
数据库的聚簇索引和非聚簇索引
华为面试提到了数据库(索引)的数据结构,当时懵逼了,于是调查一下。
首先要讲一下索引的概念;所以其实是独立于数据而存储的;因为索引的用途是查询,所以存储的数据结构是B树(面试之后,我和面试官沟通了一下,数据库存储的数据结构是什么,结果被鄙视了);索引/ 数据的存储一般是以页为单位的;
那么为甚采用B树,而不是平衡二叉树之类的二叉树?因为B树可以有多个孩子,可以控制深度;二叉树则是一个节点只能有两个叶子(孩子)所以深度比较深,如果数据量很大,将会造成IO压力。
聚簇索引和非的本质差别在于叶子节点,首先要明白聚簇索引的意义是按照物理排序来进行索引;因为数据的物理存储只能是一种方式,所以一张表只能有一个聚簇索引;他的数据结构的实现就是树的叶子节点就是是数据本身;这样索引页和数据页就有了耦合;

非聚簇则是有些"逻辑"排序的意味,和数据的物理排序没有关系;那么就需要索引表和数据表进行解耦,这个结构就是叶子节点,叶子节点不再直接指向数据,而是保存了数据的存储指针;
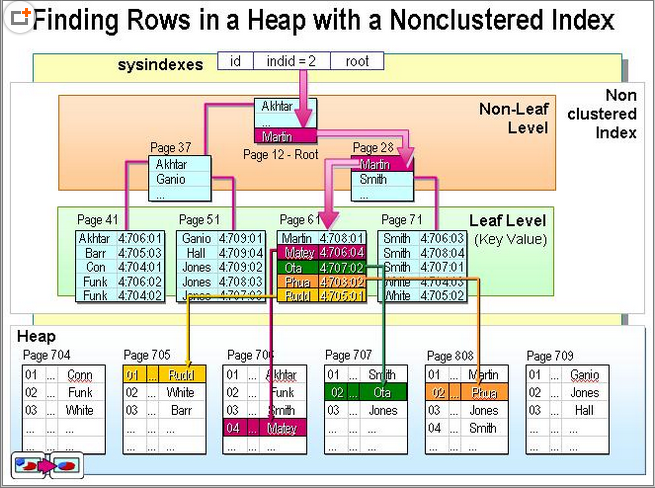
那么为什么讲索引查询是要比数据便利快呢?其实也并不是一定快;如果查询的结果集是比较小的,那么通过索引来查询是比较快的;因为通过索引数据页(可能是多个页)获取数据的位置集合,然后在根据集合来找到对应的数据位置,如果是聚簇索引那么直接就可以访问到数据;但是如果是selec * from tbl这种sql,其实查索引反而要慢;因为这意味着你既要遍历索引页,还要遍历数据页(因为即使你获得了索引位置,但是是几乎所有数据的页内位置,其实就是遍历);所以一般的数据库系统都会自动进行统计数据信息;根据sql语句进行优化查询路径;如果是大量数据的查询直接遍历数据页;但是如果是少量数据,则首先走索引页,然后再走数据页。
那么时候用聚簇索引?对于查询频繁的表,使用聚簇索引,因为可以直接关联到数据,比非聚簇索引少了一层关联关系;如果是增删频发,则要考虑使用非聚簇索引,因为插入一个主键前是要遍历数据的,因为非聚簇索引的叶子节点内容就是索引列的数据,所以只需要遍历索引页即可判断是否有重复;否则聚簇索引每次插入一条记录其实都是需要遍历数据页才能够判断是否重复。
数据因为是以二进制的形式存储,大家都是紧挨着,即使有专用的字段描述一条记录长度,也是要计算,所以遍历这个动作其实就是真的遍历,这个数据文件(页)的走,即使跳过也需要计数,这个过程还是比较耗费时间的。所以很多时候,查索引还是要比查数据文件快;因为遍历索引的页的量一定比遍历数据页要小,获取位置之后可以进行访问;是否走索引的关键就在这里,获取位置之后,如果位置也是海量的,那么走索引的性能提升其实就不是很明显了
参考:
https://www.jb51.net/article/29693.htm


