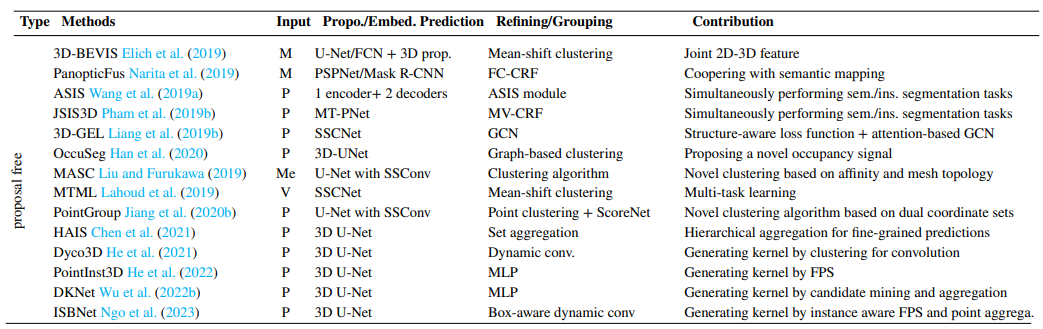
1.4.2 没有候选框
没有获选框的方法相比于基于候选框的方法精度相对较差,但速度通常会快一些,主要方法和贡献点如下:
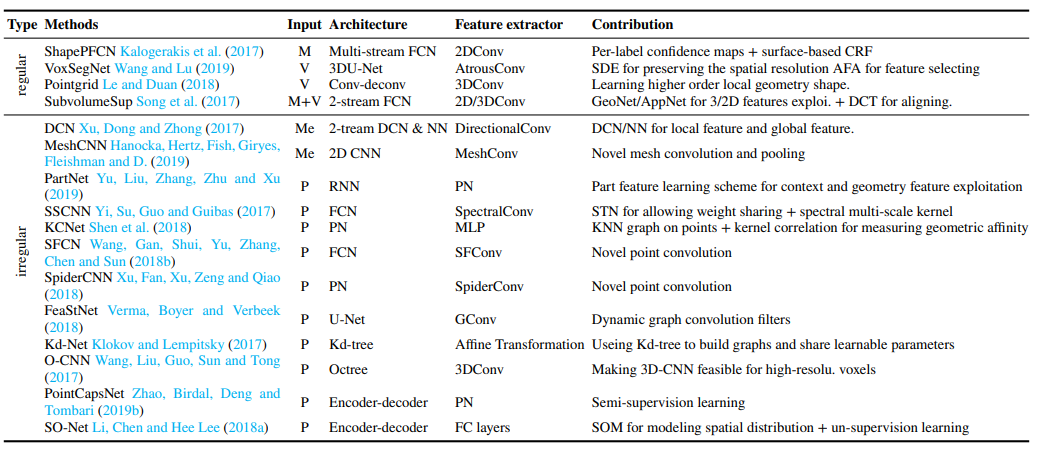
1.5 部件分割
部件分割这一块,作者依据数据的规则性将其分为规则数据和不规则数据两部分。
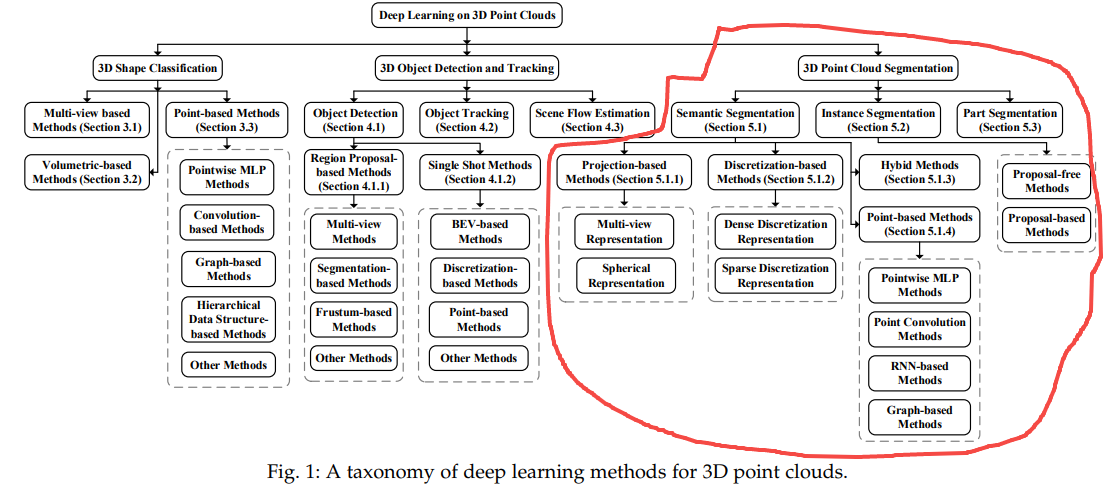
二、《Deep Learning for 3D Point Clouds: A Survey》
PDF: https://arxiv.org/abs/1912.12033
这篇文章前面也提到过,主要是针对点云数据处理,以点云数据展开,同样分为语义分割、实例分割和部件分割三大部分内容。
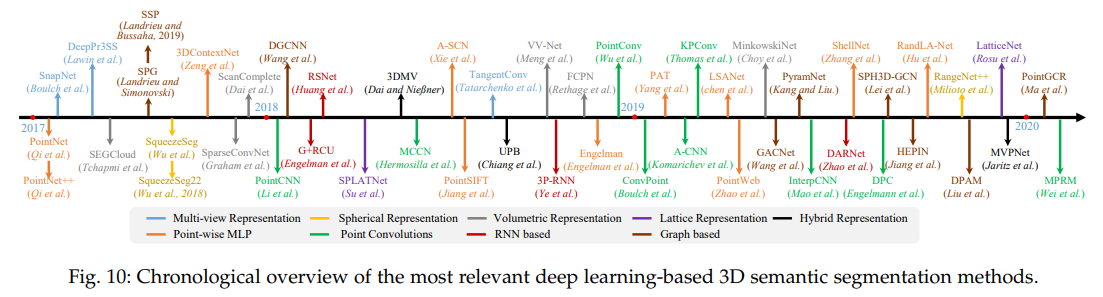
2.1 语义分割
主要包含2017年到2020年的文献
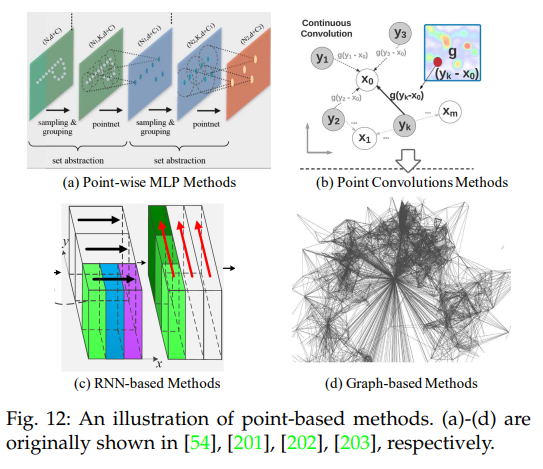
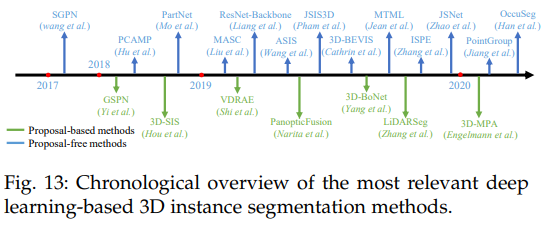
2.2 实例分割


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!