


springboot整合持久层
1、整合mybatis
这里以多数据源为例
第一步创建springboot时,选上mybatis依赖
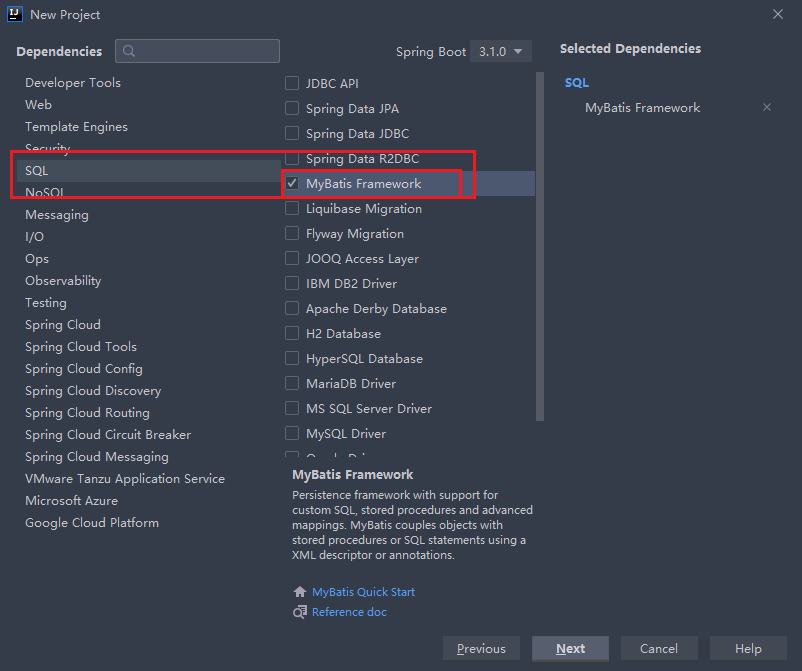
在添加数据库驱动依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
第二步在配置文件中进行配置数据库信息
spring.datasource.one.jdbcUrl=jdbc:mysql:///mybatis?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false
spring.datasource.one.username=root
spring.datasource.one.password=123456
spring.datasource.two.jdbcUrl=jdbc:mysql:///mybatis?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false
spring.datasource.two.username=root
spring.datasource.two.password=123456
第三步在配置类中进行配置数据源
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource.one")
DataSource dsOne(){
return new HikariDataSource();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.two")
DataSource dsTwo(){
return new HikariDataSource();
}
}
同样通过 HikariDataSource 来创建数据源
第四步也是在配置类中对 mybatis进行配置
@Configuration
@MapperScan(basePackages = "com.xrr.mybatis.mapper1",sqlSessionFactoryRef = "sqlSessionFactory1",sqlSessionTemplateRef = "sqlSessionTemplate1")
public class MybatisConfigOne {
@Autowired
@Qualifier("dsOne")
DataSource ds;
@Bean
SqlSessionFactory sqlSessionFactory1(){
SqlSessionFactory sqlSessionFactory = null;
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(ds);
try {
sqlSessionFactory = bean.getObject();
} catch (Exception e) {
e.printStackTrace();
}
return sqlSessionFactory;
}
@Bean
SqlSessionTemplate sqlSessionTemplate1(){
return new SqlSessionTemplate(sqlSessionFactory1());
}
}
在类中需要配置 SqlSessionFactory 的bean 与 SqlSessionTemplate 的 bean,
其中SqlSessionTemplate是Mybatis—Spring的核心,是用来代替默认Mybatis实现的DefaultSqlSessionFactory,也可以说是DefaultSqlSessionFactory的优化版,主要负责管理Mybatis的SqlSession,调用Mybatis的sql方法。
然后在类上添加 @MapperScan 注解,在其中添加 包扫描,sqlsession、SqlSessionTemplate即可。
@MapperScan是属于 mybatis-spring中的。
当只有一个数据源时,只需在启动类上添加 @mapperScan 注解即可
2、整合Spring data jpa
介绍
JPA是ORM规范,jpa是对Hibernate、TopLink的封装(mybatis是半自动的orm框架,spring data jpa不对其封装),这样的好处是开发者可以面向JPA规范进行持久层的开发,而底层的实现(Hibernate对数据库进行操作)则是可以切换的。Spring Data Jpa则是在JPA之上添加另一层抽象(Repository层的实现),极大地简化持久层开发及ORM框架切换的成本。
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。Spring Data JPA不需要过多的关心Dao层的实现,只需关注我们继承的接口,按照一定的规则去编写我们的接口即可,spring会按照规范动态生成我们接口的实现类进行注入,并且实现类里包含了一些常规操作的方法实现。如果使用JPA提供的接口来操作ORM框架,可以不写任何实现就能对数据库进行CRUD操作,还可以进行简单的分页,排序操作。
即 jpa 是规范,而 hibernate 是 jpa 的体现
第一步添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
第二步在配置文件中进行数据库配置
spring.datasource.password=123456
spring.datasource.username=root
spring.datasource.url=jdbc:mysql:///springboot?useUnicode=true&characterEncoding=UTF-8
spring.jpa.database=mysql
spring.jpa.show-sql=true
spring.jpa.database-platform=mysql
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
第三步,创建实体类
@Entity(name = "t_book")
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "b_name")
private String name;
private String author;
}
首先@Entity注解表示这是一个实体类,那么在项目启动时会自动针对该类生成一张表,默认的表名为类名,
@Entity注解的name属性表示自定义生成的表名。@Id注解表示这个字段是一个id,@GeneratedValue注解表示主键的自增长策略,对于类中的其他属性,默认都会根据属性名在表中生成相应的字段,字段名和属性名相同,如果开发者想要对字段进行定制,可以使用@Column注解,去配置字段的名称,长度,是否为空等等。
接下来创建一个 dao,继承 JpaRepository
/**
* JpaRepository<Book,Long>
* 第一个泛型:需要处理的实体类
* 第二个泛型:主键
*/
public interface BookDao extends JpaRepository<Book,Long> {
}
在 JpaRepository类中定义了一些查询、删除、增加等的方法。而其之所以方便是因为其定义了分页操作:
@Test
public void test2(){
PageRequest pageRequest = PageRequest.of(1, 3, Sort.by(Sort.Order.asc("id")));
Page<Book> page = bookDao.findAll(pageRequest);
System.out.println("总页数 = " + page.getTotalPages());
System.out.println("总记录数 = " + page.getTotalElements());
System.out.println("每页记录数 = " + page.getSize());
System.out.println("查到的数据 = " + page.getContent());
System.out.println("是否有下一页 = " + page.hasNext());
System.out.println("是否有上一页 = " + page.hasPrevious());
System.out.println("是否首页 = " + page.isFirst());
System.out.println("是否最后页 = " + page.isLast());
System.out.println("当前页码 = " + page.getNumber());
System.out.println("获取当前页的记录数 = " + page.getNumberOfElements());
}
查询规范;
- 按照 Spring Data 的规范,查询方法以 find | read | get
- 涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性以首字母大写
支持关键字查询如下;
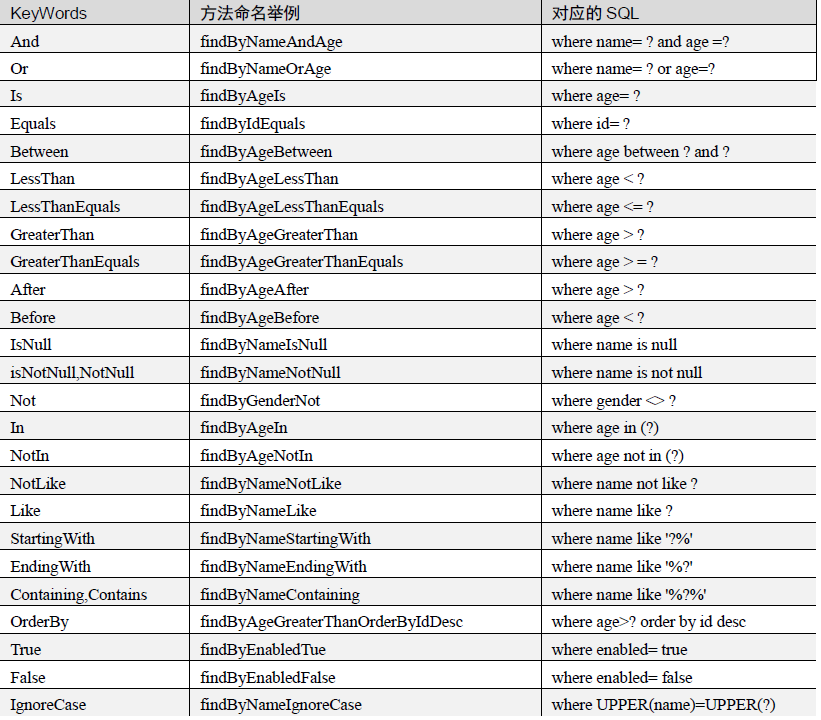
为什么写上方法名,JPA就知道你想干嘛了呢?假如创建如下的查询:findByUserDepUuid(),框架在解析该方法时,首先剔除 findBy,然后对剩下的属性进行解析,假设查询实体为Doc:
- 先判断 userDepUuid (根据 POJO 规范,首字母变为小写)是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续第二步;
- 从右往左截取第一个大写字母开头的字符串(此处为Uuid),然后检查剩下的字符串是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复第二步,继续从右往左截取;最后假设 user 为查询实体的一个属性;
- 接着处理剩下部分(DepUuid),先判断 user 所对应的类型是否有depUuid属性,如果有,则表示该方法最终是根据 “ Doc.user.depUuid” 的取值进行查询;否则继续按照步骤 2 的规则从右往左截取,最终表示根据 “Doc.user.dep.uuid” 的值进行查询。
- 可能会存在一种特殊情况,比如 Doc包含一个 user 的属性,也有一个 userDep 属性,此时会存在混淆。可以明确在属性之间加上 “_” 以显式表达意图,比如 “findByUser_DepUuid()” 或者 “findByUserDep_uuid()”
- 还有一些特殊的参数:例如分页或排序的参数:
有的时候,这里提供的查询关键字并不能满足我们的查询需求,这个时候就可以使用 @Query 关键字,来自定义查询 SQL
@Query("select u from t_user u where id=(select max(id) from t_user)")
User getMaxIdUser();
如果查询有参数的话,参数有两种不同的传递方式:
1.利用下标索引传参,索引参数如下所示,索引值从1开始,查询中 ”?X” 个数需要与方法定义的参数个数相一致,并且顺序也要一致:
@Query("select u from t_user u where id>?1 and username like ?2")
List<User> selectUserByParam(Long id, String name);
2.命名参数(推荐):这种方式可以定义好参数名,赋值时采用@Param(“参数名”),而不用管顺序:
@Query("select u from t_user u where id>:id and username like :name")
List<User> selectUserByParam2(@Param("name") String name, @Param("id") Long id);
查询时候,也可以是使用原生的SQL查询,如下:
@Query(value = "select * from t_user",nativeQuery = true)
List<User> selectAll();
@Modifying注解
涉及到数据修改操作,可以使用 @Modifying 注解,@Query 与 @Modifying 这两个 annotation一起声明,可定义个性化更新操作,例如涉及某些字段更新时最为常用,示例如下:
@Modifying
@Query("update t_user set age=:age where id>:id")
int updateUserById(@Param("age") Long age, @Param("id") Long id);
注意:
- 可以通过自定义的 JPQL 完成 UPDATE 和 DELETE 操作. 注意: JPQL 不支持使用 INSERT
- 方法的返回值应该是 int,表示更新语句所影响的行数
- 在调用的地方必须加事务,没有事务不能正常执行
- 默认情况下, Spring Data 的每个方法上有事务, 但都是一个只读事务. 他们不能完成修改操作
说到这里,再来顺便说说Spring Data 中的事务问题:
- Spring Data 提供了默认的事务处理方式,即所有的查询均声明为只读事务。
- 对于自定义的方法,如需改变 Spring Data 提供的事务默认方式,可以在方法上添加 @Transactional 注解。
- 进行多个 Repository 操作时,也应该使它们在同一个事务中处理,按照分层架构的思想,这部分属于业务逻辑层,因此,需要在Service 层实现对多个 Repository 的调用,并在相应的方法上声明事务。
3、整合 jdbcTemplate
以多数据源来举例。
第一步先加入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
第二步则在配置文件中进行配置数据库信息
spring.datasource.one.jdbcUrl=jdbc:mysql:///mybatis?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false
spring.datasource.one.username=root
spring.datasource.one.password=123456
spring.datasource.two.jdbcUrl=jdbc:mysql:///waterdb?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false
spring.datasource.two.username=root
spring.datasource.two.password=123456
第三步创建数据源配置类,进行根据不同的数据库配置信息,来创建数据源
@Configuration
public class DataSourceConfigur {
@Bean
@ConfigurationProperties("spring.datasource.one")
DataSource dsOne(){
return new HikariDataSource();
}
@Bean
@ConfigurationProperties("spring.datasource.two")
DataSource dsTwo(){
return new HikariDataSource();
}
}
在类中,通过 @ConfigurationProperties来指定数据库的信息为配置文件中的哪一个\
因为 springboot 中如果没有配置指定数据源的话,他默认为你指定为HikariCP 为数据源。所以这里以 HikariDataSource 来创建数据源
第四步也是通过配置类来配置 jdbcTemplate 的 bean
@Configuration
public class JdbcTemplateConfigur {
@Bean
@Primary
JdbcTemplate jdbcTemplateOne(@Qualifier("dsOne") DataSource ds){
return new JdbcTemplate(ds);
}
@Bean
JdbcTemplate jdbcTemplateTwo(@Qualifier("dsTwo") DataSource ds){
return new JdbcTemplate(ds);
}
}
在类中使用了 @Primary 注解,这是因为 spring 容器中要求注入的 bean 为单例,而当没有 @Primary 注解时,会报错
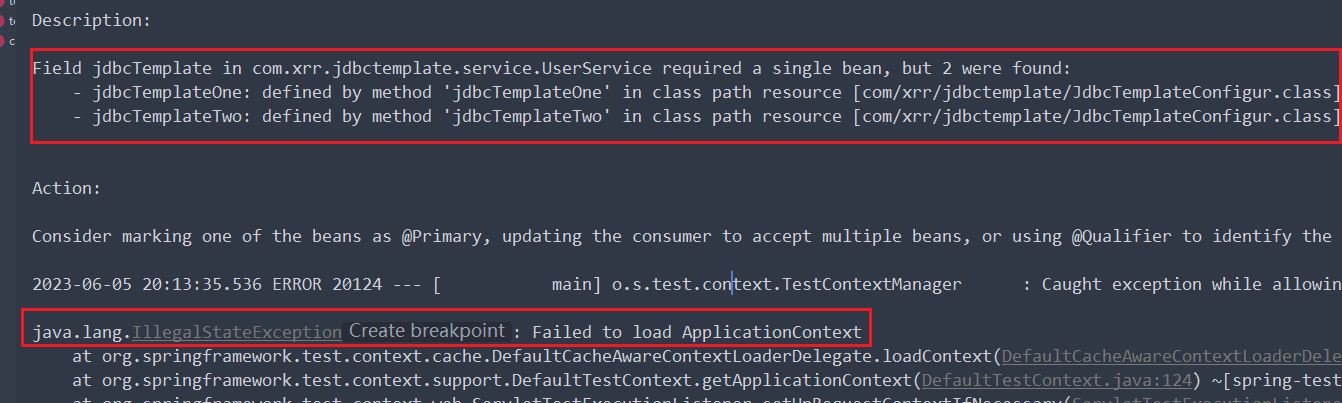
这时,报错中会建议我们使用其注解 @Primary 注解。当然使用其注解能解决问题。那为什么需要呢?
当我们进入到该注解中,会发现其中注释为我们介绍了该注解的使用。即 spring 容器中只能由一种类型的 bean,如果需要注入同种类型的多个bean时,需要在其中的一个 bean 加上该注解,让其成为最优的,优先级高,优先匹配。
第五步则通过自动装配来获取 jdbcTemplate 的 bean
@Autowired
@Qualifier("jdbcTemplateOne")
JdbcTemplate jdbcTemplateOne;
@Resource(name = "jdbcTemplateTwo")
JdbcTemplate jdbcTemplateTwo;
接下来就是正常的使用 jdbcTemplate 即可。
这里就记录使用 jdbcTemplate 使用的两点:
获取自增id
1、首先创建 GeneratedKeyHolder 对象
2、在 PreparedStatement 加入 Statement.RETURN_GENERATED_KEYS 参数
3、将 GeneratedKeyHolder 对象作为参数传入 jdbcTemplate 中 update 方法
public void addUser(User user){
GeneratedKeyHolder keyHolder = new GeneratedKeyHolder();
jdbcTemplate.update(new PreparedStatementCreator(){
@Override
public PreparedStatement createPreparedStatement(Connection con) throws SQLException {
PreparedStatement statement = con.prepareStatement("insert into user(name,age) values(?,?)", Statement.RETURN_GENERATED_KEYS);
//设置参数
statement.setString(1, user.getName());
statement.setInt(2, user.getAge());
return statement;
}
}, keyHolder);
//设置增加的用户的id
user.setUid(keyHolder.getKey().longValue());
}
查询为集合
方式一:通过 new RowMapper
public List<User> getUser(){
List<User> query = jdbcTemplate.query("select * from user", new RowMapper<User>() {
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
long uid = rs.getLong("uid");
String name = rs.getString("name");
int age = rs.getInt("age");
User user = new User();
user.setAge(age);
user.setUid(uid);
user.setName(name);
return user;
}
});
return query;
}
方式二;通过new BeanPropertyRowMapper<>(T.class)
public List<User> getUser2(){
List<User> query = jdbcTemplate.query("select * from user", new BeanPropertyRowMapper<>(User.class));
return query;
}
本文参考江南一点雨博主的文档。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)