无码理解什么是ConcurrentHashMap?(上篇)
微信公众号:大黄奔跑
关注我,可了解更多有趣的面试相关问题。
写在之前
Hello,大家好,又和大家见面了。
之前写的一些文章,被女票吐槽说晦涩难懂,又臭又长。仔细一想还真是那么回事儿,现在用手机看技术文章不就是图一个方便吗,如果和源码一样长,为何不直接去看源码或者书籍呢。
因此突发奇想,能不能写一篇无码介绍一个知识点呢?所以本文的标题应运而生了,无码理解什么是ConcurrentHashMap。(这里有些许标题党的意思,但是还是尽量做到简单易懂,没有复杂的代码)
由于ConcurrentHashMap内容比较多,因此本文分为上线篇,上篇主要介绍底层存储结构、初始化过程、put()过程、get()过程。
1. 为什么需要ConcurrentHashMap
首先看第一个问题,
1. 为啥需要`ConcurrentHashMap`?
之前了解过HashMap的同学都知道是非线程安全的,但是JDk本身也提供了Hashtable和Collections.synchronizedMap(hashMap),为什么Doug Lea(此大神真牛逼,整个JUC包都是他写的)还要设计底层实现如此复杂的ConcurrentHashMap呢?
其实还是需要从性能上看,这两个方案基本上是对读写进行加锁操作,一个线程在读写元素时,其余线程必须等待,比如一个线程在插入数据时,其他线程不能读写了,其性能再高并发下比较低。
更加准确地说:他们使用一个全局的锁来同步不同线程间的并发访问,同一时间点,只能有一个线程持有锁,也就是说在同一时间点,只能有一个线程能访问容器,这虽然保证多线程间的安全并发访问,但同时也导致对容器的访问变成串行化的了。
2. JDk1.7以前如何实现的?
回答这个问题需要从两个方面来理解,结构和线程安全性。
1、数据结构是什么样的?
和HashMap的1.7类似,底层采用数组+链表的存储结构。
2、如何保证线程安全?
采用 分段锁的机制,实现并发的更新操作。
底层主要借用两个内部类: Segment和HashEntry,其内部主要注意点如下:
Segment继承ReentrantLock用来充当锁的角色,每个Segment对象守护每个散列映射表的若干个桶。【也就是说由hashTable中锁某一个元素,变成锁一批元素,其实这就是锁优化中的粗化】- 每个桶是由若干个
HashEntry对象链接起来的链表 HashEntry用来封装映射表的键 / 值对;
整个存储结构如下:
一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。

每次添加和获取元素时,都是直接锁住一批segment,保证这一批元素在同一个时间段内只有一个线程在操作,
3. JDk1.8底层原理?
这个问题同样从两个方面回答。
- 底层数据结构做了何种优化,让性能变好了。
- 如何保证线程安全,是否还继续沿用了Segment?
1. 底层数据结构
ConcurrentHashMap在1.8中存储主要用数组+链表+红黑树构成。存储结构示意图如下:
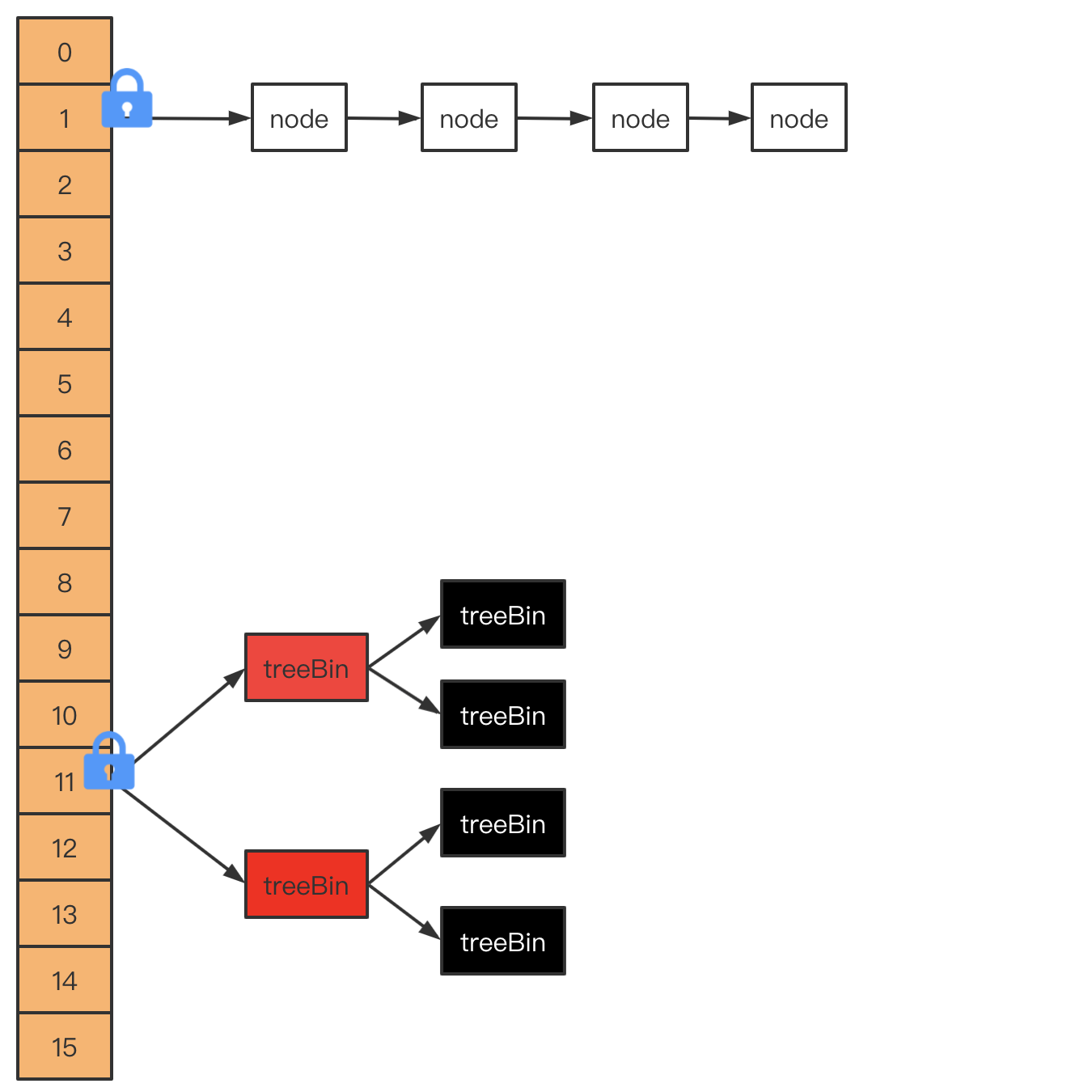
2. 如何实现线程安全?
JDK1.8的实现已经抛弃了Segment分段锁机制,利用CAS+Synchronized来保证并发更新的安全,和HashMap类似底层采用数组+链表+红黑树的存储结构。
可能有人会奇怪,不是说Synchronized性能低吗,为什么1.8还继续用Synchronized呢?
首先有两点:
Synchronized在1.8已经做了很大的优化了,本身性能已经提升了很多。Synchronized只是用于锁住链表或者红黑树的第一个节点,只要没有Hash冲突,不存在并发问题,效率也会提升N倍。
4. ConcurrentHashMap初始化过程
和别的容器不同,ConcurrentHashMap不是通过构造方法进行初始化的,而是在构造方法的时候计算了如果初始化时,需要多大的容量并且赋值给全局变量sizeCtl。
为什么要增加一个全局变量sizeCtl呢,并且是`volatile`修改的全局变量,
这个还需要从该关键字的含义说起
**不同的值表示不同的含义**。
负值:表示正在初始化或者扩容。其中
-1:表示正在初始化
-N:表示有N个线程在初始化或者扩容
正数或0:代表hash表还没有被初始化,数值表示初始化或下一次进行扩容的大小
也就是说第一次的时候,只是告诉系统,如果你要装一个苹果,要先买一个半径为10cm的盘子。
虽然系统将真正的初始化程序后置了,但是不妨碍我们先分析初始化的过程。
主要初始化流程如下:

sizeCtl默认为0,如果实例化时有传参数,sizeCtl会是一个2的幂次方的值。所以执行第一次put操作的线程会通过CAS将sizeCtl修改为-1,并且保证有且只有一个线程能够修改成功,其它线程通过Thread.yield()让出CPU时间片等待table初始化完成。
5. 添加元素(put())思路
主要步骤如下:
(1)计算key对应的hash值,类似于hashmap中高位计算hash值
(2)判断tab是否为空,如果为空,则初始化tab
(3)获取tab处对应索引的元素f,底层tabAt()方法通过U.getObjectVolatile()获取值,判断是否为空。
1)如果f为null,说明table中这个位置第一次插入元素
2)利用Unsafe.compareAndSwapObject方法插入Node节点,如果设置成功,则走到是否需要扩容一步。
(4)如果f的hash值为-1,说明当前f是ForwardingNode节点,意味着有其它线程正在扩容,则一起进行扩容操作
(5)走到这一步说明发生了hash冲突,把新的Node节点按链表或红黑树的方式插入到合适的位置,这个过程采用同步内置锁实现并发
1)锁住头结点
2)首先利用tabAt(tab, i) == f判断是否是同一个元素,防止f同时被其它线程修改
3)如果f.hash >= 0,说明f是链表结构的头结点,遍历链表,如果找到对应的node节点,则修改value;否则在链表尾部加入节点
4)上一步中, 如果hash相同,key相同,则直接覆盖value即可,并且直接跳出循环
5)上一步不满足,则往后遍历节点
(6)如果这个节点是树节点,就按照树的方式插入值
(7)如果链表中节点数binCount >= TREEIFY_THRESHOLD(默认是8),则把链表转化为红黑树结构
(8)通过addCount()修改元素数量,并且判断是否需要扩容
整体put()方法流程图如下
ps:大家可以将源码和本图对照着看
流程")
6. get()流程
get()方法相对于put()方法简单不少,主要流程如下:
流程")
总结
ConcurrentHashMap 是一个并发散列映射表的实现,最大的优点是允许完全并发的读取,并且性能仍然比较高。主要是合理利用全局变量sizeCtl来控制容器状态(想想AQS也是通过state关键字来控制不同的状态,有异曲同工之妙),通过cas和synchronized来保证线程安全。
下次再给大家介绍容器size计算方式和ConcurrentHashMap的扩容机制。
番外
我是大黄,一个只会写HelloWorld的程序员,意图利用平时时间拆解每一个面试问题。
面试三分钟,平时不放松。
咱们下期见。
参考:
https://programmer.ink/think/analysis-of-concurrent-hashmap-principle.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号