
spark内存模型
在spark里面,内存管理有两块组成,一部分是JVM的堆内内存(on-heap memory),这部分内存是通过spark dirver参数executor-memory以及spark.executor.memory来进行指定;
另外一部分是堆外内存(off-heap memory),堆外内存默认是关闭,需要通过spark.memory.offheap.enabled以及spark.memory.offheap.size来进行开启以及设置大小;堆外内存在可以实现回收迅速(GC是周期性回收),同时扩大了JVM的可控内存。

内存管理有两类,分别是分别是executor以及storage,前者是在计算的时候shuffle等操作需要占用的内存,后者则是在RDD缓存所占用的内存空间。
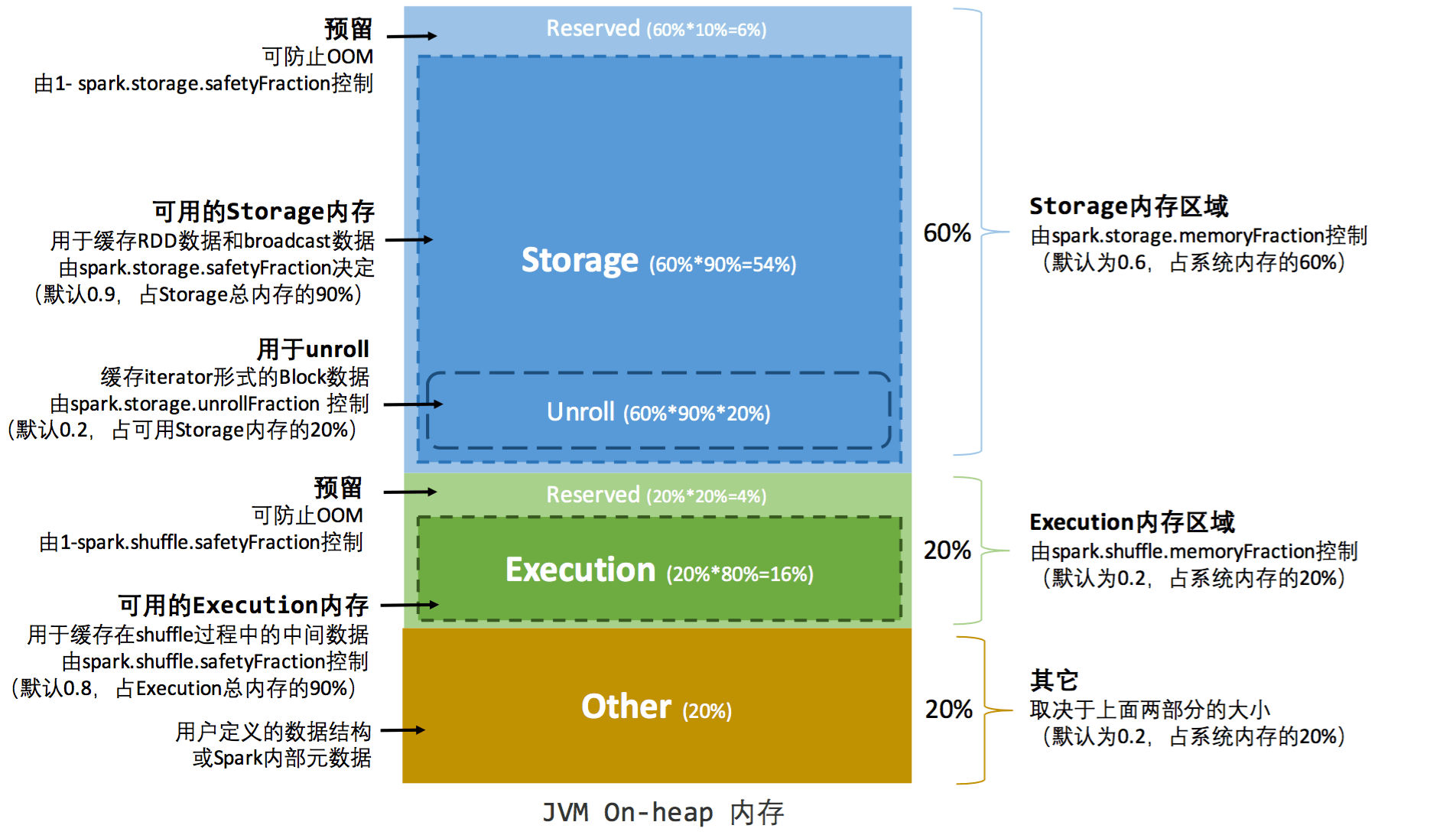
内存分配有两种类型,分别是静态内存分配,和统一内存分配,这两种内存分配类型的差别就在于storage和executor连着内存的分界线,静态内存分配是executor以及storage两者内存是静态的,根据公式计算出来;统一内存管理则不具体做划分根据各自需要;如果两者都不够用,则序列化到内存中;如果某一个方内存不够,总内存还有余富,则自动扩充内存。
对于内存分配之storage域而言,主要是用于RDD的缓存,在缓存的时候可以指定存储策略;另外当RDD被cache之后,存储空间将会有不连续的空间变为连续空间,这个过程称之为unroll;这部分内存的管理是通过 LinkedHashMap来进行空间管理;作为缓存,如果内存空间不够了,将会基于LRU策略进行淘汰(Eviction),对于淘汰的block如果配置缓存策略中包含磁盘策略,则会序列化到物理磁盘进行保存,这个过程称之为落盘(Drop)。
对于内存分配之executor域而言,每个Task将会分配到当前分配大小的[1/2N~1/N](这里强调当前是因为如果分配类型是统一内存管理将会动态变化)大小的空间,executor域的内存主要是shuffle使用,这里包括了两个场景,shuffle write和shuffle read,write占用内存策略比较复杂,如果是普通排序,主要是用的堆内内存,如果是Tungsten排序,则是堆外内存结合堆内内存(如果堆外内存不够)的方式(前提是配置了对外内存);对于shuffle read而言,主要是用的堆内内存。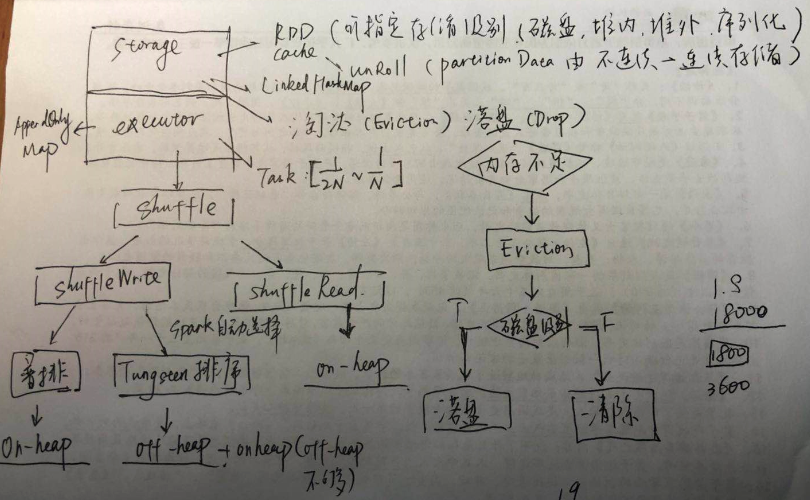
参考:
https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-apache-spark-memory-management/index.html


