
AdaBoost学习笔记
学习了李航《统计学习方法》第八章的提升方法,现在对常用的一种提升方法AdaBoost作一个小小的笔记,并用python实现书本上的例子,加深印象。提升方法(boosting)是一种常用的统计学习方法,在分类中通过改变样本的权值分布,学习多个分类器,然后组合这些分类器,提高分类性能。
一、 提升方法的问题
2、如何组合弱分类器
AdaBoost的解决方案
1、在训练过程中,提高前一轮被分类器错误分类的样本权值,降低被正确分类的样本权值
2、采用加权多数表决的方法,即分类时误差小的分类器权重提高,分类误差大的分类器权重减小
二、AdaBoost算法步骤
1、初始化训练数据的权值分布(初始化时一般赋予相同的权值:1/N);
2、训练弱分类器。根据具有权值分布的训练数据,得到弱分类器,根据当前分类器,如果样本点被正确分类,则降低该样本的权值,反之提高权值,对样本权值分布进行更新,然后在根据更新后的样本数据训练下一个弱分类器;
3、组合弱分类器。根据分类器训练误差,计算分类器的权重,误差越大,权重越小,然后把加权后的分类器进行相加得到强分类器。
下面是一个二分类算法
算法: (输入:训练数据集T={(x1,y1),(x2,y2),..,(xN,yN))},输出:最终分类器)
(1)初始化训练数据的权值分布
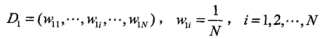
(2)训练弱分类器。对于m=1,2,...,M (M为弱分类器个数)
(a) 使用具有权值分布Dm的训练数据集学习,得到基本分类器
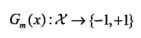
(b) 计算Gm(x)在训练数据集Dm上的分类误差率:
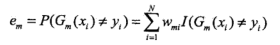
这里相当于把没有正确分类的样本对应的权值求和。
(c) 计算Gm(x)的权重系数:
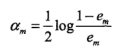
这里log表示自然对数,将am对em求导后可以得到对应的导函数为1/(em-1)em,误差0<em<1,所以对应的导函数小于0,即系数am随着误差em的增大而减少。
(d) 更新训练数据集权值分布:

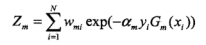
这里Zm是对权值进行归一化,保证权值和为1,另外样本如果正确分类,则yi*Gm(xi)为一个正数,前面添加负号和乘以am,这可以看出正确分类的样本其权值降低,错误分类的样本权值提高。
(3)构建基本分类器的线性组合,得到最终分类器


三、例题(python实现)
1、初始化权值分布

## 导入数据 import numpy as np x = np.arange(10) # x共10个,利用numpy生成 y = np.array([1,1,1,-1,-1,-1,1,1,1,-1], dtype=int) #例题中对应的标签值 ## 权值初始化,一共10个数,初始权值赋为1/10 N = x.shape[0] w_0 = np.array([1/N]*N) #先计算1/N,然后乘以个数 w_0

2、x1和x2之间的阀值取x1+(x2-x1)*b,x之间间隔为1,因此0<b<1都行,这里参照书本取b=0.5
# 得到所有阀值,存入列表 v = np.array([(x1+x2)/2 for x1, x2 in zip(x[:-1], x[1:])]) v

3、训练一个弱分类器
# 定义一个分类函数 输入:样本数据x,y,阀值v,权重w 输出:最佳阀值min_v,该分类器分类结果res,和权重alpha,以及误差min_error def get_res(x,y,v,w): error_1 = [] # 用于存放所有阀值分类得到的误差 error_2 = [] res_1 = np.ones(x.shape[0], dtype=int) # 先初始化结果全为1 小于阀值取1,大于取-1 res_2 = np.ones(x.shape[0], dtype=int) # 先初始化结果全为1 小于阀值取-1,大于取1 for v_i in v: # 对每一个阀值计算分类误差 for x_i in x: if x_i < v_i: res_1[x_i] = 1 res_2[x_i] = -1 else: res_1[x_i] = -1 res_2[x_i] = 1 error_1.append(np.sum(w[y!=res_1])) error_2.append(np.sum(w[y!=res_2])) min_error_1 = min(error_1) # 最小误差 min_error_2 = min(error_2) if min_error_1 > min_error_2: min_error = min_error_2 min_error_index = error_2.index(min_error_2) # 求出最小误差对应的索引值,用于找出最佳阀值 label = '小于取-1,大于取1' state = 0 # 用于判断分类器怎么分类 求res else: min_error = min_error_1 min_error_index = error_1.index(min_error_1) label = '小于取1,大于取-1' state = 1 min_v = v[min_error_index] # 得到最佳阀值 alpha = 1/2 * np.log((1-min_error)/min_error) # 计算该分类器的权值 if state == 1: res = [1 if x_i < min_v else -1 for x_i in x] # 计算该分类器分类结果 else: res = [-1 if x_i < min_v else 1 for x_i in x] return alpha, min_v, label, res, min_error
## 输入初始权值,进行测试 alpha1, v1, label, res1, min_error = get_res(x,y,v,w_0) v1,label,alpha1,res1,min_error

4、更新样本数据权值分布
### 定义一个更新函数 输入:前一个分类器的权重alpha和分类结果res 样本标签y, 前一次样本权值分布w 输出:样本数据新的权值分布w def update_data_weight(alpha, res, y, w): numerator = w*np.exp(-alpha*y*res) # 8.4式分子 denominator = w.dot(np.exp(-alpha*y*res)) # 8.4式分母Zm return numerator/denominator
## 测试 w_1 = update_data_weight(alpha1, res1, y, w_0) w_1
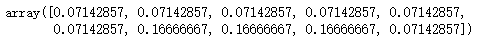
5、构建最终分类器
## alpha 各弱分类器权重列表 ## res 各弱分类器分类结果列表 def final_model(alpha, res): f = np.sum(alpha*res, axis=0) return [1 if i > 0 else -1 for i in f]
这里在对其进行综合,代码如下。
n = 3 # 弱分类器个数1 sigmma = 0.001 # 终止误差 x = np.arange(10) # 样本中x值 y = np.array([1,1,1,-1,-1,-1,1,1,1, -1], dtype=int) # 样本中x对应的标签值 N = x.shape[0] # 样本个数 alpha = np.zeros((n, 1)) # 初始化分类器权重矩阵 W = np.zeros((n, N)) # 初始化权值分布 res = np.zeros((n, N)) # 初始化各分类器结果 res_save = [] # 保存每一次的阀值和误差 w = np.array([1/N]*N) # 样本初始权值分布 v = np.array([(x1+x2)/2 for x1, x2 in zip(x[:-1], x[1:])]) # 所有阀值 for i in range(n): alpha_i, v_i, label, res_i, min_error_i = get_res(x,y,v,w) if min_error_i < sigmma: # 如果满足误差要求 停止迭代 break w = update_data_weight(alpha_i, res_i, y, w) alpha[i] = alpha_i res[i:] = res_i res_save.append([v_i, label, min_error_i]) W[i:] = w result = final_model(alpha, res) print('最终分类结果:', result) print('各分类器分类结果:', res) print('各分类器系数:', alpha) print('各分类器阀值及误差:',res_save) print('样本权值分布:',W)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端