
Elasticsearch(四)优化用户体验
改正用户拼写
Term suggester:词项匹配建议;可以通过wiki的插件来下载wiki上面的单词以及短语,来作为你的拼写提示基础仓库;
Phrase suggester:n-gram算法,短语匹配;
Complete suggester:prefix匹配;内置了FST(Finite State Tranduter)数据结构,实现快速检索,自动完成后续字符填充;但是这个在实现层面上,对于输入那些内容需要预先指定好,这个工作量可就有点大了,然后指定output,就是这些指定的内容输入后,将会返回这个指定值,感觉不是很智能。
改善查询流程
这个比较干货的内容,这个环节也会整理出来很多小白问题,也是使用ES的基本功。
首先是一个普通的query,想要查询澳大利亚的一个系统:
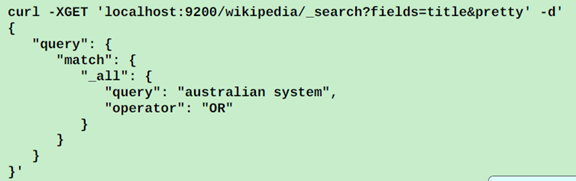
这里_all代表所有的字段,所有的字段来匹配australian system,比如title,text只要匹配就行;这样明显不是我们需要的,我们需要更加精准的控制。
下面进行优化,就是采用多字段匹配;同时指定多字段匹配的权重:
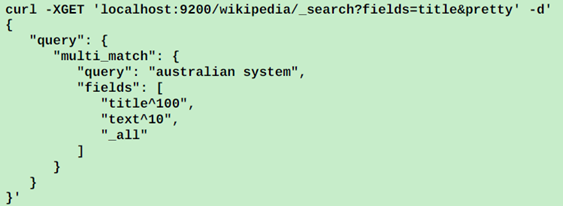
下一步优化是对于短语匹配的优化:
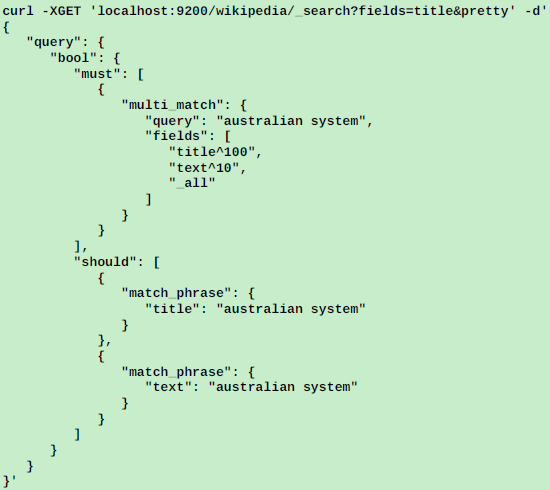
结果如下:
Australian Antarctic Building System
Australian rating system
Australian Series System
…
匹配方面我们做的差不多了,下一步是排序以及过滤问题,我们希望第二个,第三个这种的,能够排在第一个前面;看到这里,想到了通过设定距离来实现,

通过指定了slop来限定了词项间的距离为1,这样查询结果如下:
Australian Honours System
Australian honours system
Wikipedia:Articles for deletion/Australian university system
Australian rating system
…
这里科普一下,must代表必须满足,should代表里面的查询从句只需要自定的数量即可,默认是1个,可以通过mini_should_match参数来指定;不过最终must和should子句的关系是"AND"就是must要满足,同时should中指定从句数量要满足;是"AND"关系。
然后是过滤一下文档,包括从定向页面(wiki的重定向页面并不是最终页面,所以可以忽略)以及特殊页面(通常都是已经删除的页面)
在query同级别,添加一个filter即可,过滤器查询还快,因为没有评分:

最后,我们为match_phrase增加boost,提升他的评分:
替换:

为
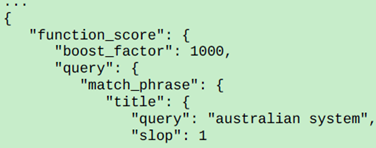

这样title满足短语匹配的文档将会获得高分,作为高分显示出来。
当然,还可以继续优化,比如增加错误拼写文字的建议之类。
回过头来,我们再来梳理一下优化的全过程,首先我们针对一个普通全字段查询:
- 优化为多匹配并指定权重查询,让title的词项匹配满足的拥有高权重;
- 增加了短语匹配,令满足短语的title和text匹配的至少一个;
- 然后增加了距离敏感处理,让短语之间间隔单词为1的数据留下;
- 对于数据进行一下清洗(这一步其实可以提前做),对于redirect和特殊的文档进行过滤;
- 最后,对于短语匹配通过增加boost来为其进行提高分数,提分这种的,是优化的最后一步,对于查询各个环境尽心梳理,哪些条件是可以提高其权重的(第一条是提高词项匹配的权重,这个则是对短语匹配的提高权重);
总结
数据清洗,过滤掉不要的数据(通常最先来做,避免后续查询还要为无效文档计算评分);
词项优化,指定字段的优先级;
短语优化,指定短语匹配,设置距离以及短语权重(boost);


