
异步:asyncio和aiohttp的一些应用(1)
1. asyncio
1.1asyncio/await 用法
async/await 是 python3.5中新加入的特性, 将异步从原来的yield 写法中解放出来,变得更加直观。
在3.5之前,如果想要使用异步,主要使用yield语法。举例如下:
import asyncio @asyncio.coroutine # 修饰符,等同于 asyncio.coroutine(hello()) def hello(): print('Hello world! (%s)' % threading.currentThread()) yield from asyncio.sleep(1) # 执行到这一步以后,直接切换到下一个任务,等到一秒后再切回来 print('Hello again! (%s)' % threading.currentThread()) loop = asyncio.get_event_loop() tasks = [hello(), hello()] loop.run_until_complete(asyncio.wait(tasks)) loop.close()
引入了async/await以后,hello()可以写成这样:
async def hello(): print("Hello world!") r = await asyncio.sleep(1) print("Hello again!")
注意此时已经不需要使用@asyncio.coroutin进行修饰,而是在def之前加async表示这是个异步函数,其内有异步操作。此外,使用await 替换了yield from, 表示这一步为异步操作。
加一项,关于时间获取:
import time now = lambda: time.time() # 获取当前时间 # 待执行程序执行 start = now() # 在获取一下时间 print('TIME: ', now() - start) # 动态获取行进时间 不同于: start = time.time() # 待执行程序执行 end = time.time() print('TIME: ', end - start) # 获取时间是固定的
1.2关于run_until_complete和run_server的区别
一般先要设置一个loop循环 loop = asyncio.get_event_loop()
我们一直通过 run_until_complete 来运行 loop ,等到 future 完成,run_until_complete 也就返回了。

输出:

现在改用 run_forever:

输出:

三秒钟过后,future 结束,但是程序并不会退出。run_forever 会一直运行,直到 stop 被调用,但是你不能像下面这样调 stop:
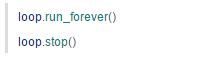
run_forever 不返回,stop 永远也不会被调用。所以,只能在协程中调 stop:
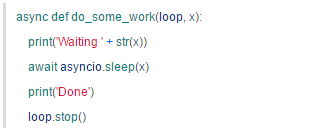
这样并非没有问题,假如有多个协程在 loop 里运行:
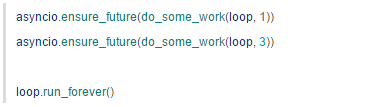
第二个协程没结束,loop 就停止了——被先结束的那个协程给停掉的。
要解决这个问题,可以用 gather 把多个协程合并成一个 future,并添加回调,然后在回调里再去停止 loop。
看一个小测试:
# 一个关于协程的小测试:run_forever的回调关闭循环 import asyncio import functools async def compute(x, y): print("Compute %s + %s ..." % (x, y)) await asyncio.sleep(2.0) return x + y async def print_sum(x, y): result = await compute(x, y) print("%s + %s = %s" % (x, y, result)) def done_callback(loop,futu): # 这里还可以执行futu的相关操作 print('关闭loop循环') loop.stop() loop = asyncio.get_event_loop() # tasks = [print_sum(1, 2), print_sum(3, 4), print_sum(5, 6)] # loop.run_until_complete(asyncio.wait(tasks)) # run_until_complete 完成后释放,结束loop,相当于loop.close() futus = asyncio.gather(print_sum(1, 2), print_sum(3, 4), print_sum(5, 6)) futus.add_done_callback(functools.partial(done_callback, loop)) loop.run_forever() # 执行多个协程之后再回调一个done_callback来停止循环,其实run_until_complete就是基于run_forever()
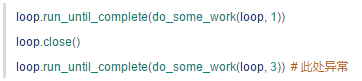
1.1.2 loop.close()?
简单来说,loop 只要不关闭,就还可以再运行。:
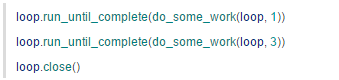
但是如果关闭了,就不能再运行了:
1.1.3 回调函数:add_done_callback
回调函数, 执行且按照顺序, 假如协程是一个 IO 的读操作,等读完数据后,我们希望得到通知,以便下一步数据的处理。这一需求可以通过往 future 添加回调来实现。
import asyncio async def hello1(): print("1, Hello world!") #r = await asyncio.sleep(1) print("1, Hello again!") for i in range(5): print(i) async def hello2(): print("2, Hello world!") #r = await asyncio.sleep(1) print("2, Hello again!") for i in range(5,10): print(i) def done_callback1(futu): # futu是异步的函数名称 print('Done1') def done_callback2(futu): print('Done2') futu = asyncio.ensure_future(hello1()) futu.add_done_callback(done_callback1) futu = asyncio.ensure_future(hello2()) futu.add_done_callback(done_callback2) loop.run_until_complete(futu) >>> 1, Hello world! >>> 1, Hello again! >>> 0 >>> 1 >>> 2 >>> 3 >>> 4 >>> 2, Hello world! >>> 2, Hello again! >>> 5 >>> 6 >>> 7 >>> 8 >>> 9 >>> Done1 >>> Done2
1.1.4 多个协程运行的三种写法
# 多个协程同步执行 # 第一种写法 loop.run_until_complete(asyncio.gather(hello1(), hello2())) # 第二种写法 coros = [hello1(), hello2()] loop.run_until_complete(asyncio.gather(*coros)) # 第三种写法 futus = [asyncio.ensure_future(hello1()), asyncio.ensure_future(hello2())] loop.run_until_complete(asyncio.gather(*futus))
当然也可以这么写:
tasks = [ asyncio.ensure_future(hello1()), asyncio.ensure_future(hello2())]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
2. aiohttp
aiohttp是一个用于web服务的库,网上的资料,包括廖雪峰的网站中的资料大部分是关于服务器端(server)的,关于客户端(client)的资料不多。2.1 基本用法
async with aiohttp.get('https://github.com') as r: await r.text()
其中r.text(), 可以在括号中指定解码方式,编码方式,例如
await resp.text(encoding='windows-1251')
或者也可以选择不编码,适合读取图像等,是无法编码的
await resp.read()
例子:一个简单的小例子:
import asyncio,aiohttp async def fetch_async(url): print(url) async with aiohttp.request("GET",url) as r: reponse = await r.text(encoding="utf-8") #或者直接await r.read()不编码,直接读取,适合于图像等无法编码文件 print(reponse) tasks = [fetch_async('http://www.baidu.com/'), fetch_async('http://www.chouti.com/')] event_loop = asyncio.get_event_loop() results = event_loop.run_until_complete(asyncio.gather(*tasks)) # 这里使用asyncio.gather()和asyncio.wait()不一样。gather把多个函数包装成单个tasks,因为loop.run_until_complete只接受
单个tasks,而wait()用于调用单一函数 event_loop.close()
2.2 设置timeout
需要加一个with aiohttp.Timeout(x)with aiohttp.Timeout(0.001): async with aiohttp.get('https://github.com') as r: await r.text()
2.3 使用session获取数据
这里要引入一个类,aiohttp.ClientSession. 首先要建立一个session对象,然后用该session对象去打开网页。session可以进行多项操作,比如post, get, put, head等等,如下面所示
import asyncio,aiohttp async def fetch_async(url): print(url) async with aiohttp.ClientSession() as session: #协程嵌套,只需要处理最外层协程即可fetch_async async with session.get(url, timeout=60) as resp: #设置超时处理60s print(resp.status) print(resp.charset) #查看默认编码,默认使用utf-8 print(await resp.read()) #使用read()方法时,不会进行编码,是以字节的形式读取 print(await resp.text()) #因为这里使用到了await关键字,实现异步,所有他上面的函数体需要声明为异步async #resp.text()会自动将服务器端返回的内容进行解码decode,我们也可以自定义 resp.text(encoding='gb2312') print(await resp.content.read()) #使用字节流形式获取数据,而不像text(),read()方法那样一次性获取数据,注意:session.get()是Response对象,他继承于StreamResponse print(resp.cookies) #获取当前cookies
print(resp.headers) #查看响应头dict形式
print(resp.raw_headers) #查看原生headers,字节型
print(resp.history)
tasks = [fetch_async('http://www.baidu.com/'), fetch_async('http://www.cnblogs.com/ssyfj/')] event_loop = asyncio.get_event_loop() results = event_loop.run_until_complete(asyncio.gather(*tasks)) event_loop.close()
如果要使用其他方法,则相应的语句要改成
session.put('http://httpbin.org/put', data=b'data') session.delete('http://httpbin.org/delete') session.head('http://httpbin.org/get') session.options('http://httpbin.org/get') session.patch('http://httpbin.org/patch', data=b'data')
2.4 自定义headers
这个比较简单,将headers放于session.get/post的选项中即可。注意headers数据要是dict格式
url = 'https://api.github.com/some/endpoint' headers = {'content-type': 'application/json'} await session.get(url, headers=headers)
async def func1(url,params,filename): #用自定义headers异步读写文件 async with aiohttp.ClientSession() as session: headers = {'Content-Type':'text/html; charset=utf-8'} async with session.get(url,params=params,headers=headers) as r: with open(filename,"wb") as fp: while True: chunk = await r.content.read(10) if not chunk: break fp.write(chunk)
2.5 使用代理
conn = aiohttp.ProxyConnector(proxy="http://some.proxy.com", proxy_auth=aiohttp.BasicAuth('user', 'pass')) # 如果需要代理认证的话,就需要加这个proxy_auth选项
async with aiohttp.ClientSession(connector=conn) as session: async with session.get('http://python.org') as resp: print(resp.status)
2.6 自定义cookie
url = 'http://httpbin.org/cookies' async with ClientSession({'cookies_test': 'Monday'}) as session: async with session.get(url) as resp: assert await resp.json() == {"cookies": {"cookies_test": "Monday"}}
2.7 在URL中传递参数
我们经常需要通过 get 在url中传递一些参数,参数将会作为url问号后面的一部分发给服务器。在aiohttp的请求中,允许以dict的形式来表示问号后的参数。举个例子,如果你想传递 key1=value1 key2=value2 到 httpbin.org/get 你可以使用下面的代码:
params = {'key1': 'value1', 'key2': 'value2'}
async with session.get('http://httpbin.org/get',
params=params) as resp:
assert resp.url == 'http://httpbin.org/get?key2=value2&key1=value1'
可以看到,代码正确的执行了,说明参数被正确的传递了进去。不管是一个参数两个参数,还是更多的参数,都可以通过这种方式来传递。除了这种方式之外,还有另外一个,使用一个 list 来传递(这种方式可以传递一些特殊的参数,例如下面两个key是相等的也可以正确传递):
params = [('key', 'value1'), ('key', 'value2')] async with session.get('http://httpbin.org/get', params=params) as r: assert r.url == 'http://httpbin.org/get?key=value2&key=value1'
除了上面两种,我们也可以直接通过传递字符串作为参数来传递,但是需要注意,通过字符串传递的特殊字符不会被编码:
async with session.get('http://httpbin.org/get', params='key=value+1') as r: assert r.url == 'http://httpbin.org/get?key=value+1'
3. 样例
3.1下面这个简单的爬虫,是用来爬取我博客下所有的文章的
import urllib.request as request from bs4 import BeautifulSoup as bs import asyncio import aiohttp @asyncio.coroutine async def getPage(url,res_list): print(url) headers = {'User-Agent':'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'} # conn = aiohttp.ProxyConnector(proxy="http://127.0.0.1:8087") async with aiohttp.ClientSession() as session: async with session.get(url,headers=headers) as resp: assert resp.status==200 res_list.append(await resp.text()) class parseListPage(): def __init__(self,page_str): self.page_str = page_str def __enter__(self): page_str = self.page_str page = bs(page_str,'lxml') # 获取文章链接 articles = page.find_all('div',attrs={'class':'article_title'}) art_urls = [] for a in articles: x = a.find('a')['href'] art_urls.append('http://blog.csdn.net'+x) return art_urls def __exit__(self, exc_type, exc_val, exc_tb): pass page_num = 5 page_url_base = 'http://blog.csdn.net/u014595019/article/list/' page_urls = [page_url_base + str(i+1) for i in range(page_num)] loop = asyncio.get_event_loop() ret_list = [] tasks = [getPage(host,ret_list) for host in page_urls] loop.run_until_complete(asyncio.wait(tasks)) articles_url = [] for ret in ret_list: with parseListPage(ret) as tmp: articles_url += tmp ret_list = [] tasks = [getPage(url, ret_list) for url in articles_url] loop.run_until_complete(asyncio.wait(tasks)) loop.close()

