
深度学习---图像分割
2D物体分割
在https://www.cnblogs.com/xiaxuexiaoab/p/17403325.html中提到过,2D物体分割大体可以分为语义分割、实例分割和全景分割,这里对其基本概念进行介绍,并参照一篇综述,按照分割采用的方法不同分为十类。
一、基本概念
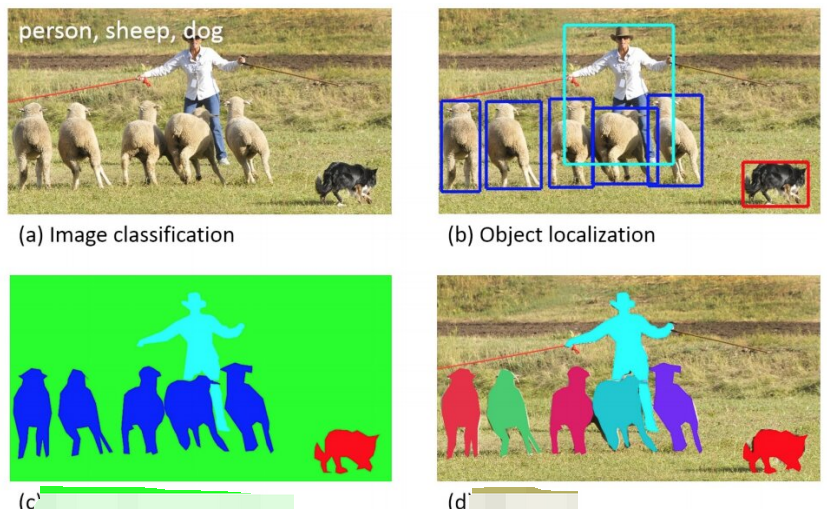
语义分割、实例分割和全景分割的区别可以参考下图。

1.1 stuff和thing
stuff和thing在英文中都表示物体,其主要区别在于stuff不可数,thing可数。
在计算机视觉的早期,表示如人、动物、工具等可计数物体的thing受到了主要的关注。2001年阿德尔森提出了研究识别stuff的系统的重要性,stuff主要指类似纹理或材料的无定形区域,如草地、天空、道路。这种thing与stuff之间的区分在视觉领域一直持续到今天。
1.2 语义分割
研究stuff通常被定义为一项语义分割任务,即对图片中每个像素分配一个语义标签(类别),但是不区分单个类别中的对象实例。如图b,有汽车,人,道路,树木、交通标志、房屋等,但所有人都归为一类,车也是一样。注意语义分割领域把thing统一作为stuff处理。

1.3 实例分割
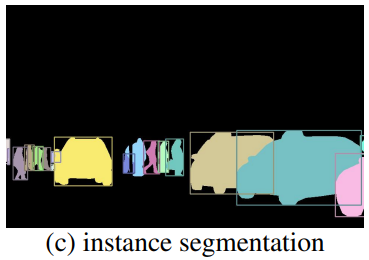
研究thing通常被定义为一项目标检测或者实例分割任务,实例分割可以理解成目标检测和语义分割的结合,其检测出每个对象的位置,并用分割掩膜(mask)表示每个对象所在区域,同一类别中的不同物体表示为不同的实例。如图c,不同的汽车和人分别被分割成不同的对象。
1.4 全景分割
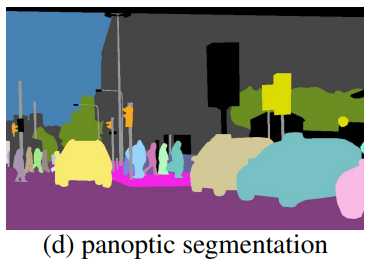
全景分割任务中同时包含stuff和thing,可以理解成语义分割和实例分割的结合,即每个像素都分配一个语义标签和一个实例ID,语义标签和实例ID都相同的像素认为是属于同一个对象,对于stuff而言实例ID会被忽略。可以参考图d,选择哪个类是stuff还是thing由数据集制作者选择。
和语义分割的关系:全景分割任务格式是语义分割格式的严格概括,实际上,这两个任务都要求为图像中的每个像素分配一个语义标签。如果真实标签未指定实例,或者所有类都是stuff,则任务是相同的(尽管任务指标不同)。此外,如果包含thing类(可能每个图像有多个实例)则可以区分这两个任务。
和实例分割的关系:实例分割任务需要一种对图像中的每个对象实例进行分割的方法,但是它允许重叠的片段,方便全景分割任务仅允许为每个像素分配一个语义标签和一个实例ID。因此,对于全景分割,构造上不可能有任何重叠。
测试


二、 按方法划分为十大类
参考综述:Image Segmentation Using Deep Learning: A Survey
这篇综述文献按照分割方法的不同,将图像分割分为以下十大类。
2.1 分类
- 全连接网络 : ParseNet/FCN
- 卷积+图模型: CRFs / MRFs + 条件随机场
- 编解码: UNet/VNet(3D)
- 多尺度: FPN/PSPN(Pyramid Scene Parsing Network)
- RCNN: Faster RCNN / Mask RCNN
- 空洞卷积: ENet / DeepLab family/ ASPP(Atrous Spatioal pyramid pooling)
- RNN: ReSeg(从图像的上下左右四个方向采用RNN) / graph_LSTM / DA_RNNs
- 注意力机制: RAN / OCNet
- GAN: 分割 + 对抗网络
- 轮廓模型: Active Contours Models / DSAC 需要初始轮廓曲线
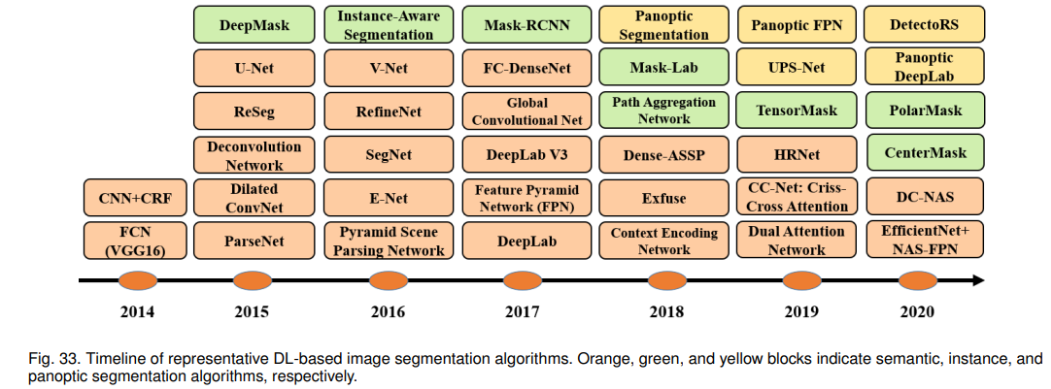
2.2 2014 ~ 2020 年主要模型
模型按时间划分
三、常见模型
3.1 语义分割模型
UNet : https://arxiv.org/abs/1505.04597
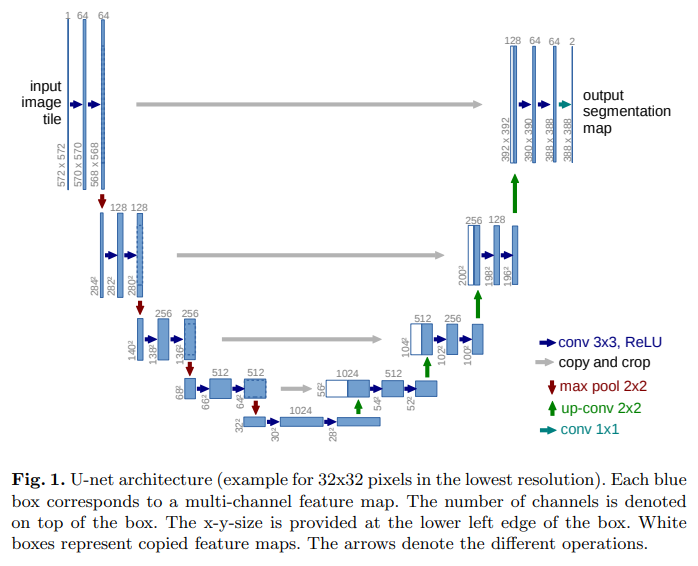
参照上图可以清楚看到,其网络结构呈U字形,先进行下采样,然后再逐步上采样,中间特征通过连接层相结合,实现了特征多尺度融合,其在语义分割应用非常广泛。
3.2 实例分割模型
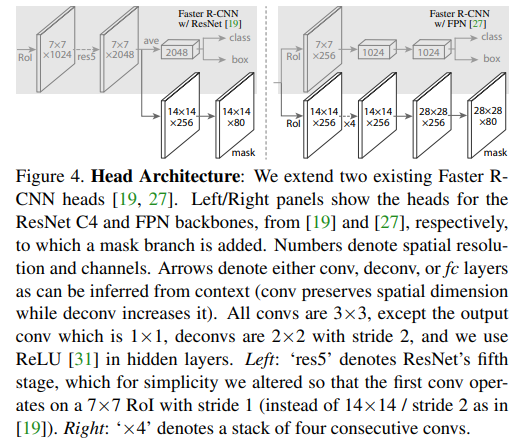
MaskRCNN :https://arxiv.org/abs/1703.06870

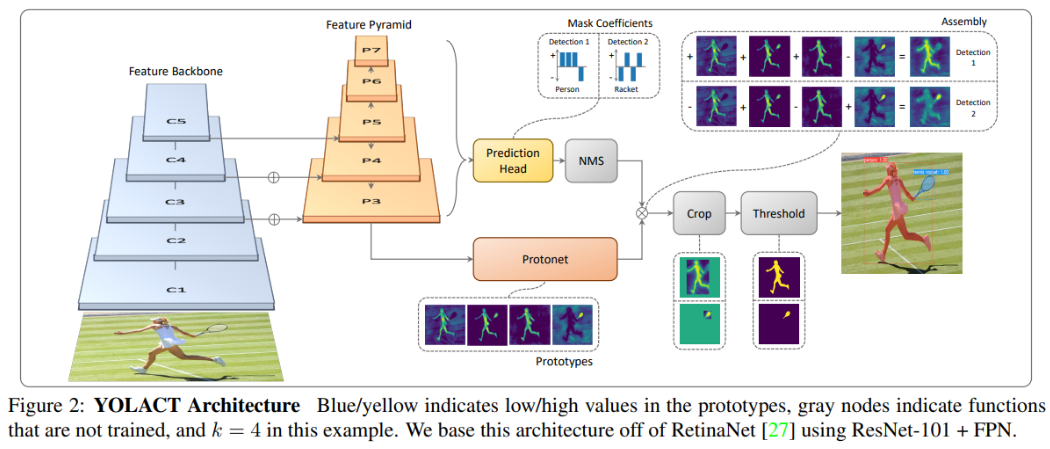
Yolact:https://arxiv.org/abs/1912.06218
3.3 全景分割模型
Panoptic Feature Pyramid Networks: https://arxiv.org/pdf/1901.02446.pdf


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端