
MobileNetV3
前面介绍了MobileNetV1和MobileNetV2,这次介绍这个系列最后一篇MobileNetV3,它沿用了V1的深度可分离卷积以及v2的倒残差网络和瓶颈层,再其基础上做了一系列优化,保证精度最大化的同时减少网络延时。主要改进点包含以下几步:
- 引入NetAdapt算法自动获取扩展层和瓶颈层的通道数量
- 重新对网络耗时层进行优化,减少网络延迟
- 在激活层方面,采用h-wish替代ReLu6,
- 引入SE(Squeeze-and-Excitation)模块,进一步减少通道数量
- 提出了MobileNet-Large和MobileNet-small两个版本
论文链接:https://arxiv.org/abs/1905.02244
一、NetAdapt
《NetAdapt:Platform-Aware Neural Network Adaptation for Mobile Applications》: https://arxiv.org/pdf/1804.03230.pdf
这篇文章提出了一种新的网络压缩算法NetAdapt,它使用一个预训练好的模型在固定计算资源的手机平台上进行压缩试验,直接采集压缩之后的性能表现(计算耗时与功耗,文章称其为direct metrics)作为feedback,得到一系列满足资源限制、同时最大化精度的简化网络。
NetAdapt将优化之后的网络部署到设备上直接获取实际性能指标,之后再根据这个实际得到的性能指标指导新的网络压缩策略,从而以这样迭代的方式进行网络压缩,得到最后的结果,其算法流程见下图所示,NetAdapt的网络优化以自动的方式进行,逐渐降低预训练网络的资源消耗,同时最大化精度。NetAdapt不仅可以生成一个满足预算的网络,而且可以生成一系列具有不同折衷程度的简化网络,从而实现动态的网络选择和进一步的研究。
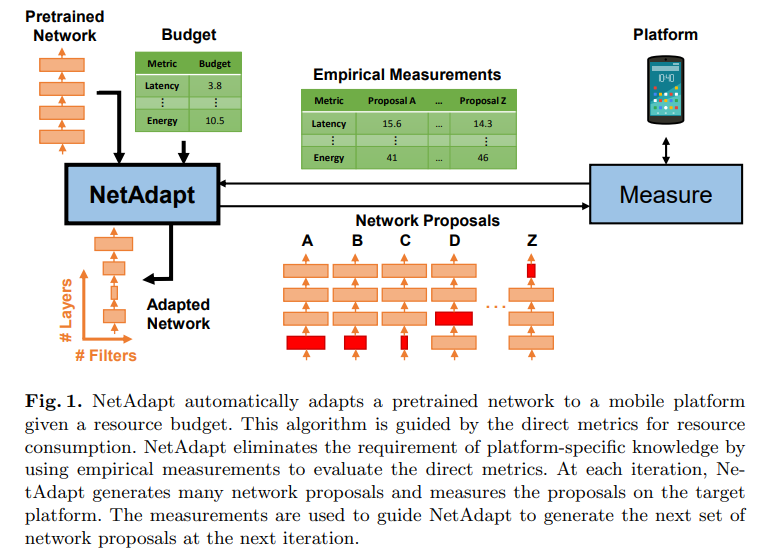
MobileNetV3利用NetAdapt算法得到扩展层和瓶颈层的通道数量,在保证精度同时减少延迟。
二、优化网络耗时的层
文中通过实验主要指出以下三个优化点:
1、去除倒残差块中深度卷积和降采样操作
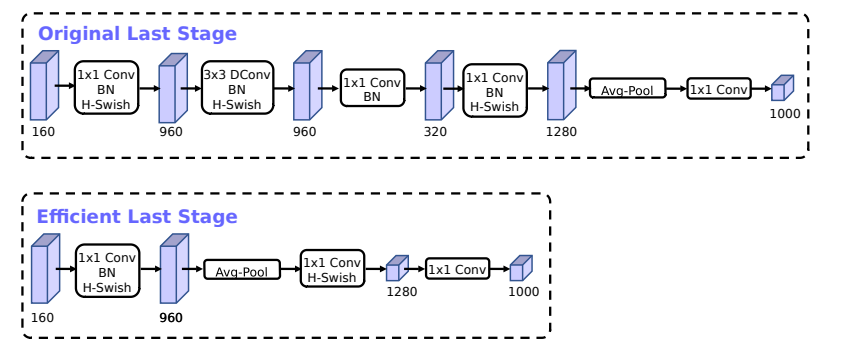
2、平均池化操作前置,减少计算量的同时还能保证精度
原先在全局平均池化层之前,还存在一个1 × 1卷积,将通道数从320扩展到1280,这样做能得到更高维度的特征供分类器层使用。但是也引入了额外的计算成本与延时,因此将其放于1 x 1的卷积之前,这样可以保证精度的同时减少计算量,同时前面的深度卷积和降采样也可以去除。
3、减少初始特征滤波器数量,32减少为16
经过前面两步优化,其效果如下:
三、h-wish替换ReLu6
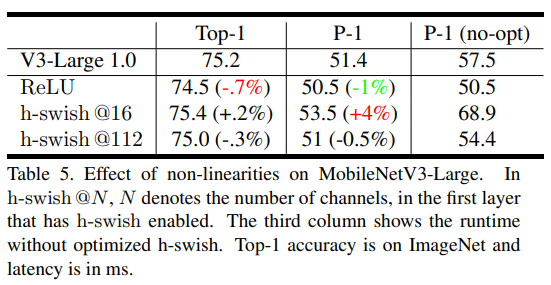
采用h-swish替换ReLu6,实验中发现,这样替换精度没有明显差异,反而是在部署时存在以下优点:
- 可以适应所有的软硬件
- 在量化模式下,可以减少对sigmoid估计带来的误差
- 在实际应用过程中,h-swish分段函数可以减少内存访问次数,进而减少延时
注意:实际验证只在深层网络中才用h-swish替换sigmoid效果更好,另外由于浅层网络往往特征层较大,采用h-swish计算成本更高。
四、SE
《Squeeze-and-Excitation Networks》: https://arxiv.org/pdf/1709.01507.pdf
这篇文章考虑特征通道之间的关系来提升性能,其动机是希望显式地建模特征通道之间的相互依赖关系。

MobileNetV3不同于MnasNet中SE瓶颈层的大小刚好和卷积瓶颈层大小相反,这里将其通道数全部变为扩展层中通道数量的1/4,实验发现该操作适当增加参数提高了精度,但延时没有明显变化。
另外还将其中sigmoid激活函数替换为了
五、MobileNetV3-Large和Small
MobileNetV3提出了MobileNetV3-Large和MobileNetV3-Small两个版本
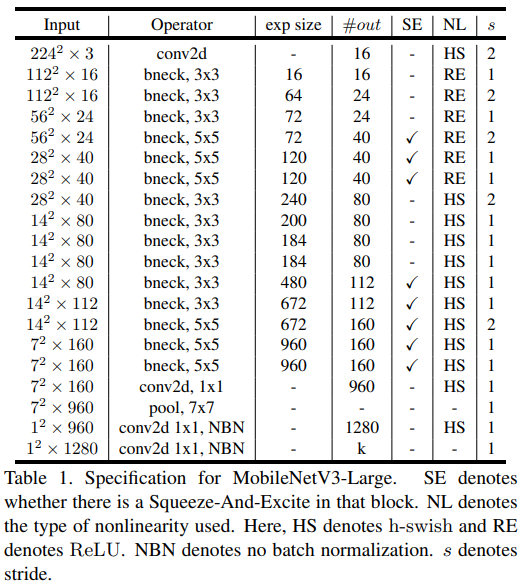

其主要差别是在层数和通道上数量上。其中s和v2一样表示卷积的步长,SE表示是否包含SE层,NL表示采用的激活函数,out为输出通道数。
六、代码实现
#!/usr/bin/env python
# -- coding: utf-8 --
import torch
import torch.nn as nn
import torch.nn.functional as F
def get_model_parameters(model):
total_parameters = 0
for layer in list(model.parameters()):
layer_parameter = 1
for l in list(layer.size()):
layer_parameter *= l
total_parameters += layer_parameter
return total_parameters
def weights_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
torch.nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.inplace = inplace
def forward(self, x):
return F.relu6(x + 3., inplace=self.inplace) / 6.
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.inplace = inplace
def forward(self, x):
out = F.relu6(x + 3., self.inplace) / 6.
return out * x
def make_divisible(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class SqueezeBlock(nn.Module):
def __init__(self, exp_size, divide=4):
super(SqueezeBlock, self).__init__()
self.dense = nn.Sequential(
nn.Linear(exp_size, exp_size // divide),
nn.ReLU(inplace=True),
nn.Linear(exp_size // divide, exp_size),
h_sigmoid()
)
def forward(self, x):
batch, channels, height, width = x.size()
out = F.avg_pool2d(x, kernel_size=[height, width]).view(batch, -1)
out = self.dense(out)
out = out.view(batch, channels, 1, 1)
return out * x
class MobileBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernal_size, stride, nonLinear, SE, exp_size, dropout_rate=1.0):
super(MobileBlock, self).__init__()
self.out_channels = out_channels
self.nonLinear = nonLinear
self.SE = SE
self.dropout_rate = dropout_rate
padding = (kernal_size - 1) // 2
self.use_connect = (stride == 1 and in_channels == out_channels) # short-cut
if self.nonLinear == "RE":
activation = nn.ReLU
else:
activation = h_swish
self.conv = nn.Sequential(
nn.Conv2d(in_channels, exp_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(exp_size),
activation(inplace=True)
)
self.depth_conv = nn.Sequential(
nn.Conv2d(exp_size, exp_size, kernel_size=kernal_size, stride=stride, padding=padding, groups=exp_size),
nn.BatchNorm2d(exp_size),
)
if self.SE:
self.squeeze_block = SqueezeBlock(exp_size)
self.point_conv = nn.Sequential(
nn.Conv2d(exp_size, out_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_channels),
activation(inplace=True)
)
def forward(self, x):
out = self.conv(x)
out = self.depth_conv(out)
# Squeeze and Excite
if self.SE:
out = self.squeeze_block(out)
# point-wise conv
out = self.point_conv(out)
# connection
if self.use_connect:
return x + out
else:
return out
class MobileNetV3(nn.Module):
def __init__(self, model_mode="LARGE", num_classes=1000, multiplier=1.0):
super(MobileNetV3, self).__init__()
self.activation_HS = nn.ReLU6(inplace=True)
self.num_classes = num_classes
print("num classes: ", self.num_classes)
if model_mode == "LARGE":
layers = [
[16, 16, 3, 1, "RE", False, 16],
[16, 24, 3, 2, "RE", False, 64],
[24, 24, 3, 1, "RE", False, 72],
[24, 40, 5, 2, "RE", True, 72],
[40, 40, 5, 1, "RE", True, 120],
[40, 40, 5, 1, "RE", True, 120],
[40, 80, 3, 2, "HS", False, 240],
[80, 80, 3, 1, "HS", False, 200],
[80, 80, 3, 1, "HS", False, 184],
[80, 80, 3, 1, "HS", False, 184],
[80, 112, 3, 1, "HS", True, 480],
[112, 112, 3, 1, "HS", True, 672],
[112, 160, 5, 1, "HS", True, 672],
[160, 160, 5, 2, "HS", True, 672],
[160, 160, 5, 1, "HS", True, 960],
]
init_conv_out = make_divisible(16 * multiplier)
self.init_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=init_conv_out, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(init_conv_out),
h_swish(inplace=True),
)
self.block = []
for in_channels, out_channels, kernal_size, stride, nonlinear, se, exp_size in layers:
in_channels = make_divisible(in_channels * multiplier)
out_channels = make_divisible(out_channels * multiplier)
exp_size = make_divisible(exp_size * multiplier)
self.block.append(MobileBlock(in_channels, out_channels, kernal_size, stride, nonlinear, se, exp_size))
self.block = nn.Sequential(*self.block)
out_conv1_in = make_divisible(160 * multiplier)
out_conv1_out = make_divisible(960 * multiplier)
self.out_conv1 = nn.Sequential(
nn.Conv2d(out_conv1_in, out_conv1_out, kernel_size=1, stride=1),
nn.BatchNorm2d(out_conv1_out),
h_swish(inplace=True),
)
out_conv2_in = make_divisible(960 * multiplier)
out_conv2_out = make_divisible(1280 * multiplier)
self.out_conv2 = nn.Sequential(
nn.Conv2d(out_conv2_in, out_conv2_out, kernel_size=1, stride=1),
h_swish(inplace=True),
nn.Conv2d(out_conv2_out, self.num_classes, kernel_size=1, stride=1),
)
elif model_mode == "SMALL":
layers = [
[16, 16, 3, 2, "RE", True, 16],
[16, 24, 3, 2, "RE", False, 72],
[24, 24, 3, 1, "RE", False, 88],
[24, 40, 5, 2, "RE", True, 96],
[40, 40, 5, 1, "RE", True, 240],
[40, 40, 5, 1, "RE", True, 240],
[40, 48, 5, 1, "HS", True, 120],
[48, 48, 5, 1, "HS", True, 144],
[48, 96, 5, 2, "HS", True, 288],
[96, 96, 5, 1, "HS", True, 576],
[96, 96, 5, 1, "HS", True, 576],
]
init_conv_out = make_divisible(16 * multiplier)
self.init_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=init_conv_out, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(init_conv_out),
h_swish(inplace=True),
)
self.block = []
for in_channels, out_channels, kernal_size, stride, nonlinear, se, exp_size in layers:
in_channels = make_divisible(in_channels * multiplier)
out_channels = make_divisible(out_channels * multiplier)
exp_size = make_divisible(exp_size * multiplier)
self.block.append(MobileBlock(in_channels, out_channels, kernal_size, stride, nonlinear, se, exp_size))
self.block = nn.Sequential(*self.block)
out_conv1_in = make_divisible(96 * multiplier)
out_conv1_out = make_divisible(576 * multiplier)
self.out_conv1 = nn.Sequential(
nn.Conv2d(out_conv1_in, out_conv1_out, kernel_size=1, stride=1),
SqueezeBlock(out_conv1_out),
nn.BatchNorm2d(out_conv1_out),
h_swish(inplace=True),
)
out_conv2_in = make_divisible(576 * multiplier)
out_conv2_out = make_divisible(1280 * multiplier)
self.out_conv2 = nn.Sequential(
nn.Conv2d(out_conv2_in, out_conv2_out, kernel_size=1, stride=1),
h_swish(inplace=True),
nn.Conv2d(out_conv2_out, self.num_classes, kernel_size=1, stride=1),
)
self.apply(weights_init)
def forward(self, x):
out = self.init_conv(x)
out = self.block(out)
out = self.out_conv1(out)
batch, channels, height, width = out.size()
out = F.avg_pool2d(out, kernel_size=[height, width])
out = self.out_conv2(out)
out = out.view(batch, -1)
return out


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端