
ElasticSearch:Lucene和ElasticSearch
Lucene的概念:
关于索引
索引(index)和搜索(搜索),在lucene以及es里面索引是一个动作,即插入动作,包括创建索引以及为索引添加文档;所有则是针对索引(添加)的文档按照评分规则进行查询索引数据,然后计算(比如评分,聚合等),以获取相应数据。
索引相关有文档相关因子(norm):norm是基于文档加权值(boost)计算出来的,和文档一并存储在索引中;
倒排项格式(Post format),到了lucene4.0,提出了解码器架构(codec architecture),让开发者能够自定义索引文件的存储方式;其中Lucenne定义了很多种倒排的格式,以解决不同的问题;
关于文档:
文档,是字段的容器,也是索引和查询操作的单元;
词向量(term vector),是针对每个文档的倒排索引(inverse index);默认是关闭,只是在某些操作比如关键字高亮上面会有这种功能打开;
字段(field),分词之后,也就是将文档进行结构化之后的列信息(元数据);
词项(term),分词之后,结构化之后的列对应的值信息,可以是一个词,也可以是短语;
Doc values:ES的核心是倒排索引,倒排索引的结构是key-value,但是key为文档的field的value,value则是文档列表;对于聚合和切面(该技术已经废弃),是要按照field为单位进行计算,倒排索引只适合于无聚合的查询;对于聚合这类计算是按照field为单位进行计算的,所以有了docvalues这种索引存储结构。我理解她是按照类似于document-field:value这样的梯度结构存储的。

上面这张图基本描述了Lucene里面的基本元素和概念;右侧上半部分是核心对象,字段,词项以及词条;左侧下半部分,实线部分的是原始的文本,文本里面包含的是"词项",然后会被Lucene解析为field,这个解析的过程都是在Lucene中完成的;解析之后,形成文档(document),文档并不只是field的容器,他还记录了词向量,就是一个文档内部的倒排索引,这个索引是啥形式不知道?还有norm,是文档相关因子,是在索引的时候的时候,根据文档加权值(boost)计算得来的(注意这个是创建索引的时候的boost,而不是查询的boost;这个是一个稳定的不变的值,是来自索引之时的)。
查询,包括两部分:词项和操作符(operator),词项就是分词后的value,操作符可以是boolean的操作符(还可以是其他的吗?),AND,OR,NOT,+,-等。这里term还有通过修饰符(modifier)比如*,?等进行修饰;

到此,其实elasticsearch和RDS之间其实有很多共同的地方:其实最终存储的目标都是结构化的数据;但是RDS是输入只能是结构化的数据,ES则可以接收非结构化的数据(文本),ES其实强大的地方就在于可以通过logstash等组件能够基于规则,解析非结构化的数据为结构化的数据,这个也是ES和RDS的本质的区别。
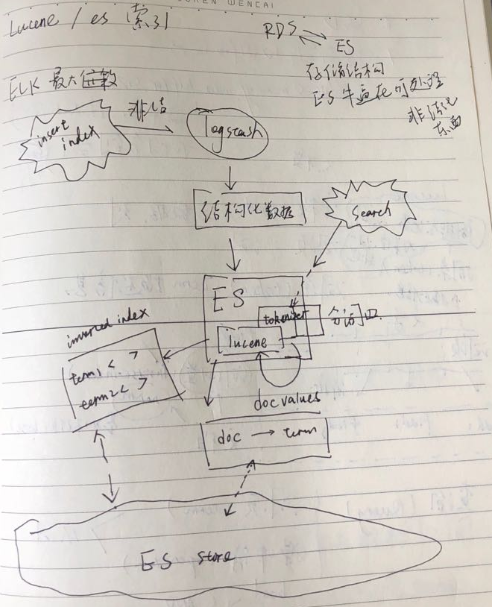
关于解析:
那么这种非结构化解析(analysis)是如何进行的呢?解析数据由三部分组件构成:
分词器(tokernizer):分词器用于对于文字进行分析(结构化处理);
过滤器:过滤器主要用于对于文字的整形和过滤,比如对于文字的大小写处理,移除非ASCII的字符等等,这个和servlet里面的filter很像,层层处理,每一个层不同的职责。
字符映射器(character mapper): 字符过滤器则是在分词前对于文件做一些预处理,比如HTML去掉标签。
ES的基本概念
基本概念:
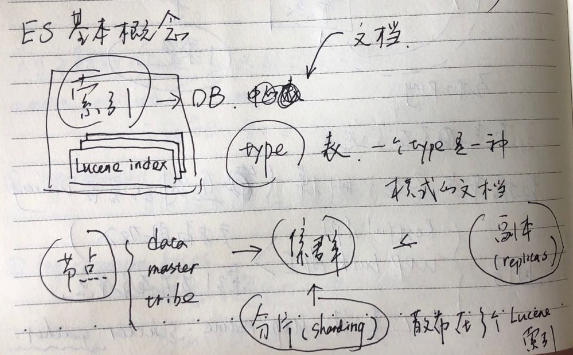
索引,ES的索引和Lucene的索引类似,不过ES的底层是现实多个条Lucene的索引的组合;ES的索引有些像数据库;
类型(type),定义了某种共通文字模式提出来,形成一种type,比如同一个源的日志,他们可以定义为一个type,这个概念比较类似于数据库中表;但是type这个概念未来将会逐渐淡出ES;因为它造成了很多困惑,这是因为在Lucene中只有索引和字段的概念;ES封装的这个type(表),所有的同名字段其实在底层实现是有lucene同一个字段来表示,之时通过另外一个字段来表示该字段属于哪个"type";这也是为什么同一个索引,不同type中的同名field必须要要同类型的原因;所以如果想要将同名字段分开来设定(比如不同的类型),将会导致底层的Lucene的异常;除此之外,type其实是希望同一个索引下,字段类型大致相同的源作为一个type,其实是允许两个源字段有差异,对于我无人有的字段可能处理为""或者NULL(有待确认),这种松制约之下,如果绑在同一个type的源,字段真的差别很大,将会导致稀疏存储,影响Lucene的压缩能力。
所以,其实不同的type可以考虑用不同的index来进行处理,而不是维持这种似是而非的关系型数据库的层级关系。
ES集群:
节点角色:
Data:数据节点;
Master:管理节点;监督各个节点情况,一个集群只有一个主节点(master node),Master管理集群的索引的元数据以及监督各个datanode的存活情况(会ping数据节点以验证存活);创建索引也是发生在主节点,因为只有主节需要记录元数据信息;
Client:用于减轻Data计算量的负载均衡的节点,比如scatter阶段获取数据,汇总过程则可以走的client节点,减轻Data节点压力;
Tribe:用于跨集群查询;但是这里有个坑,即通过Tribe进行查询的时候,尽量避免两个集群有同名索引,因为每次只能返回一个索引;返回哪一个可以是随记,或者是配置prefer集群,但是这大都无法满足需要。
分片(sharding):ES是分布式架构,数据存储也是分布式存储;一个索引在物理上是存储在多个文件中,可以便于并行查询,以及横向扩展;副本(replicas):用于数据备份和负载均衡;
关于集群证明周期:
1. Discovery
首先是集群节点的启动,节点会通过discover阶段向网络中配置的同名集群发送广播信息,告诉大家:我来了,我要加入你们,记住了。
2. Recovery
集群节点启动之后,间互ping以判断对方是否存活,master会ping data节点,如果不通,则会把它给删掉;知道该节点重启,通过discovery节点向master发送通知(其实是广播过程);data节点也会ping master节点,如果不通则需要进行选举,选出一个新的master;
3. Communication
RESTful API
UDP bulk API,但是UDP协议不保证数据传输的准确性;更多的是在集群内部使用(局域网UDP丢包情况较少);
DSL(Domain Specisal Language),就是基于JSON的结构化查询规则;
这里注意对于ES的查询都是连个阶段,Scatter以及Gather,第一个阶段发生在各个索引的物理文件上,然后进入到第二个阶段,对于数据进行汇总处理,可以是Data节点,也可以是Client节点。


