
什么是spark(六)Spark中的对象
Spark中的对象
Spark的Conf,极简化的场景,可以设置一个空conf给sparkContext,在执行spark-submit的时候,系统会默认给sparkContext赋一个SparkConf;
Application是顶级的,每个spark-submit就是一个application;官网说明:User program built on Spark. Consists of a driver program and executors on the cluster.
每个action(函数)是一个job,action是两个job的分界点;注意,每个action都是会发生一次shuffle,action就相当于map-reduce里面的reduce,会产生一次汇总,也即shuffle;所以可以理解action是一次大的shuffle,这个对应下面的stage,stage也是以shuffle,只不过这个shuffle可能并不是reduce,只是数据因为partition,groupby等导致数据物理位置迁移(重组)等操作,发生了数据转移而已;所以讲,job和stage都是以shuffle为分界点,只不过类型不同而已;官网说明:A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you'll see this term used in the driver's logs.
job是由stage组成,stage其实是和transformation对应;Stage的划分是是否产生了shuffle(shuffle就是一次跨节点IO,详细介绍看“分区”),一个shuffle两个stage的分界点。所以stage是一个说明描述,说明了要处理什么数据;stage其实是一个或者多个链式 transformation组成;每个transformation在执行的时候,将会下放到每个分区中,每个分区创建一个task,这个task将会通过本地的executor(一个worker部署在一台机器,一个worker有一个executor,每个worker下面管理多个partition;官网说明:Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you'll see this term used in the driver's logs.
Job和stage都是全局概念,task是一个局部概念,他的产生是为了执行stage,因为数据是分布在每个分区里面,所以在执行stage,需要读取分区数据并进行处理的时候(执行map,执行filter),task产生了:数据处理就是由task通过Executor跑出来的;官网说明:A unit of work that will be sent to one executor

从sc.textFile到action调用,整个过程都是一个DAG下来,下放到所有的worker节点,然后图中所有的transformation都会被倒叙执行;注意textFile执行其实是spark读取当前节点的的文件,无论是常规文件系统还是Hdfs,都只是workernode自己的数据,所以transformation也是当前节点的数据;这个也是为什么建议worker节点和datanode节点一致的原因;为什么会shuffle?就是因为本地的数据都是局部的,需要将局部数据进行汇总处理,一汇总,就发生了shuffle。
这里还有一个点,就是sc.txtFile之后如果还有partitionBy的话,将会导致数据重排。
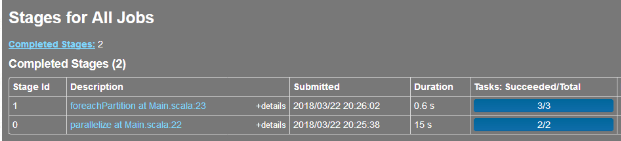
对于job下面的每个stage,并不是一次性把DAG下放到各个分区;而是分批提交给YARN的;因为stage的划分点是shuffle,所以stage是有顺序的;这一点可以通过spark的历史服务页面中的Stages可以看到,每个 stage的提交时间是不一样;这个解释了为什么有的stage是2个task,有的是3个task。第一个stage是执行获取数据,不需要所有的分区参与;第二个stage是foreachpartition,所有的分区都需要参与,所以task数量和分区数一致(3个)
关键性能调优
1. 并行数,本质就是设置分区数,每个分区将会对应一个线程在跑,无论是partitionBy,repatition还是在reduceBy等action函数中指定分区数,亦或是在sparkConf中指定spark.sql.shuffle.partitions,都是可以通过改变分区数来实现并行;强调一点,是该改变,而不是增多;因为并不是分区越多性能越大,关键是利用率;很多时候经过filter之后数据量变小了,分区数减少了反而会提升性能。不用担心分区减少后数据重组导致的损害;在由多变少的场景下,系统开销其实很小的。
2. 序列化,通过:
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
来实现传输过程中对于数据进行序列化传输;KryoSerializer现在已经是spark的标配了(比spark/java原生的序列压缩比率更高,效率更高。
3. 内存管理:
1)RDD的存储,通过persis、cache进行内存存储;可以通过设置memory,disk以及serilize组合来实现减少对内存实现;spark.storage.memoryFraction
2)shuffle and aggregation缓冲区,主要用存放shuffle以及aggregation的临时数据;可以通过调整spark.shuffle.memoryFraction来调整占用内存比例;
3)用户代码
默认60%的JVM堆栈分给RDD,缓冲区和用户代码各占20%;可以根据场景需要来调整分配比例;
对于RDD存储的优化可以通过memory+disk+serial组合来对减少内存的使用;序列化(serialize,将多个对象进行合并)可以有效减少GC的次数,因为JVM在回收的时候看的是堆栈对象的数量,而不是大小;缺点是因为存在序列化和反序列化,损失一些性能。
4. 硬件
1)增加内存,执行的时候通过增加--executor-memory以及--executor-cores来提升性能;但是不能超过64G,否则GC的回收会导致长时间停机;
2)增加硬盘,配置spark的存储路径分散在各个硬盘上面呢,这样可以实现多个硬盘并发读取硬盘数据供应用处理,提升吞吐率;
spark官网介绍调优:http://spark.apache.org/docs/latest/tuning.html#data-locality


