

PointRCNN
PDF: https://arxiv.org/pdf/1812.04244.pdf
CODE: https://github.com/sshaoshuai/PointRCNN?tab=readme-ov-file
一、大体内容
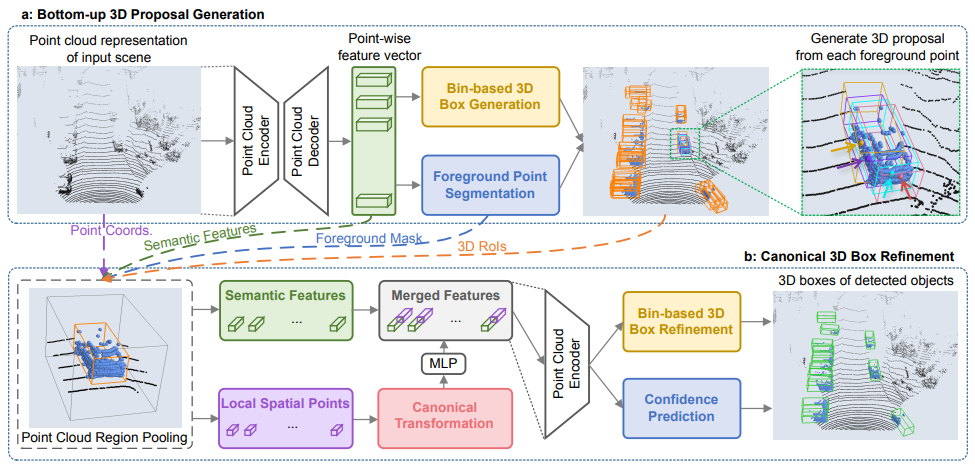
PointRCNN和前面提到的VoxelNet、SECOND、PointPillar一阶段模型不同,如下图所示PointRCNN将目标检测任务分为两个阶段,第一个阶段借助点云分割得到前景点以及对应的候选目标框,第二阶段再对候选目标框进行优化调整。
二、贡献点
- 提出了一种新的基于自下而上的点云的三维候选框生成算法,该算法通过将点云分割为前景对象和背景来生成少量高质量的三维候选框。从分割中学习到的点表示不仅有利于候选框的生成,而且有助于后期的框细化。
- 提出3D边界框优化方法,对前面得到的候选框进行坐标细化。
- PointRCNN仅使用点云作为输入,并在KITTI 3D数据集上排名第一(截至2018年11月16日)。
三、细节
1、第一阶段采用的什么分割算法
采用前面介绍过的PointNet++网络作为BackBone,提取出每个点的特征向量。为后续前景点分割以及候选框生成提供基础特征。
2、第一阶段如何得到前景点(Foreground Point Segmentation)
在前面PointNet++提取的基础特征上,再借助一个分割分支估计出前景点。分割分支在训练时采用真实3D框中的点作为前景点,考虑到点云数据中前景点和背景点数量差距较大,所以分割分支的损失函数采用Focal Loss。
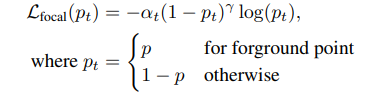
文中和的值设为0.25和2。
3、第一阶段如何生成3D候选框(Bin-based 3D Box Generation)
在前面PointNet++提取的基础特征上,借助一个回归分支来得到3D候选框。回归分支在训练时只回归前景点的3D包围框位置,这里还引入基于Bin的回归损失来约束候选框的生成,最后再对每个前景点的3D框进行Iou计算,以过滤重叠量较大的候选框(阈值文中给定的是0.8,在训练阶段保留300个候选框,在测试阶段仅保留100个)。
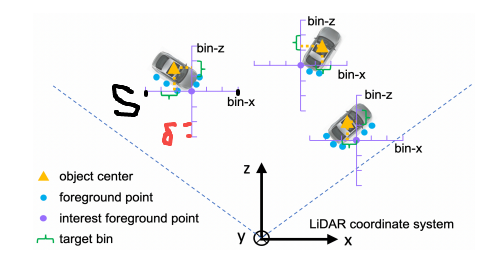
那基于Bin的回归损失又是什么呢?
和原先的主要区别在于对于X、Z以及角度引入了类别损失,其他的Y,h, w, l还是只用到回归损失,这样做的目的文中说是能更好的估计物体的中心点(感觉像是把X,Z和角度划分成bin后,预测类别在预测其偏移量,和后续h,w,l给定物体尺寸类似,最终回归损失都是预测和给定值的偏移量)。
-
X,Z
文中说为了更好的估计出物体的中心点位置,其将XZ维度按照前景点位置将物体所在区域划分成等间隔的块,将每个块看成一个类别,对于X和Z维度不仅计算回归损失,还添加类别损失进行限制。
具体计算如下:
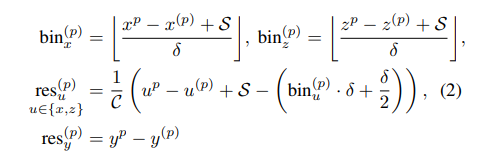
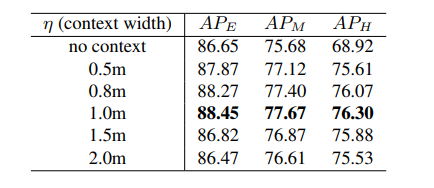
其中S表示范围(实验给定是3m),表示间隔长度(0.5m)。 -
\theta
对于偏转角也将一个圆周(360)划分成不同的块,然后计算角度类别损失和回归损失。 -
全部损失
按照前面介绍,损失分为x,z,以及y,h,w,l两大块。
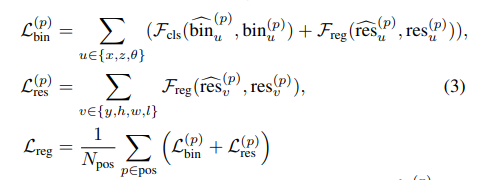
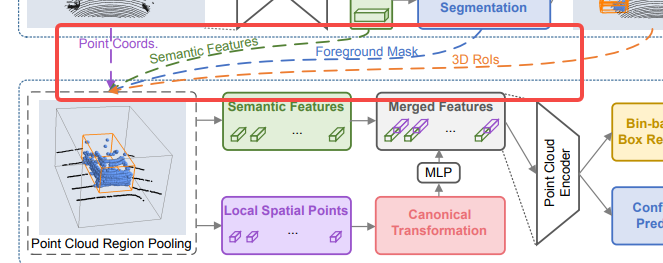
4、第二阶段的Point Cloud Region Pooling
在获得3D候选框后,我们的目标是基于先前生成的框来进一步优化其的位置和方向。为了学习每个框更具体的局部特征,提出根据每个3D框的位置,从第一阶段中汇集3D点及其对应的点特征,便于后续更好的进行框优化。
这一步的目的主要是将点的特征进行聚合,其可以分为以下两个步骤。
-
将候选框的范围扩大一个常量n(1.0m)
即将框 变为
-
特征聚合
对内部的所有点进行特征进行聚合,包括:原始点云坐标(x, y, z)反射强度(r),该点的类别(m, 前景或背景)以及该点在在第一阶段通过PointNet++得到的C维度的特征向量()。
5、第二阶段的Canonical 3D bounding box refinement
这一部分对前面聚合的特征进一步划分为局部特征和语义特征,其中局部特征经过坐标变换后重新提取,语义特征就是PointNet++提取的特征向量。
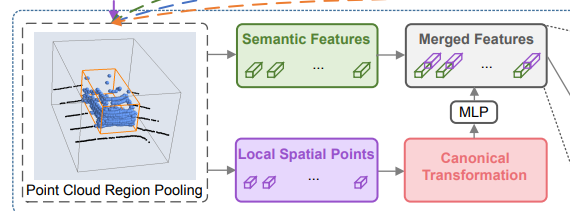
Canonical transformation
对每一个框建立一个坐标系,将坐标变换后文中说是可以更好的获取局部特征,这个坐标系的特点为:
- 坐标系的原点为proposal的中点;
- X和Z轴与水平地面平行且X轴为获选框朝向的位置;
- Y轴水平向下;
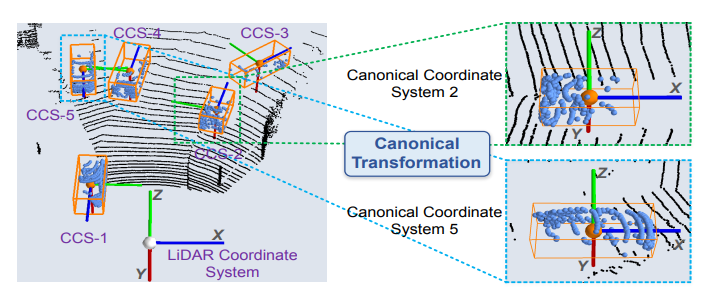
局部特征
但是坐标系改变后,点的深度信息难免会损失,为了解决这个问题,作者引入来作为深度特征,所以经过坐标变换后提取的局部特征为:
, r表示原始点云的强度信息,m表示点的类别(前景或背景),d表示深度特征。
框优化损失
如果获选框和真实框的IOU超过0.55,则将这个候选框作为学习目标。损失函数如下:第一项为框是Positive还是Negative的分类损失;第二项为Positive框的位置细化损失。
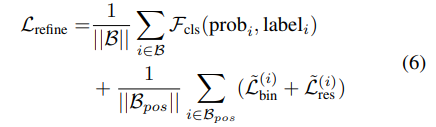
-
X, Z损失
参考前面第一阶段候选框生成的损失,这里的X和Z依旧采用bin_based损失,只不过这里对于真实标注框和候选框都做了坐标变换。
候选框:变为
真实框:变为 -
角度损失
角度变换后表示的是真实框和候选框角度的差值,所以这里将其划分在,其类别及残差损失如下:
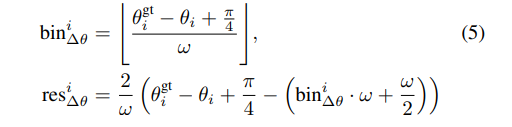
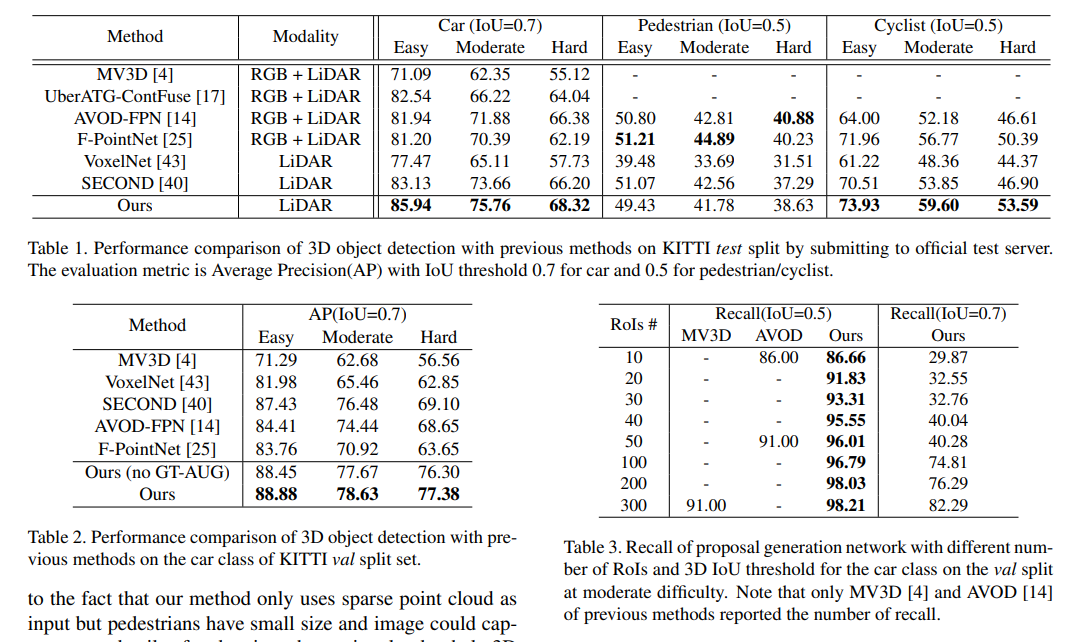
四、效果
实验结果显示PointRCNN表现较好。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通