什么是spark(五)Spark SQL
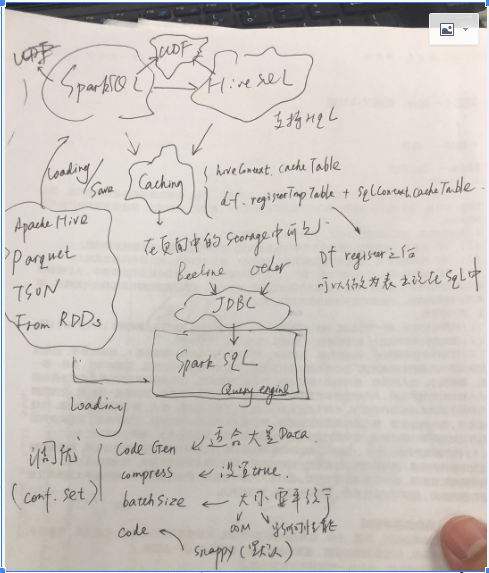
Spark SQL
Spark SQL主要分为两部分,一部分是Spark Sql在scala中直接,使用作为执行层面上的应用,本质上就是生成DAG的另外一种形式;其发生试下Driver中生成;
另外一部分是spark SQL作为查询引擎,供client端通过jdbc来进行调用;
SparkContext和HiveContext是sparkSQL开发索要操作的对象,后者提供了HQL的查询;前者不支持HQL,但是支持普通的SQL;很多针对Hive的一些sql不支持,所以对于Hive表的查询,建议使用HiveContext;基本的思路是首先通过SQL语句获得dataframe,通过dataframe进行注册
除此之外Spark/HivecContext支持Cache;Cache的数据将会在Spark的页面中的Storage中看到;支持UDF(User Define Function)。
SparkSQL同样支持Hive,Parquet,JSON,而且可以通过RDD获得DataFrame;
SparkSQL调优:
1)code gen,适合于大量的数据;
2)compress,对于内存数据进行压缩;
3)batchsize,多少数据进行压缩;
4)codec,压缩的编码;
这些调优参数都是在conf里面设置的。