机器学习三--各种差
假设有如下未知的曲线(用虚线画出表示我们并不真正清楚该曲线的具体方程),因为未知,所以下面称为“上帝曲线”。在“上帝曲线”的附近会产生一些随机数据,这就是之后要用到的数据集:
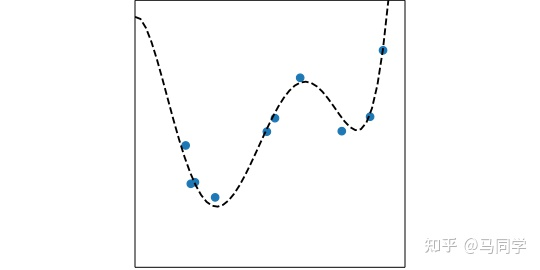
1 “偏差”
我们可以选择不同复杂度的模型来拟合该数据集,比如线性回归,或者多项式回归:
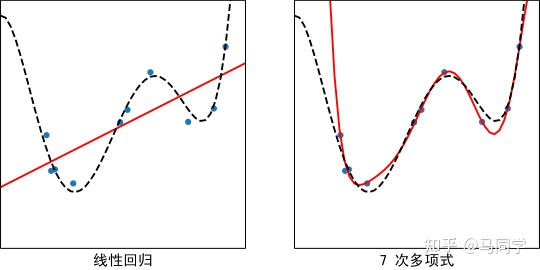
可以看到线性回归比较简单,和“上帝曲线”相差较大,也就是“偏差”较大。而多项式回归河以较好的拟合“上帝曲线”,所以说该模型的“偏差”较小。
2.“方差”
数据集是有随机性的,除了上一节使用的数据集外,我们还可能得到如右侧这样新的数据集:
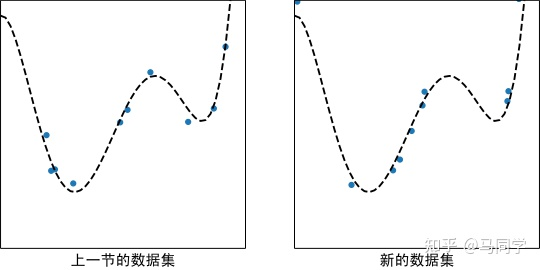
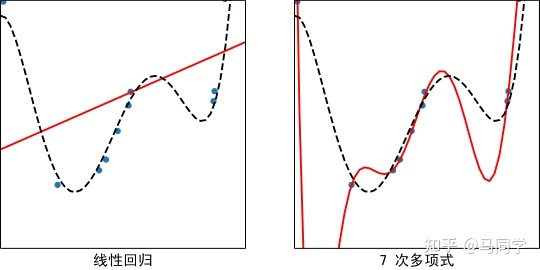
在新的数据集上当然也可以运用线性回归,或者多项式回归:
3 “欠拟合”和“过拟合”
综上,可以知道“偏差”和“方差”对机器学习的影响是:
(1)“欠拟合”︰较简单的模型“偏差”较大,不能对数据集进行很好的拟合,从而与“上帝曲线”相差较大,这在机器学习中称为“欠拟合”。解决方案是选择“偏差”小的模型,即复杂度高的模型。
(2)“过拟合”︰复杂的模型,可以较好地拟合当前数据集,但由于“方差”较大,反而和“上帝曲线”相距较远,这在机器学习中称为“过拟合”。解决方案是选择“方差”小的模型,即复杂度低的模型。
所以我们要选择恰当的复杂度的模型,其“偏差”和“方差”也都适度,才能“适度拟合”:

