


Spark Shuffle
Shuffle基本流程
spark shuffle从总体来讲分成两部分,shuffle write和shuffle reader,如下图所示,看到这里,就明白了为什么spark性能优化的时候建议宁可broadcast也不要shuffle,broadcast好歹还是内存操作,网络上大一点压力(每个节点都要病毒式传播),shuffle可是真金白银的写入hdfs,hdfs可以还要复制和备份的哦。
spark shuffle的理解要从他的语境理解,即放在spark的全流程,下图简单的描述了spark的基本过程:mapper通过算子执行,访问数据源(可以是DB,hdfs,Hbase...)获取数据,之后通过shuffle writer写入到HDFS完,Shuffle Write其实做的最重要的一点是分区。
完成之后,stage2 reducer将会通过shuffle reader来获取数据(通信技术有Socket和Netty两种),Reader将会访问Driver的MapOutputTrackerMaster获取数据存放的位置(Block地址),获取到了数据,获取机制是每次拉取一定大小数据(默认是32K),拉取过来的数据放在指定区域,spark的内存区域是有一部分专门用于获取shuffle数据的Cache(在Spark内存模型中,定义了一块Execution区域,默认是JVM内存的20%),这里注意Reducer的处理并不是数据全部取完之后才进行处理,而是便Fetch,边处理;当数据量大于Cache大小将会保存到本地硬盘。

Stage和Shuffle
简单讲,Stage的划分就是为了Shuffle,Stage是因为Shuffle的存在而存在的,因为分布式的数据操作必然有数据的传输。但是这种传输有两种,一种是最后阶段的传输,通常我们将的action操作;但是很多的shuffle是发生在transformation操作。
Spark Shuffle历史
理解spark的shuffle细节,参看了一些资料,从历史的演化来理解还是比较好,一种成长感。
Hash Shuffle V1
spark第一代shuffle,write和reader部分架构确立,但是writer写文件的模式是每个task都会生成和reducer数量相同的文件,这意味着生成的文件总数为Num(total_task) * Num(total_reducer),如果500个task,10个reducer,那么生成的文件总数为500 * 10,生成文件量很大。
在shuffle writer之前,存储在内存里面的数据结构是按照Bucket来划分的,Bucket对应的未来的Reducer,是对于分区的(每个区对应一个Reducer)抽象,像一个篮子,每个Task都有自己的篮子,获取到了数据,取出key进行Hash,然后基于Hash值和Reducer的数量,把数据都放在对应的篮子中;Bucket里面的数据待数据处理完成后是要刷到HDFS的一个文件中进行存储。

之所以称之为Hash Shuffle,是因为生成文件的时候是按照Hash来对数据进行分区,然后根据Reducer的数量来组织文件数据,Hash成为了Shuffle主要处理的内容。
因为文件量/数据量很大,在Reducer端读取数据数据的时候,采用的HashMap数据结构,经常会因为文件量过大而导致了OOM。
Hash Shuffle V2
到了一代shuffle,主要是文件写入的模式发生了变化,之前是每个task都写入一个新的文件,这一代进化为同一个executor下面,各个task写入同一个文件,Num(Executor) * Num(total_reducer),基于此,spark提出了consolidation这个概念(通过设置spark.shuffle.consolidation=true,此配置默认为false),比如还是500个task,分散到10个Executor(每个Executor50个task),文件总数就是10 * 10个,文件量比V1时代小了很多了。
因为Reducer端读取仍然采用HashMap数据结构,还是会经常会OOM(文件虽然少了,但是数据量还是那么大);所以说Hash Shuffle V2优化的是Writer端
Sort Shuffle V1
后来spark借鉴了MapReduce的Shuffle,就是在对数据进行shuffle的时候,将数据进行排序,这个优势主要是在于减轻了Reducer的压力,否则Reducer进行的全局重排,如果在map阶段借助各个Map节点的算力现在本地进行排序,然后再在reducer进行全局排序的时候就轻松很多了。比如我们将ReduceByKey要比GroupByKey要快,就是因为前者在Map端将会通过SortBaseShuffleWrite对数据进行排序(后面将会介绍除了SortBase还有BypassMerger方式,不会对数据进行排序)
从sort shuffle开始,开始有了spill即落盘,上面描述的数据的排序其实发生在spill的时刻;这里有了"file segment"的概念,落盘文件结构是两层次,首先是按照分区进行排列出来一块一块的FileSegment,在FileSegment内部是按照key进行排序;生成数据文件之外还有维护一个Index文件,这个index文件用于指向各个分区在文件中的偏移量,这样在reducer阶段读取分区数据的时候根据这个index文件即可;
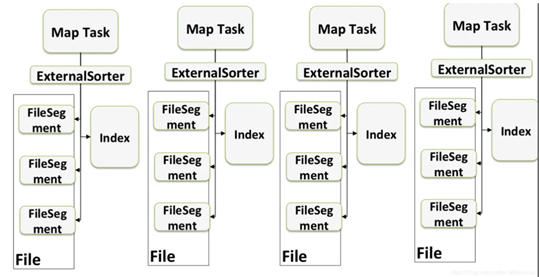
Spill的发生是根据内存中spark的数据量,达到了阈值之后,将会把内存中的数据flush到硬盘中,map阶段数据完成后,将会进行shuffle write,会将各个flush的文件进行整合成一个文件然后存到HDFS中,是的,到了Sort Shuffle每个Exexutor只有一个文件,这样输出的文件总量为Num(Executor) ,比值Hash Shuffle v2有少了一些。
除此之外,在Reducer端也进行了优化,读取数据的结构改为了ExternalAppendOnlyMap,该数据结构首先把数据存在内存中,如果内存不够了会将数据flush到硬盘中,这样就避免了OOM情况,到了Sort Shuffle时代,OOM的问题终于解决了。
Tungsten Sort Base Shuffle
Tungsten期初是spark一个尝试的功能,他使用的堆外内存空间,因为采用的jvm来访问堆外内存,所以又称之为unsafe sort;将数据进行序列化之后(KyroSerial),,所以之后使用序列化之后数据(二进制)进行排序,这里不是使用Java对象,所以JVM的GC压力比较小;使用JVM之外的内存进行排序,这样效率比较高,而且因为序列化以及排序都是在堆外,所以GC压力小了很多,减少了大量的垃圾回收的次数。
这是因为Tungsten的序列化-排序机制,该方式并不适合聚合的算子(无法进行稍微复杂的数据操作),只适合类似于join这类算子,而且分区数一定要小于2^24 -1(这个分区数估计也没谁了,基本都会小于)。
Sort Shuffle V2
到了这一代,Tungsten Sort正是转正,Spark将会自动根据算子来决定是采用Sort Shuffle还是采用Tungsten Sort;同时Hash Shuffle也退出了历史舞台。
虽然HashShuffle退出了历史舞台,但是HashShuffle的模式并没有消失,因为HashShuffle还是有其优势:不需要排序,所以处理的速度还是要比Sort要快;所以Spark提供了ByPassMergeSortShuffleWriter来进行类似于Hash Shuffle的机制,该处理应用在一些不需要排序的场景,比如repartition操作;
BypassShuffle机制和HashSortBaseShuffle基本一致,只是写文件遵循只向一个文件里面写,可以说是把性能推向机制;但是ByPass的shuffle只是适用于Num(Reducer)比较小的场景,因为ByPass在shuffle的全过程是要把所有的文件都打开,如果Reducer太多,对增加本地IO压力,ByPassShuffle的文件数量阈值(Reducer数量阈值)是在spark.shuffle.bypassmergeThreshold属性配置,默认是200。
到了spark2.x时代只有三种Shuffle:排序类,SortBaseShuffleWriter,非排序类,ByPassMergeSortShuffleWriter以及TungstenSortBaseShuffleWriter;非排序优先使用Tungsten类Shuffle。干预shuffle种类的选择,请看下图:

spark的shuffle技术历史节点
- Spark 0.8 及以前 Hash Based Shuffle
- Spark 0.8.1 为 Hash Based Shuffle引入File Consolidation机制
- Spark 0.9 引入 ExternalAppendOnlyMap
- Spark 1.1 引入 Sort Based Shuffle,但默认仍为 Hash Based Shuffle
- Spark 1.2 默认的 Shuffle 方式改为 Sort Based Shuffle
- Spark 1.4 引入 Tungsten-Sort Based Shuffle
- Spark 1.6 Tungsten-Sort Based Shuffle 并入 Sort Based Shuffle
- Spark 2.0 Hash Based Shuffle 退出历史舞台
附录
什么是spark的分区
分区的本质就是将数据,按照key进行汇总,聚类为几部分,便于后面算子的处理;为什么要有分区?其实是为了数据平衡,下一个stage算子也是要分布在几个节点,为了使得每个节点都能够处理差不多数量的数据,所以对数据进行分区。
关于宽依赖和窄依赖的shuffle
跨依赖是指子RDD要依赖于2个以上父RDD分区,因为依赖多个分区,所以就需要进行任务协调,在RDD一定是要等到以来的父RDD的分区都完成了才会尽心数据的fetch(shuffle read);这种协调(同步)通过各个分区完成后shuffle到datablock的方式解决,父RDD的数据写入到中间存储,子RDD得知父RDD完成后,根据MapOutputTrackerMaster里面记录的信息获取即可。
所以shuffle的本质并不是跨节点/跨进程,本质其实是任务协调的一种实现。
关于HBase
HBase和spark所负责的阶段式不一样的,HBase存储主要是map的查询(获取数据)阶段,如果想要在这个阶段性能调优,需要考虑到HBase的设计,优化,比如rowey设计,文件split,merge等等,这些操作其实目的都是让search阶段(map阶段)高效,迅速以及自身文件存储性能(比如memstore);Spark的shuffle则是负责数据已经获取之后,如何操作更加快捷。所以他们所起到的作用是不同的阶段。
Hadoop MapReduce
Spark的Shuffle是在Hadoop的MapReduce之后,很多机制都是参考了MapReduce的机制,比如Sort Base Shuffle,这里简单介绍一下MR的Shuffle以及他和Spark Shuffle的异同点。
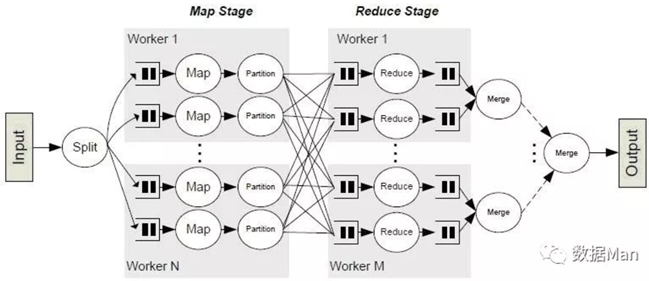
从上图可以看到,MR的全流程,首先Input即算子下发各个worker节点(这个相当于Spark的Executor),然后是Map的stage(这个和Spark的Stage基本一致),这里划分为两个阶段:
spill过程:获取数据,在获取数据的过程中首先将数据放置到缓存中(默认48M),缓存满了后就会将文件flush到本地存成文件,注意在spill前将会对数据进行一次排序,排序完成后再写入到磁盘中;
merge过程:map task把数据处理完成后,会将spill的数据文件进行合并;在文件合并的过程,将会进行全局的排序;并基于Hash算法以及Reducer数量,进行分区操作;然后Spill写入到本地文件,数据全部处理完成后,将会进行文件Merge(和Sort Shuffle的机制基本一致),然后写入到HDFS中;
在reducer端同样经历两个过程:
copying阶段:通过访问TaskTracker获知map阶段存储的文件路径,然后通过Http协议进行数据拉取。(这里有区别,spark采用的socket和netty框架,效率比MapReduce要高)拉取的过程中,和spill阶段一样,会将充满的缓冲区数据flush到硬盘中;
merge阶段:reducer的数据处理完成后,将会对于数据进行合并以及全局reducer算子处理,完成后,shuffle到合并节点
spark和mapreduce处理有如下区别:
Spark的DAG模式提供了高层数据操作处理,可以实现比MR更加复杂操作,比如coGroup,可以合并多个不同源的Map数据。而mapreduce的机制只能处理同一个来源的数据;
从shuffle处理多样性而言,spark更加丰富,spark提供了三种shuffle类型,分别针对不同的场景择优选择,而MR的shuffle则只有一种sort Shuffle
reducer中微妙的差别,Hadoop是等到buffer快满的时候,才进行combin()操作,而spark则是边拉取数据边进行数据立即和内存中已经有的数据reduce算子操作;
参考:
https://www.cnblogs.com/jcchoiling/p/6431969.html
spark shuffle
https://zhuanlan.zhihu.com/p/67061627 历史进程结构来描述spark shuffle,参考此篇博文
https://www.jianshu.com/p/286173f03a0b 此文甚好,图文并茂,我的很多截图就是来自此文
https://www.cnblogs.com/jcchoiling/p/6431969.html stage和shuffle的关系,有此文引起;另外此文有很多spark shuffle的源码的解读,有时间还是应该好好看看
https://www.zhihu.com/question/27643595 mapreduce的shuffle和shpark区别
https://blog.csdn.net/shuimofengyang/article/details/81534069 mapreduce的流程描述参考此文


