

PV-RCNN
PDF:https://arxiv.org/pdf/1912.13192.pdf
CODE: https://github.com/sshaoshuai/PV-RCNN
一、大体内容
前面介绍了基于Point的3D目标检测网络(PointRCNN、3DSSD)以及基于voxel的3D目标检测网络(VoxelNet、SECOND、PointPillar),基于Voxel的方法比较高效,其多尺度的特征可以生成较高质量的候选框,但是在点云转换成Voxel时会丢失精度,基于Point的方法精度高但是有较高的计算成本,因此作者结合基于Point和基于Voxel方法的优势,提出新的两阶段目标检测框架PV-RCNN。
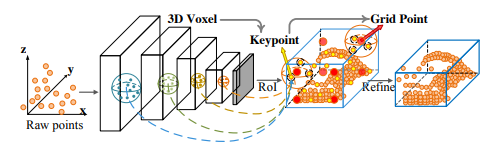
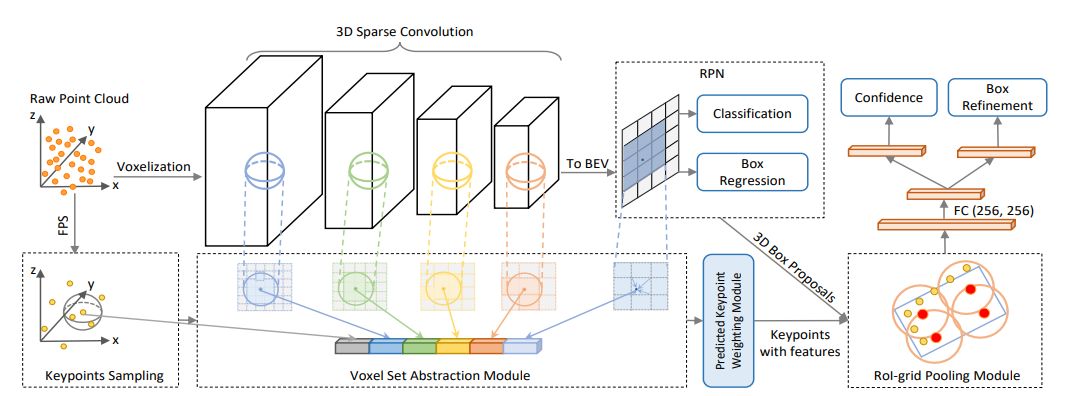
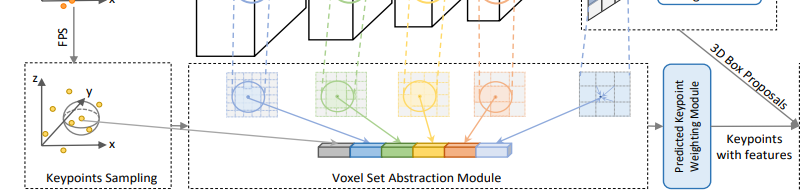
第一阶段先将原始点云转换为Voxel,在下采样的同时借助稀疏卷积提取得到Voxel不同尺度的特征,最后的特征层投影到鸟瞰图视角,使用Anchor-Based的方法预测候选框和类别,另外一个分支对原始点云按照FPS进行采样,并通过Voxel-to-keypoint提取不同阶段的Voxel特征并将其作为这些关键点的多尺度特征.
第二阶段是将3D获选框和关键点特征进行进行融合,这里作者提出了一个新的Rol-Grid Pooling模块来完成特征融合,之后再经过FC层进行特征提取,最后分别输入到框回归分支以及置信度分支。
从下图可以看出来,图的上面一块主要是基于Voxel进行特征提取,其主要特点就是下方的关键点分支,包括如何给关键点分配多尺度Voxel特征,如何和3D候选框进行特征融合。
二、贡献点
- 提出PV-RCNN框架,结合了基于Voxel和基于Point方法的优势,在KITTI数据集上取得了非常显著的效果,比之前的方法有较大的提升
- 提出Voxel-to-keypoint的编码方法,获取关键点的voxel特征,既保留了位置信息又拥有丰富的全局信息
- 提出Keypoint-to-grid RoI将3D候选框和对应的关键点特征进行融合,提升了目标检测算法的性能
三、细节
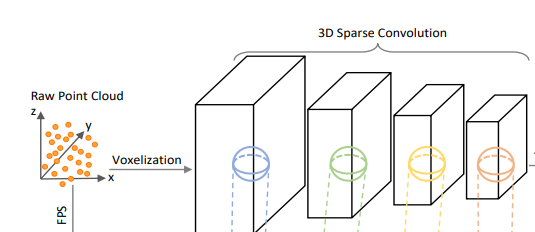
1. 体素化及特征提取
点云空间首先被划分成L * W * H的体素格子,非空体素的特征为内部所有点特征的均值。然后采用4组3 * 3 * 3的稀疏卷积对特征进行降采样,分别得到1X,2X,4X, 8X的特征,这里面稀疏卷积原文中没有提,可以参考SECOND里面的稀疏卷积,主要目的是用来加速模型推理过程,并且可以减少内存占用。其大体思想先像普通卷积一样先扫描一遍,构建输入输出规则索引矩阵(这里不做具体计算,只记录输入和输出索引对应的关系),在真正做卷积时就可以跳过不需要计算的0元素,计算完成后再借助索引矩阵恢复至输出相应位置。
2. 候选框生成
8倍下采样的特征按照Z轴投影得到 的2D特征图,然后基于Anchor-based方法,每个类别的Anchor大小参照每个类别的平均大小,还有0和90度两个方向,共得到个Anchor,基于这些Anchor回归出3D候选框。
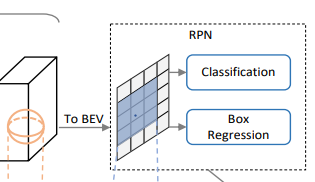
实验也表明这种候选框生成方式具有更好的效果。

3. 为什么要引入关键点
目前大多数精度高的工作都采用了two-stage框架,也就是需要优化(refine)。作者认为存在以下两个问题:
- 如果采用传统RoI Pooling的方式,经过8倍降采样后会使得分辨率很低,无法表示精确的位置;
- 即使可以上采样获得更大空间尺寸的特征图,特征图通常相当稀疏,RoIPooling/RoIAlign操作中常用的三线性或双线性插值只能从非常小的领域提取特征。因此,传统的池化方法将获得大部分为0的特征,浪费内存和计算资源。
有些直观的方法是直接聚合多尺度特征,然后输入到后续优化步骤,但是这种策略通常占用大量内存,所以作者引入了关键点,首先得到一些可以代表完整点云的关键点,然后将关键点的特征集成到后续框优化网格中进行处理,这样既节省内存也保留了丰富的特征。
4. Voxel-to-keypoint的编码
这一步的目的是把提取到的多尺度特征分配给少量的关键点,利用这个关键点特征让3D多尺度特征和后续候选框强化进行连接。
-
关键点采样
直接采用最远点采样方法,对于KITTI数据集实验采用的是2048个关键点,对于Waymo数据集选择的是4096个关键点。 -
Voxel Set Abstraction(VSA)模块
这个模块负责把多尺度特征分配给采样的关键点,下方公式其大体思路就是在每一尺度特征下,找出关键点一定范围内的Voxel,并记录这些voxel的特征,
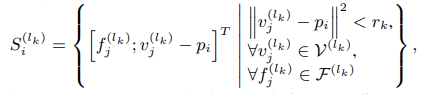
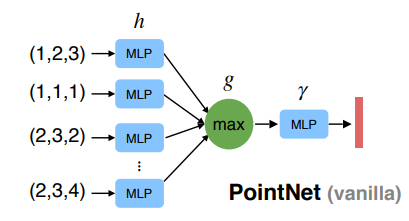
然后借助PointNet模块对这些voxel特征进行进一步提取,将其作为该尺度下这个关键点的特征。
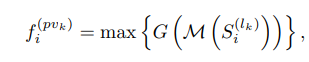
最后在将不同尺度的特征进行拼接,得到关键点的多尺度特征。
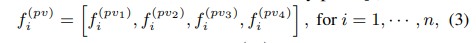
-
扩展的VSA模块
为了使得关键点特征更加丰富,利用PointNet模块在关键点上提取原始点云特征,可以弥补点云体素化带来的损失,进一步的在2D BEV特征图上采用双线性插值得到关键点投影到BEV上的特征,可以增大在z轴的感受野。
最终关键点的特征由原始点云特征、体素多尺度特征、鸟瞰图特征三部分组成:
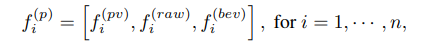
在实验阶段还给出了不同特征组合的效果对比。

-
预测关键点权重Predicted Keypoint Weighting(PKW)
前面提到关键点是通过FPS采样得到的,这里面可能有一些背景点,但背景点对于后续优化候选框是没有什么用的,因此这里作者设计了一个网络给不同的关键点赋予不同的权重,其目的是让前景点的权重更高。
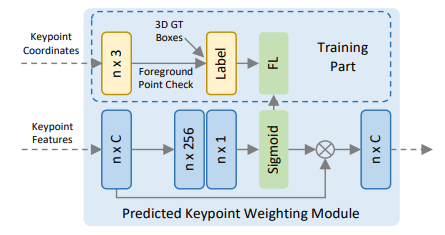
在训练阶段,其标签采用的是关键点是否在3D GT Box内部,然后采用Focal Loss损失函数预测得到一个权重系数,最后关键点的特征再乘上这个系数作为后续候选框优化。
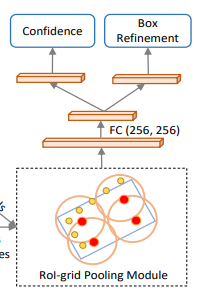
5. Keypoint-to-grid RoI
其目的是将3D候选框和对应的关键点特征进行融合,进而提升了目标检测算法的性能。
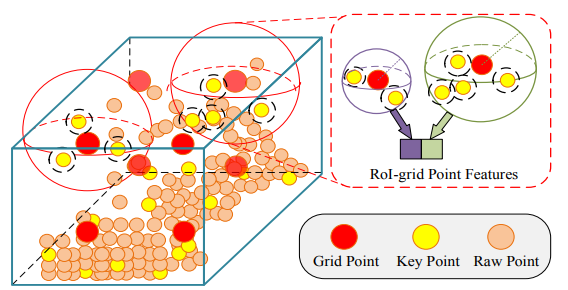
大体可以分为以下三步:
- 先将每个3D候选框按6 * 6 * 6划分成不同的网格,共216个格子。
- 确定每一个网格点一定邻域内的关键点,然后再用一个PointNet模块将特征整合为网格点的特征。
- 得到了所有的网格点(grid-point)的特征后,作者采用两层的感知机得到256维度的proposals的特征。
6. 预测分支
前面得到了每个3D候选框的特征后,经过两层MLP,然后再借助Box优化分支预测出框的大小、方向及位置信息,经过confidence分支预测出框的置信度。
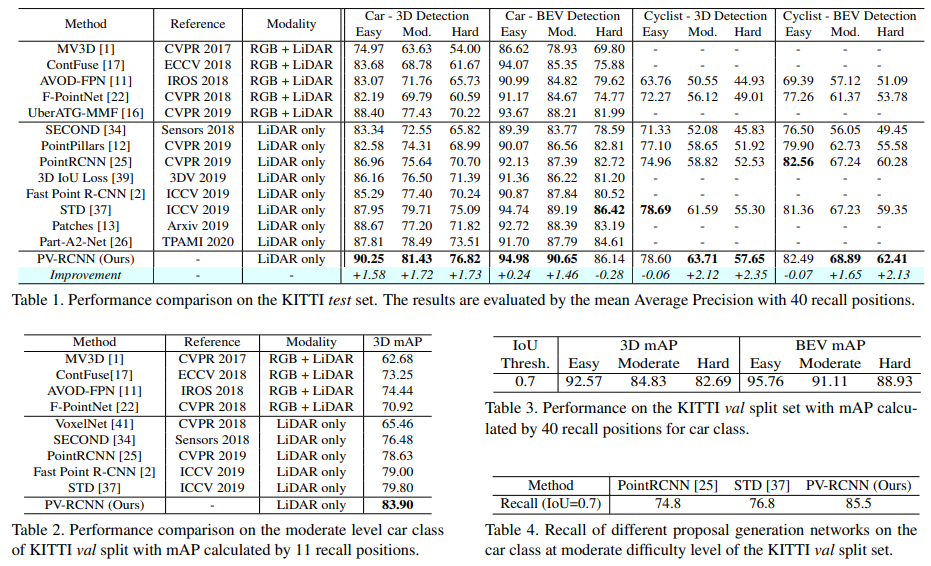
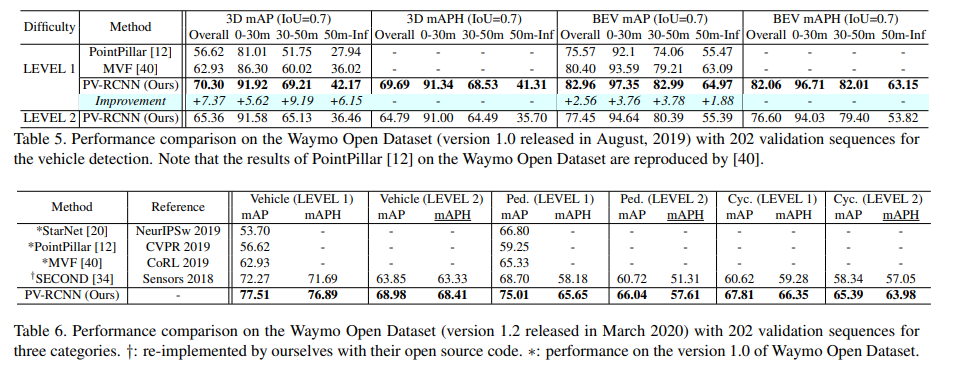
四、效果


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通