
python遍历目录os.walk(''d:\\test2",topdown=False)
os.walk(top, topdown=True, onerror=None, followlinks=False)遍历目录,topdown=false表示先返回目录,后返回文件
参数说明:
top:表示需要遍历的目录树的路径。
topdown的默认值是True,表示首先返回根目录树下的文件,然后遍历目录树下的子目录。值设为False时,则表示先遍历目录树下的子目录,返回子目录下的文件,最后返回根目录下的文件。
例子:可以看出,topdown设值不同,os.walk()返回的列表元素顺序不同(但不是相反),所以遍历后的结果也不同
topdown=False:
#encoding=utf-8
import os
r=os.walk('d:\\test2',topdown=False)
for i in r:
print i
结果:
D:\>python test.py
('d:\\test2\\dir1', [], [])
('d:\\test2\\dir2\\dir3', [], ['2.txt', '33.bmp'])
('d:\\test2\\dir2', ['dir3'], ['1.txt'])
('d:\\test2', ['dir1', 'dir2'], [])
topdown=True:
import os
r=os.walk('d:\\test2',topdown=True)
for i in r:
print i
结果:
D:\>python test.py
('d:\\test2', ['dir1', 'dir2'], [])
('d:\\test2\\dir1', [], [])
('d:\\test2\\dir2', ['dir3'], ['1.txt'])
('d:\\test2\\dir2\\dir3', [], ['2.txt', '33.bmp'])
onerror的默认值是None,表示忽略文件遍历时产生的错误。如果不为空,则提供一个自定义函数提示错误信息后继续遍历或抛出异常中止遍历。
该函数返回一个列表,列表中的每一个元素都是一个元组,该元组有3个元素,分别表示每次遍历的路径名,目录列表和文件列表。
>>> r=os.walk('d:\\test2',topdown=False)
>>> r
<generator object walk at 0x0000000004C5D480>
>>> list(r)
[('d:\\test2\\dir1', [], []), ('d:\\test2\\dir2\\dir3', [], ['2.txt', '33.bmp']), ('d:\\test2\\dir2', ['dir3'], ['1.txt']), ('d:\\test2', ['dir1', 'dir2'], [])]
默认情况下,os.walk 不会遍历软链接指向的子目录,若有需要请将followlinks设定为true
用root,dirs,files三个变量遍历目录的的目录层级,目录层级的子目录,目录层级下的文件
for root,dirs,files in os.walk(r'd:\\test2',topdown=False):
root:表示当前遍历到哪一级目录了,目录的名字是谁
dirs:表示root下有哪些子目录
files:表示root下边有几个文件
topdown=False:
代码:
#encoding=utf-8
import os
r=os.walk('d:\\test2',topdown=False)
for i in r:
print i
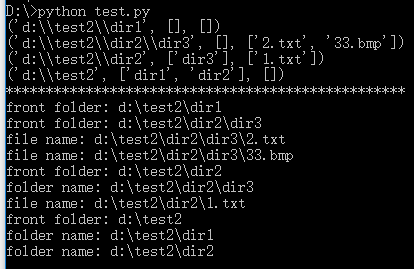
print "*"*50
for root,dirs,files in os.walk('d:\\test2',topdown=False):
print "front folder:",root
for name in dirs:
print "folder name:",os.path.join(root,name)
for name in files:
print "file name:",os.path.join(root,name)
结果:
topdown=True:
代码:
#encoding=utf-8
import os
r=os.walk('d:\\test2',topdown=True)
for i in r:
print i
print "*"*50
for root,dirs,files in os.walk('d:\\test2',topdown=True):
print "front folder:",root
for name in dirs:
print "folder name:",os.path.join(root,name)
for name in files:
print "file name:",os.path.join(root,name)
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号