浅析Base64
什么是Base64
base64是一种使用64个可见字符来表示二进制数据的方法。因为log_{2} {64}=6 ,以6位为一个单元,表示为一个可见字符。二进制数据每3个字节为一组,共24位,用4个可见字符表示。‘A’-‘Z’,‘a’-‘z’,‘0’-‘9’一共62个字符,剩下2个字符在不同系统中表示不一样。
base64对照表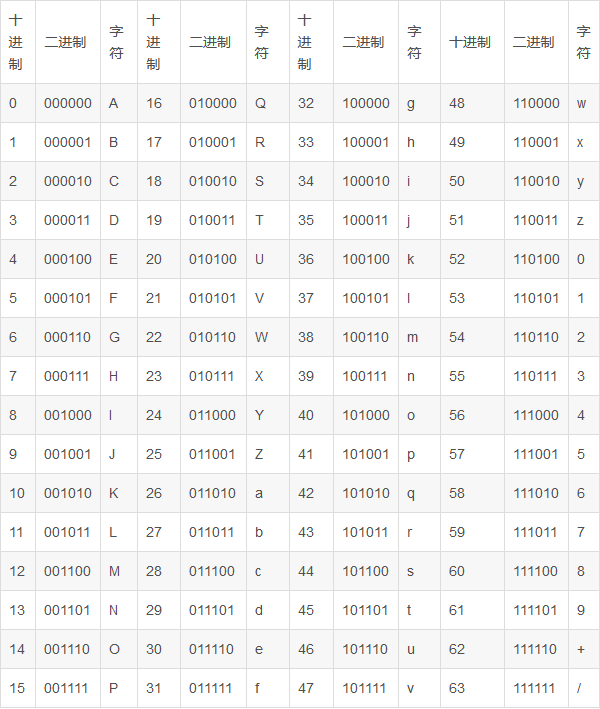
示例说明
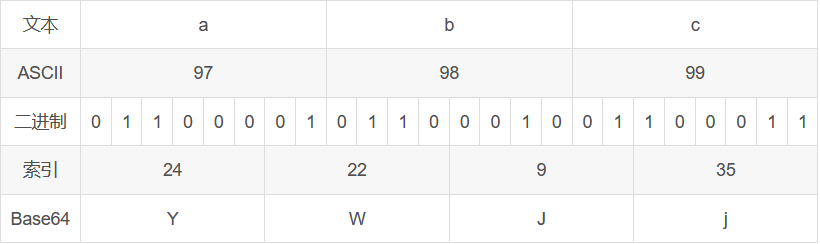
以字符串"abc"为例:
二进制表示为 01100001 01100010 01100011
6个字节为一组011000 010110 001001 100011 ,一共4组
将分组后的二进制转换为十进制,在对照表中找到对应的字符,即可得到编码结果YWJj。
如果出现要编码的字节数不能被3整除,多出来1个或者2个字节,这时候就需要额外处理.
先用"0"在二进制形式下补足,然后进行base64编码,最后在编码结果后添加1个或者2个"=",以表示补充的字节数.
多2个字节的情况,以字符串"ab"为例
补足0之后编码结果为YWI,因为差一个字节被3整除,因此添加1个"=",最终的编码结果就为YWI=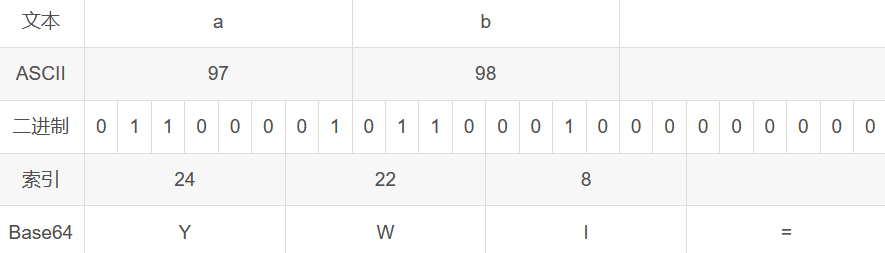
代码实现
/*
* Copyright (c) 2012, 2016, Oracle and/or its affiliates. All rights reserved.
* ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms.
*/
package java.util;
import java.io.FilterOutputStream;
import java.io.InputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
/**
* This class consists exclusively of static methods for obtaining
* encoders and decoders for the Base64 encoding scheme. The
* implementation of this class supports the following types of Base64
* as specified in
* <a href="http://www.ietf.org/rfc/rfc4648.txt">RFC 4648</a> and
* <a href="http://www.ietf.org/rfc/rfc2045.txt">RFC 2045</a>.
*
* <ul>
* <li><a name="basic"><b>Basic</b></a>
* <p> Uses "The Base64 Alphabet" as specified in Table 1 of
* RFC 4648 and RFC 2045 for encoding and decoding operation.
* The encoder does not add any line feed (line separator)
* character. The decoder rejects data that contains characters
* outside the base64 alphabet.</p></li>
*
* <li><a name="url"><b>URL and Filename safe</b></a>
* <p> Uses the "URL and Filename safe Base64 Alphabet" as specified
* in Table 2 of RFC 4648 for encoding and decoding. The
* encoder does not add any line feed (line separator) character.
* The decoder rejects data that contains characters outside the
* base64 alphabet.</p></li>
*
* <li><a name="mime"><b>MIME</b></a>
* <p> Uses the "The Base64 Alphabet" as specified in Table 1 of
* RFC 2045 for encoding and decoding operation. The encoded output
* must be represented in lines of no more than 76 characters each
* and uses a carriage return {@code '\r'} followed immediately by
* a linefeed {@code '\n'} as the line separator. No line separator
* is added to the end of the encoded output. All line separators
* or other characters not found in the base64 alphabet table are
* ignored in decoding operation.</p></li>
* </ul>
*
* <p> Unless otherwise noted, passing a {@code null} argument to a
* method of this class will cause a {@link java.lang.NullPointerException
* NullPointerException} to be thrown.
*
* @author Xueming Shen
* @since 1.8
*/
public class Base64 {
private Base64() {}
/**
* Returns a {@link Encoder} that encodes using the
* <a href="#basic">Basic</a> type base64 encoding scheme.
*
* @return A Base64 encoder.
*/
public static Encoder getEncoder() {
return Encoder.RFC4648;
}
/**
* Returns a {@link Encoder} that encodes using the
* <a href="#url">URL and Filename safe</a> type base64
* encoding scheme.
*
* @return A Base64 encoder.
*/
public static Encoder getUrlEncoder() {
return Encoder.RFC4648_URLSAFE;
}
/**
* Returns a {@link Encoder} that encodes using the
* <a href="#mime">MIME</a> type base64 encoding scheme.
*
* @return A Base64 encoder.
*/
public static Encoder getMimeEncoder() {
return Encoder.RFC2045