
学习曲线
Validation Set和Training Set,前者是用来验证的,后者是用来学的。
其实通过代码可以理解一下这两个数据集合:
1 from sklearn.metrics import mean_squared_error 2 from sklearn.model_selection import train_test_split 3 def plot_learning_curves(model, X, y): 4 X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2) 5 train_errors, val_errors = [], [] 6 for m in range(1, len(X_train)): 7 model.fit(X_train[:m], y_train[:m]) 8 y_train_predict = model.predict(X_train[:m]) 9 y_val_predict = model.predict(X_val) 10 train_errors.append(mean_squared_error(y_train_predict, y_train[:m])) 11 val_errors.append(mean_squared_error(y_val_predict, y_val)) 12 plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train") 13 plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")
通过for语句里面可以看到,y_train_predict其实是predict那个X_train的一个子集,作为y_train_predict则是对这个子集的一个预期,那么在计算MSE的时候,其实也是针对这个子集的计算,所以出现下面这个图的情况,在开始的时候,sample还比较少,所以预测能够很好地匹配,但是伴随着数量的增多,模型无法很好地预期,所以MSE是不断升高,伴随着样本数量的增加,学习模型的完善,错误率将会停留在一个水平上;
对于y_val_predict,你会发现他每一次的predict都是X_val的全集,这代表他是用validation的全集在测试当前学习的模型;所以经历了下面图形中蓝线的过程,模型不完善,所以,你会看到MSE非常高,但是伴随着样本的增加,模型的完善,MSE逐渐趋于一个合理的范围。
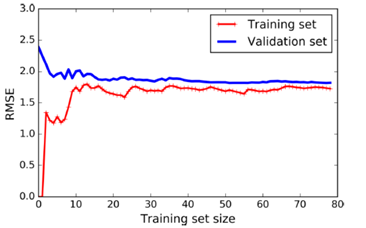
通过这张图,我们可以了解到validation set和Trainingset的作用,后者不断增加样本来训练模型;前者是不断的用自己的全集去验证模型;
常见的三种错误:
模型偏差(bias),比如多项式的数据被建模为线性模式;导致的underfit(欠拟合)
变量偏差(Variance),数据的模型有很多维度,这些维度都满足,而且数据量还比较小,这就容易造成overfit(过拟合)
硬性错误(Irreducible Error),这种错误则是由数据的不合法,不统一造成的,唯一的解决办法就是对数据进行清洗。


