
3DSSD
PDF: https://arxiv.org/abs/2002.10187
CODE: https://github.com/dvlab-research/3DSSD
一、大体内容
3DSSD是基于点的单阶段3D目标检测器,其提出的动机主要是基于体素的方法(如VoxelNet、PointPillar)在转换体素的时候会丢失信息,而基于点的目标检测方法大都是两阶段方法(如:PointRCNN),其精度虽然高但是推理时间比较慢。
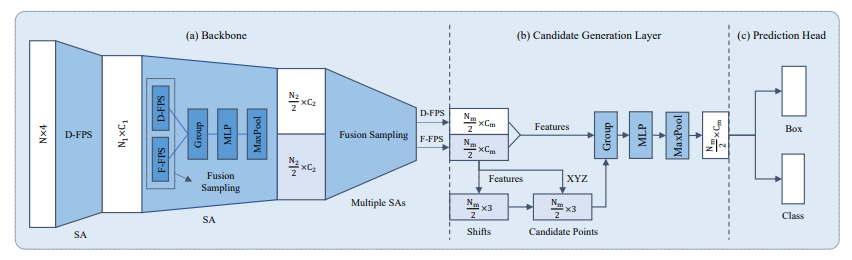
通过分析两阶段模型各部分的耗时情况,作者发现FP层和强化层耗时一班以上(SA层是特征提取必要的,不能省),因此本文的重点在于如何设计一个轻量的单阶段检测器,经过融合采样策略和CG层,3DSSD达到可以剔除FP层和强化层而精度影响不大的效果。

二、贡献点
- 设计了一个轻量有效的基于点的3D单阶段检测器(3DSSD),该检测框预测网络(包含CG层、回归分支、分类分支)去除了比较耗时的FP层。
- 提出一个新的采样策略,不仅采用了基于距离的最远点采样(D-FPS),还融合了基于语义特征的最远点采样(F-FPS),为分类和回归提供更丰富的信息。
- 3DSSD在KITTI和nuScenes数据集上单阶段检测算法中取得了很好的效果仅需要38ms。
三、细节
1. F-FPS
先回顾下PointNet里面提到的FPS,他是随机选一个样本点,然后在选择与该样本点距离最远的一个点作为下一个样本点,依此循环直到满足采样点数量要求,这里面选择的依据是点于点之间空间坐标的欧式距离,也就是这篇论文中提到的D-FPS。
但点云数据比较稀疏,有些物体前景点本身就比较少,按D-FPS采样会丢失很多前景点,为了改进这一情况,作者引入了Feature-FPS(F-FPS),也就是把选点的依据由空间坐标的欧式距离更改为特征之间的距离。
输入点云经过SA层后每个点都会得到一个特征向量,F-FPS基于这些特征之间的距离进行采样。
2. 提出的采样策略怎么融合D-FPS和F-FPS
F-FPS采样可以保留大都数前景点,但由于采样点数量的限制,很多背景点都被过滤掉(背景点语义特征与前景点语义特征相隔较大),这虽然对回归检测框有好处,但是背景点太少的话对分类任务不太友好(样本不均衡)。基于这一点考虑,作者将D-FPS和F-FPS进行融合,以保证有足够的前景点用于回归,以及足够的背景点用于分类,最终的采样点由D-FPS和F-FPS组成,即:
,其中用于控制比例。
通过实验对比分析发现取1时其效果最佳,也就是说D-FPS和F-FPS采样各占一半。
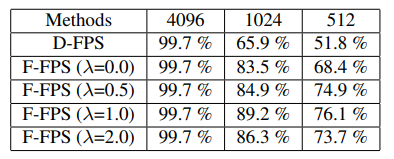
这样图中融合采样那里输出就好理解了。
3. 框预测网络的CG层
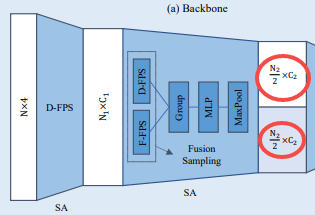
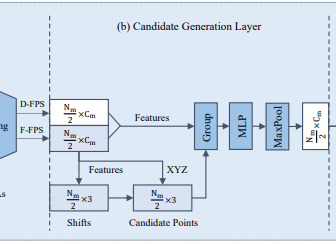
经过一系列的SA层以及F-FPS和D-FPS的融合(BackBone),得到点的特征用于最终的预测,通常的SA层包含中心点的选择、领域点的提取以及语义特征生成三大块,为了减少计算量并最大限度保留特征信息,作者提出了SA层的变体CG网络,在BackBone之后接入CG层,最后再用于预测。
-
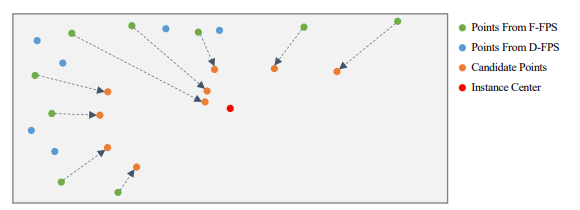
中心点提取
由于D-FPS得到的背景点较多且对框回归没有用处,因此只从F-FPS中选择初始中心点,然后在监督学习的情况下使其向物体中心偏移,称偏移后的点为候选点,然后将这些候选点作为CG层的中心点。
-
领域点提取
和SA层类似,找到候选点周围一定范围内的采样点(D-FPS和F-FPS所有的点)作为领域点(Group操作) -
特征提取
还是采用简单的PointNet结构,即:一个MLP加MaxPool操作,最后才输入到检测头用于回归和分类。
4. Anchor-free的回归分支
这里没有采用Anchor-based,主要是考虑到需要设计多尺度、多朝向的anchor,这在nuScenes等数据集上需要设计几十个Anchor,比较复杂。
对于回归分支需要回归的主要有中心点坐标、大小以及偏转角。
- 中心点
候选点到标注中心的距离 - 大小
候选点预测到的框大小与对应的Gt bbox的距离 - 偏转角
每个候选点预测的角度与实例Gt bbox的转角的偏移,这里引入了bin+res的形式进行回归(这个可参考上一篇讲解的PointRCNN,就是把角度划分成不同的区域,然后引入分类和回归损失)
5. 中心域分配策略
在训练过程中,需要给每一个候选点分配一个标签,在2D检测器中通常采用IOU,设定一个阈值,超过某个阈值的作为正样本,或者是采样掩膜的方式来给每个像素分配一个标签。这里借鉴FCOS中心域的思想来给每个候选点分配一个标签,其可以产生连续的中心域标签,可以更好的进行框回归。
- 什么是中心域
中心域首先在FCOS中提到,如下图简单理解就是有点像高斯热力图,离中心点越近其值越接近于1,越远则越接近于0。
 ,
,
其度量方式如下
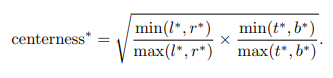
- 扩展到三维
将上面的度量方式扩展到3D,即考虑前后左右上下6个维度。
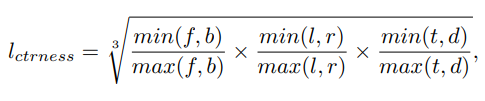
首先判断候选点在哪个真实框里面,得到,其值非0即1。最后的分类标签是两者的乘积。
6. 损失函数
损失函数包含分类、回归和偏移损失三部分。
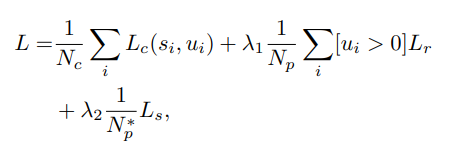
其中分别表示候选点和前景点以及从F-FPS得到的前景点数量,分别表示分类、回归、偏移损失,表示第i个候选点预测得分和中心域类别。
(1)分类损失
分类损失采用的交叉熵损失对候选点进行度量
(2)回归损失
回归损失包含中心点距离损失、框大小损失、角度损失和角点位置损失四块。
其中中心点距离损失和框大小损失采用的Smooth_L1损失函数。
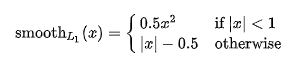
角度损失引入了bin + res策略,所以其损失函数如下:
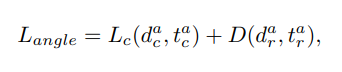
分别表示预测角度类别及残差值,分别表示真实的角度类别及残差值。
角点损失
计算预测框的8个角点与真实角点之间的距离损失。
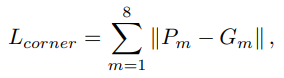
(3)偏移损失
偏移损失应用在候选点生成(CG层中)的监督任务中,作者利用了smooth-l1损失函数来计算,用于度量预测的偏移值与候选点到真实中心点实际距离的差异。
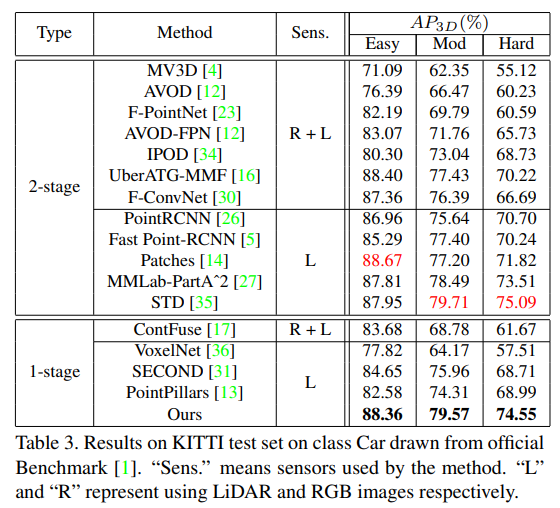
四、效果
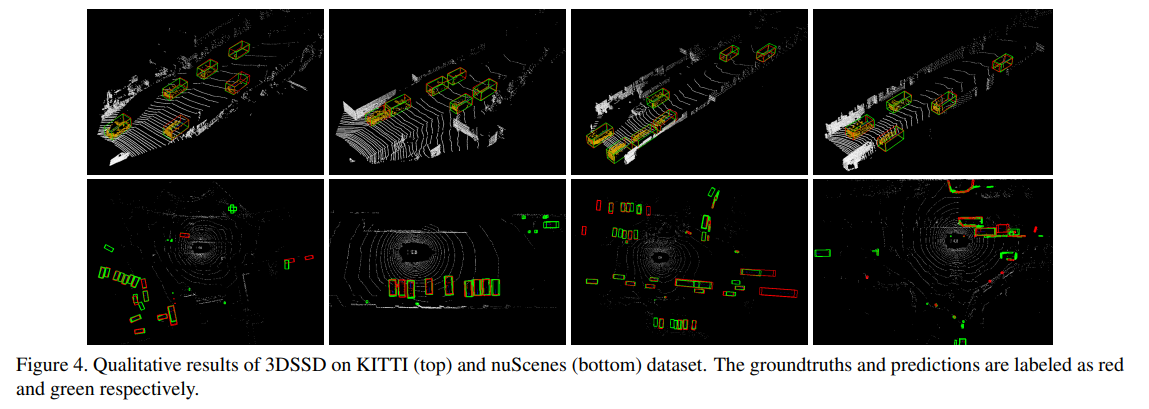
1. 实验效果
实验部分展示了其在KITTI以及nuScenes数据集上的效果。

-
CG层偏移的影响
CG层中带有偏移的效果更好

-
融合采样的实验结果
融合采样比纯D-FPS效果要好

2. 推理时间
推理时间在基于点的目标检测方法中处于领先地位



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端