
change buffer
1.在业务中已经去报数据唯一的情况下 ,是创建唯一所以还是普通索引?
2.唯一索引和普通索引读取的区别
唯一索引读取流程
1.在内存中找到改数据页,如果没有则去磁盘中加载
2.读取到改行数据立即返回
普通索引读取流程
1.在内存中找到改数据页,如果没有则去磁盘中加载
2.读取下一行数据,判断是否符合条件,一直到key值变化
3.返回
因为索引的有序性,在加载到内存中的数据页找到满足条件的key 几率很大,所以两者的区别不大
3.唯一索引和普通索引写的区别
唯一索引写流程
1.读取数据页 如果已经存在该条记录 只是进行更改,则把数据页读到内存进行更改
2.如果索引中不存在该key值,需要把整个索引树加载到内存中,进行遍历确认没有重复的key值,再进行增加
普通索引写流程
1.查找数据页,如果已经在内存中则直接更改内存中的数据
2.如果内存页没有在内存中 则把更新逻辑写到change buffer中
因为唯一索引存在比对校验key的唯一性的步骤,所以需要把数据页加载到内存中,增加磁盘io 无法使用change buffer,相比较而言 唯一索引的写操作有可能引发oom
4.什么是change buffer
- 是buffer pool中的一块空间;
- 查看change buffer 占buffer pool 的空间比例:show variables like '%innodb_change_buffer_max_size%';
- 查看change buffer 的权限 show variables like "innodb_change_buffering"; all (insert delete update)、 none(没有权限)、 inserts 、deletes、purges
- 记录的是数据更改的逻辑;
- 是持久化的,内存中有拷贝,磁盘中也有记录;
- 针对二级索引的非猥琐索引,因为唯一索引需要把数据加载到内存中进行比较唯一性,没有要使用
- 在聚簇索引上还是正常更新的,(不然更新完语句的 change rows:1 哪里来的 ) 只是缓存了对二级索引的更新
- 将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge
- merge触发的时间:定期触发、数据被访问的时候、正常关机前;
5.change buffer 和redolog的区别
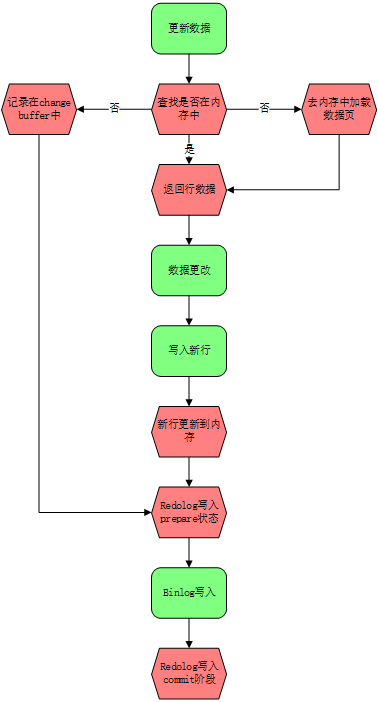
redo log 主要节省的是随机写磁盘的 IO 消耗(转成顺序写),而 change buffer 主要节省的则是随机读磁盘的 IO 消耗。
6.merge 的执行流程是这样的:
- 从磁盘读入数据页到内存(老版本的数据页);
- 从 change buffer 里找出这个数据页的 change buffer 记录 (可能有多个),依次应用,得到新版数据页;
- 写 redo log。这个 redo log 包含了数据的变更和 change buffer 的变更。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号