
FP-Growth算法
FP-Growth算法的目标是发现模式,其特点就是高效,因为可以通过设置发生频次直接过滤掉一些低频次的元素;而且秉承了和Apriori的思想,对于低频次的元素,其父级和子级的组合都是低频的。
FP-Growth利用的树结构;在发现模式的过程就是一个不断构建树的过程。其核心组成是两部分,一个就是FPTree,另外一个是headTable;我们首先来说一下HeadTable,HeadTable的数据结构是字典,key值是每个单元素(商品),value是一个二元组,分别是这个单品出现的次数以及商品树(FPTree)
下面是TreeNode的结构定义:
1 class treeNode: 2 def __init__(self, nameValue, numOccur, parentNode): 3 self.name = nameValue 4 self.count = numOccur 5 self.parent = parentNode # 上级树信息 6 self.children = {} # 下级(树枝)树信息 7 self.nodeLink = None 8 def inc(self, numOccur): 9 self.count += numOccur 10 11 def disp(self, ind = 1): 12 print (' '*ind, self.name, ' ', self.count) 13 for child in self.children.values(): 14 child.disp(ind + 1)
然后我们再来看一下FPTree,这个Header-FPTree里面将会记录信息和Pattern-FP树还要复杂一些,因为除了使用children字段来记录其孩子节点,还是用了nodeLink字段来记录相同单元的其他子树,也就是说这是一个链式结构,通过一个链,可以把所有的某个单元素的FPTree都串联起来了。如下图所示,S:3其实是两个S相关子树,第一个节点是S:2,第二个是S:1,带箭头的都nodeLink进行链接的;不带箭头(线段)的都是children/parent字段进行关联的。
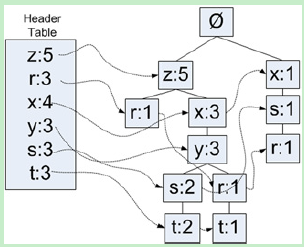
这里有一个概念即使交易,交易的本质是一种商品组成。我们先来一组数据:
1 def loadSimpDat(): 2 simpDat = [['r', 'z', 'h', 'j', 'p'], 3 ['z', 'y', 'x', 'w', 'v', 'u', 't', 's'], 4 ['z'], 5 ['r', 'x', 'n', 'o', 's'], 6 ['y', 'r', 'x', 'z', 'q', 't', 'p'], 7 ['y', 'z', 'x', 'e', 'q', 's', 't', 'm']] 8 return simpDat
这里单个字符就是一个单品,比如'r', 'x'等等;交易,就是simpDat中国每个一维数组,['r', 'z', 'h', 'j', 'p']就被称之为一个交易;那么对于FPG而言,他的目标就是根据交易来进行模式识别。
那么怎么来进行呢?首先就是要构建一颗树。怎么构建,要经历两轮遍历,第一轮遍历是把所有单品的出现频次统计出来,完成第一轮的遍历后,把出现频次第的单品过滤掉,形成一个高频单品的集合;第二轮遍历,才是真正要构建FPTree,在遍历每一个交易的时候,首先把低频单品剔除掉(判断是否在高频单品集合中),这样生成了一个新的交易,只包含高频单品,然后对于新的交易中的单品进行排序;为什么要排序?因为在形成树的时候,z,y,r和r,y,z其实是一棵树,只有排序才可以识别为一棵树,排序的规则就是出现的频度。OK,剩下的事情就是对于新的排过序的交易构建FPTree了(交给updateTree)!在updateTree之前的操作,都是数据处理(清洗)的流程范围,只有到了updateTree才是机器学习的开始。
下面的代码就是创建树的python实现:
1 def createTree(dataset, minSup = 1): 2 # headTable用于保存各个单元素的指针;通过headTable里面的指定项,可以所用到以某个点为起点的路径(树路径) 3 headTable = {} 4 # 第一轮遍历,获取的所有单元素出现的次数 5 # 注意,dataset是一个字典;for语句遍历默认是第一个元素及下面for语句等价于for trans in data.keys() 6 print("开始第一轮遍历,找出发生频率") 7 for trans in dataset: 8 #print("trans:", trans) 9 for item in trans: 10 #print(" item:", item) 11 #print(" dataSet[trans]:", dataset[trans]) 12 # 其实不是很明白为什么要+dataset[trans]? 13 # 首先要明白dataset是干什么的,它是一个商品组合以及一个商品组合的数量,这里就是当前该单品的数量+dataset的数量 14 headTable[item] = headTable.get(item, 0) + dataset[trans] 15 print("第一轮扫描完毕,headTable: ", headTable) 16 # 删除出现次数小于下限的元素 17 for key in list(headTable): 18 if(headTable[key] < minSup): 19 del(headTable[key]) 20 freqItems = list(headTable.keys()) 21 print("第一轮低频次项清理完毕,headTable: ", headTable) 22 print('freqItemSet: ',freqItems) 23 if(len(freqItems) == 0): 24 return None, None 25 # 其实不明白为什么要添加这个None,组成二维数组?第二个元素其实是头结点为该item的树节点(treeNode) 26 # 初始化设置为None,在第二轮处理中会为每个元素创建一个树节点,填充到headTable中来 27 for key in headTable: 28 headTable[key] = [headTable[key], None] 29 retTree = treeNode("Null Set", 1, None) 30 print("开始第二轮遍历,构建FP树(只针对高频元素进行构建FP树)") 31 # 下面开始第二轮遍历,主要是对于高频出现的trans元素进行排序 32 for trans, count in dataset.items(): 33 print(" trans: %s, count: %d" % (trans, count)) 34 localD = {} 35 for item in trans: 36 # 只处理高频元素,低频元素被抛弃;headTable[item][0]是单品,headTable[item][1]则是单品对应的树指针 37 if(item in freqItems): 38 localD[item] = headTable[item][0] 39 if(len(localD) > 0): 40 print(" localD: ", localD) 41 # 前方高能,为什么是p:p[1]?这里p[0]是key,单品名称,p[1]是value,单品的发生的次数; 42 # 这里排序按照单品的发生的次数来进行排序,所以是p[1] 43 orderedItems = [v[0] for v in sorted(localD.items(), key = lambda p:p[1], reverse = True)] 44 print(" 排序后的LocalD: ", orderedItems) 45 # 第一次调用updateTree的时候,传进去的inTree就是根节点:NullSet 46 updateTree(orderedItems, retTree, headTable, count) 47 48 return retTree, headTable
那么,如何连构建FP树呢?首先创建一个树的根节点,Null Set,这个在数据处理环节已经创建了;我们拿三组数据来剖析一下:
1 ['z'] 2 ['z', 'x', 'y', 'r', 't'] 3 ['x', 's', 'r']
Z节点在是第一个单品毫无疑问,直接在NullSet节点下面创建创建树节点z;headTable也没有z树记录(数据处理节点只是在headTable中创建了key以及出现频次,tree信息是None),于是在headTable对应的key值上填充一下创建的树信息;下面就是第一个交易走完之后,FPTree的样子
1 Null Set 1 2 z 1
第二个交易还是z开头,z已经在NullSet中存在,OK,那么直接z+1即可(如下图所示);
Null Set 1
z 2
然后是x节点,x是z节点的下级节点,z子树是新创建的,也是没有x节点,所以直接创建,后续的y,r,t都是类似的,所以第二个交易处理完成后,形成了如下的FP树:
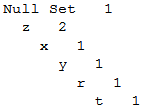
再看第三个交易(['x', 's', 'r']),x节点,FPTree的NullSet节点中没有,创建之;x节点在headTable中已经有了定义,所以需要在headTable中ke=x的树的叶子结点添加一个nodeLink,Link到这个树。注意,回看第二个交易中,z也是二次出现,却并没有更新headTable,这是肿么回事?这是因为该z节点并没有创建新的子树,因为第一轮NullSet根节点已经创建了z树,所以z2没有创建子树,而是重用了z1的树,故不需要更新headTable的数据;然后x的父级节点是z树,z树并没有x节点,所以创建了一个新的x树节点,有新的树节点创建就需要更新headTable中的树信息了。
如果未来有一个交易是z,x....那么同样的不需要更新headTable数据,已经z树节点已经有了x树节点,直接+1即可;明白了这个逻辑,你就会明白FPG是如何来构建"模式"了。
我们继续看第三个交易,第二个节点是s,在x节点下创建s树节点,同时将创建的s树节点同步到headTable中;第三个节点是"r",s树节点下创建r节点,但是r已经在headTable中r的树信息了(第二个交易中),所以需要为headTable中的r树追加一个该新建树的nodeLink。
以此类推。
下面就是实现:
1 # 更新树信息 2 # items是一次商品组合,或者说一种模式 3 def updateTree(items, inTree, headerTable, count): 4 print("组合模式为:", items, "inTree_name: %s, inTress: %s" %(inTree.name,inTree.disp())) 5 # 如果单项已经存在于树中,那么直接添加数量即可 6 if(items[0] in inTree.children): 7 print(" 元素:%s已经在树中,直接添加数量即可" % (items[0])) 8 inTree.children[items[0]].inc(count) 9 # 如果FP树中并没有指定的单元素,那么就创建一个并作为该树的子节点 10 else: 11 inTree.children[items[0]] = treeNode(items[0], count, inTree) # 创建树节点 12 print(" 元素:%s没有在树中...为树创建子节点: %s" % (items[0], inTree.disp())) 13 # 如果头结点记录表中没有该节点的子树信息(children),那么就将创建的treeNode(子树)赋值过去 14 if(headerTable[items[0]][1] == None): 15 print(" headTable中没有节点%s的记录,创建子树" % items[0]) 16 headerTable[items[0]][1] = inTree.children[items[0]] 17 # 如果之前的遍历过程中已经创建了该节点的children信息,则对children进行遍历到叶子结点,增加了子树(linkNode)几点 18 else: 19 print(" headTable中已经有了该节点:%s的记录信息,更新headerTable中树信息" % items[0]) 20 updateHeaderTable(headerTable[items[0]][1], inTree.children[items[0]]) 21 # 逐个元素进行树的“生长”和“创建” 22 if(len(items) > 1): 23 print(" 模式(%s)中还剩余单个素树 > 1,去掉items[0](%s)继续更新" % (items, items[0])) 24 updateTree(items[1::], inTree.children[items[0]], headerTable, count) 25 # 遍历树一直到叶子结点,然后为叶子节点增加一个“子树”(叶子节点将不再是叶子节点) 26 27 # 更新headTable中的树信息,即在叶子结点中增加一个nodeLink指向targetNode 28 def updateHeaderTable(nodeToTest, targetNode): 29 while(nodeToTest.nodeLink != None): 30 nodeToTest = nodeToTest.nodeLink 31 32 nodeToTest.linkNode = targetNode

