
RangeDet
PDF: RangeDet: In Defense of Range View for LiDAR-based 3D Object Detection
CODE: https://github.com/TuSimple/RangeDet
一、大体内容
RangeDet是一个Anchor-free的单阶段3D目标检测网络,其输入数据不是Voxel和Point,而是Range Image。这三种数据区别如下图所示。
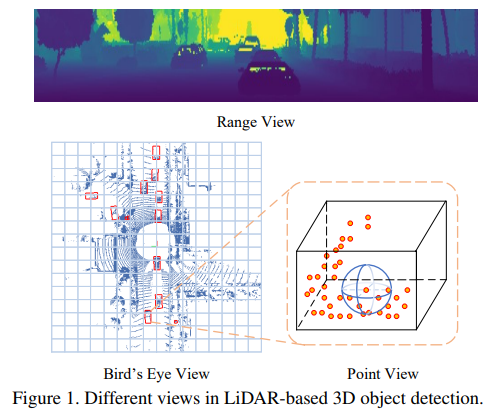
作者对比分析后认为基于Range Image的方法不如基于Voxel、Point方法的性能的主要原因在于(1) 图片中物体尺度变化带来的影响(2)图像坐标和实际3D坐标表示不一致。因此设计了如下图所示的RangeDet来解决这些问题,并在Waymo Open数据集(WOD)上取得了很好的效果。
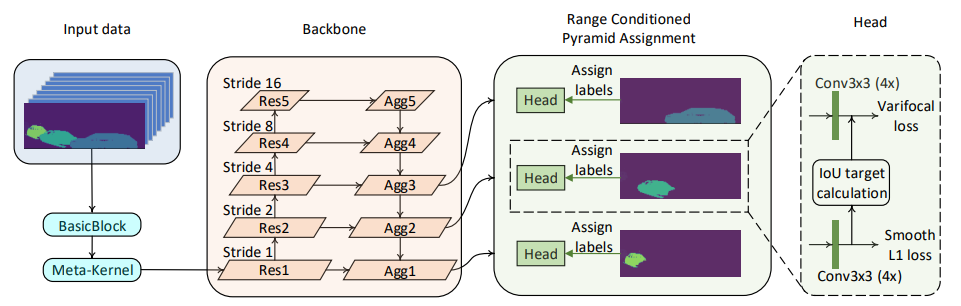
RangeDet将输入的Range Image作为8通道的2D图片,8个通道分别为距离(range),反射率(Intensity),伸长率(Elongation),x,y,z,方位角(Azimuth)和倾角(Inclination)。将这个2D图片通过一个BasicBlock(何凯明大神在ResNet种提出),不过这个BasicBlock中的卷积核被替换成了作者提出的Meta-Kernel(可以保留更多的几何信息),再输入到FPN(特征金字塔网络)的Backbone中,并且经过上采样在不同尺度上聚合特征,得到了不同尺度下的特征图。并经过Range Conditioned Pyramid Assignment,其根据距离范围的远近,将label分配到不同的特征图中。最后,分别使用4个3x3卷积构成分类和回归的检测分支,并使用了Varifocal loss 和 Smooth L1 Loss 作为损失函数。
二、贡献点
作者认为在Range Image上进行3D目标检测主要有三大挑战,并针对这三大挑战给出了对应的解决方法,这些就是该文的主要贡献点。
- 相比于Voxel、Point方法的稀疏特征问题,Range Image面对的是尺度变化带来的影响,因此提出了Range Conditioned Pyramid来解决多尺度问题
- 在以前一些基于Range Image的方法中,没有充分利用2D图的结构信息,可以利用Range Image的紧凑性在没有巨大计算负担的情况下采用高分辨率输出,为了充分利用Range View的紧凑性,作者引入加权的Non-Maximum Suppression(NMS)
- 在2D空间上做检测,而输出却是3D空间,这种不一致导致了几何信息的损失,作者提出采用Meta-Kernel来替代传统卷积核,进而保留更多的几何特征。
三、细节
3.1 Range Image介绍
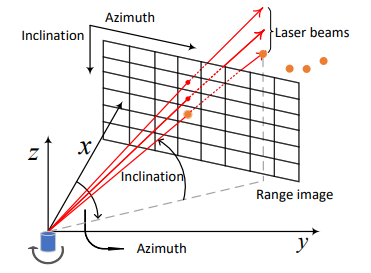
如上图所示一个扫描周期内具有m个光束和n次测量的LiDAR,会形成一个m x n的矩阵,称为Range Image,每一列共享一个方位角,每一行共享一个倾角。 Range Image的每个像素值至少包含距离r,方位角和倾角,依据这三个值可以得到球面坐标系,进而得到笛卡尔坐标。其他还会包含激光脉冲的幅度和其他辅助信息。
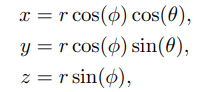
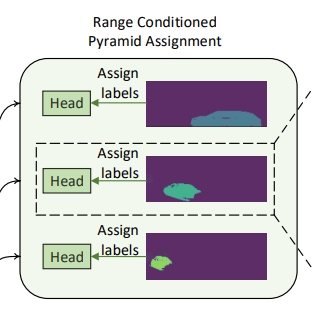
3.2 带距离约束的特征金字塔(Range Conditioned Pyramid)
其目的是将近距离的lable分配到更加局部的特征图上,而将远距离的lable分别配到比较全局的特征图。在原始FPN中,根据其在2D图像中的面积指定边界框,这种方式忽略了2D图像和3D空间的坐标差异,如较近的客车可能和较远处的卡车有相似的区域,但扫描模式有很大不同,所以这里将距离作为判断依据,根据距离范围的远近,将label分配到不同的特征图中进行处理。
3.3 Meta-Kernel
一个Range图像中两个相邻的像素点,在真实的空间中实际距离却有可能很远,标准卷积无法学习到这一信息的差异,因此作者提出了Meta-Kernel,将其作为一种新的卷积核。
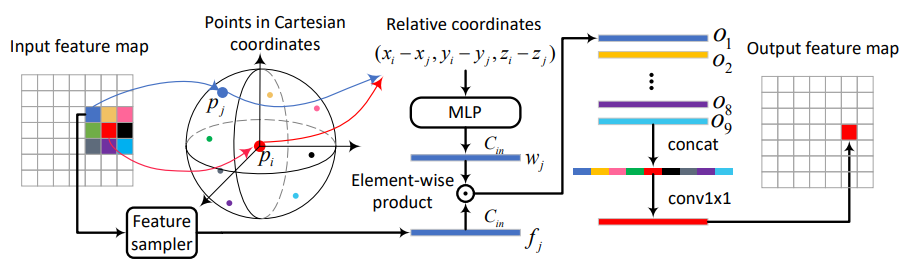
普通卷积可以分为采样、权重获取、相乘、聚合四部分,Meta-Kernel如上图所示,采样部分和普通卷积类似,都是一定范围内像素点(如3 x 3),但其他几个有点区别。
- 权重获取
Image上的像素点先转换到笛卡尔坐标系,当前点(红色)作为坐标中心,计算出各采样点的相对坐标,然后经过一个MLP网络得到对应的权重 - 乘法
这里没有采用矩阵乘法,而是采用的点乘,也就是原始特征乘上对应的权重 - 聚合
经过点乘后的特征向量进行拼接,再经过一个1x1的卷积得到当前点的特征
3.4 加权非极大值抑制(Weighted Non-Maximum Suppression)
加权非极大值抑制最早在https://arxiv.org/abs/1505.01749中提出,其与传统的非极大值抑制相比,是在进行矩形框剔除的过程中,并未将那些与当前矩形框IOU大于阈值,且类别相同的框直接剔除,而是根据网络预测的置信度进行加权,得到新的矩形框,把该矩形框作为最终预测的矩形框,再将那些框剔除。
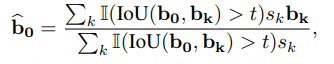
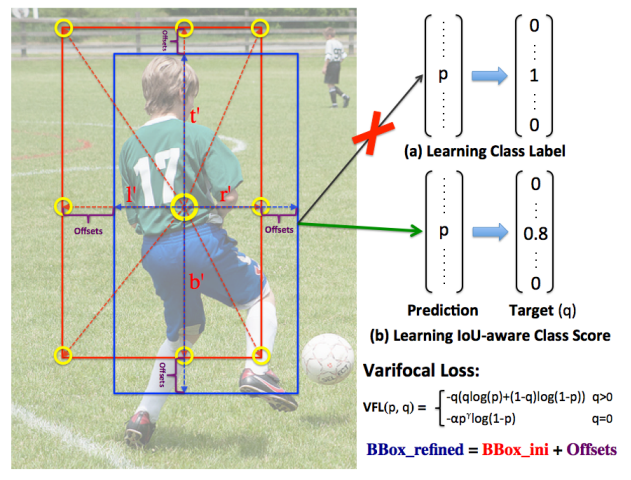
3.5 IoU 预测分支
这里引用了VarifocalNet提出的varifocal loss来预测类别置信度,主要思想是没有直接去预测边框的类别标签,而是通过学习IOU-aware分类得分(IACS)来作为检测的得分结果。
3.6 回归分支
用于回归出最终的3D目标框信息,参照LaserNet,作了一个坐标变换。
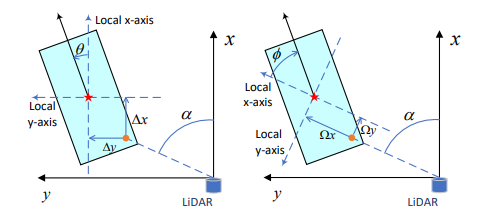
主要是把信息按照下式转换为格式,然后在采用SmoothL1回归损失
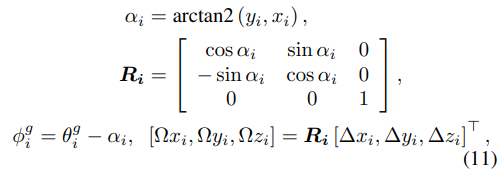
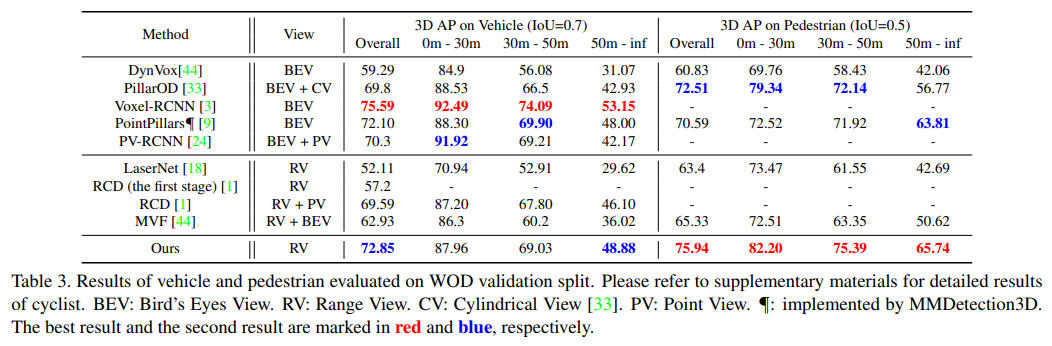
四、效果


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端