什么是spark(二) RDD
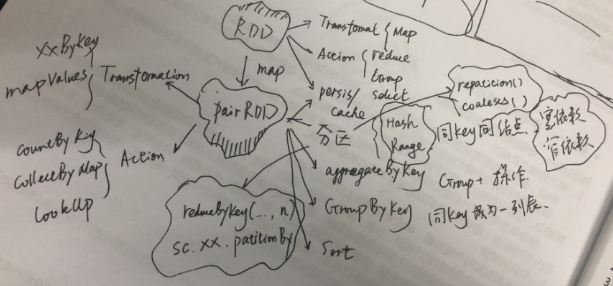
其实你会发现很多概念都是基于RDD提出来的,比如分区,缓存这些操作的对象其实都是RDD;所以不要讲spark的分区,这其实很不专业,分区其实是属于RDD的概念(只有pair RDD才有分区概念)
RDD在(一)已经介绍了RDD,本质上是数据的描述(检索条件)以及处理描述(算法);等待着Action调用之后将会根据数据描述来获取数据,然后再根据算法来处理获取到的数据。简单讲,RDD包含了两部分:一部分是本身定义了数据的描述:比如设置数据源inputRDD = sc.textFile("log.txt")另外一部分RDD提供了对于数据的操作接口:比如filter,union等。
那么在处理数据上面有两类操作,一类是Transformation(map, flatMap);上段提到的数据的描述就是在Transformation中定义,处理描述其实也是在其实在T中描述;当且建档Action类函数被调用了才会触发,比如reduce(),才会执行数据获取和数据处理;所以,spark里面的数据处理其实是一个延迟处理(Lazy Evaluation);一类是Action(reduce,first,take,folder,foreach等);所有的Transformation操作返回的都是RDD,所有的Action返回的是单值或者集合对象;这个是T和A的本质区别,因为T是用于形成DAG,定义了要如何对数据进行准备(transform就是变形的意思,可以理解为对数据的处理),A则是为了获取可操作数据,定了我要什么样的数据;
另外一个角度,Transformation就是map操作,要下放到各个节点进行查询,reduce就是汇聚操作,将各个节点的操作汇聚到一个节点。
还有第三类操作,就是persis/cache;用于避免请求相同数据频繁的获取,可以将某次获取的数据RDD进行缓存。cache尽是内存级别缓存,persis则是提供了多种缓存策略。
RDD的最强大的地方其实还是在于PairRDD,一旦RDD是pairRDD,你的数据的想象空间就大了;首先是要把RDD转换为PairRDD,原生的RDD都是单值的;需要通过map来转为PairRDD,将原生单值数据,提取一部分作为key,单值本身或者单值另外一部分作为value(Map是为了改变世界而生,Map函数将会改变RDD的结构和数据);
PairRDD同样有Action和Transformation;但是Transformation的函数明显增多,一大堆在RDD时代是Action的函数,到了PairRDD时代,增加了“ByKey”,之后变成了Transformation,比如reduceByKey,groupByKey等等。PairRDD的action只剩下了:
1. countByKey;
2. collectAsMap;
3. lookup(key);
到了PairRDD最主要的动作之一就是分区;是的分区只能是PairRDD,因为只有PairRDD才有key的概念,分区的依据就是key(无论是Hash还是Range)。注意数据被某些改变key的操作处理后,返回的RDD可能会丢失分区,比如map;但是XXByKey家族的函数都会维持原始PairRDD的分区,因为这些操作并不改变分区。
分区的概念的本质是将数据按照一定规则进行汇聚,汇聚到一个计算节点(一台主机);一个计算节点可以有多个分区;
与分区设置方式,
1.)在调用Transformation函数的在最后一个参数添加为分区数;这个分区默认的应该是大多数都是Hash(Folder是defaultPartition);会造成数据倾斜(数据分布度不够,导致大量数据集中)。parallelize的默认将会根据集群情况来指定分区个数;但是当你想要避免shuffle操作的时候,分区还是需要你来做。
2)在创建的RDD的时候添加
有了Key之后,就可以做以下事情:
1)按照key来进行聚集(aggregation)操作;按照key进行分组,然后对于同组数据进行运算;返回的是[key, handled value];
2)按照key来进行分组(groupping)操作;按照key进行分组,返回[key,items];如果是分组+运算处理,请采用聚集操作
3)按照key来尽心排序(sorting)操作。