记录python题
def mone_sorted(itera): new_itera = [] while itera: min_value = min(itera) new_itera.append(min_value) itera.remove(min_value)
return new_itera if __name__ == "__main__": lst = [2, 3, 1, 5, 4] print(mone_sorted(lst))
函数内部使用了选择排序的思想

1 编写函数,模拟内置函数sorted()
2 若有一个jsonline格式的文件file.txt,大小约为10K,我们的处理方式为:
def get_lines(): l = [] with open('file.txt', 'rb') as f: for eachline in f: l.append(eachline) return l if __name__ == '__main__': for e in get_lines(): process(e) #处理每一行数据
现在要处理一个大小为10G的file.txt文件,但是内存只有4G。如果在只修改get_lines 函数而其他代码保持不变的情况下,应该如何实现?需要考虑的问题都有那些?
def get_lines(): l = [] with open('file.txt','rb') as f: data = f.readlines(60000) l.append(data) yield l
3 输入日期。判断这一天是今年的第几天。
import datetime year = int(input('请输入年:')) month= int(input('请输入月:')) day = int(input('请输入日:')) date1 = datetime.date(year=year, month=month, day=day) date2 = datetime.date(year=year, month=1, day=1) date3 = date1-date2 print(date3)
4 打乱一个排好序的list
import random def daluan(lst): random.shuffle(lst) return lst lst = [1, 2, 3, 4, 5] print(daluan(lst))
5 按照一个字典的值来对这个字典进行排序
old_dic = {'a':6, 'b':3, 'c':2, 'd':4, 'e':5, 'f':1}
new_dic = sorted(old_dic.items(), key=lambda d:d[1])
print(new_dic)
6 字典推导式
{key,value for key,value in iterable}
7 反转字符串
s[::-1]
8 将字符串 "k:1 |k1:2|k2:3|k3:4",处理成字典 {k:1,k1:2,...}
def qie(str): new_dict = {} for i in str.split('|'): key, value = i.split(':') new_dict[key] = value return new_dict str = "k:1|k1:2|k2:3|k3:4" print(qie(str))
9 请按alist中元素的age由大到小排序
def sort_by_age(lst): return sorted(lst, key=lambda x:x['age']) alist = [{'name':'a','age':20},{'name':'b','age':30},{'name':'c','age':25}] print(sort_by_age(alist))
10 下面代码的输出结果将是什么?
list = ['a','b','c','d','e'] print(list[10:])
答案 []
11 写一个列表生成式,产生一个公差为11的等差数列
lst = [x*11 for x in range(0,11)] print(lst)
12 给定两个列表,怎么找出他们相同的元素和不同的元素?
list1 = [1, 2, 3, 4] list2 = [2, 3, 4, 5] print(set(list1) & set(list2)) print(set(list1) ^ set(list2))
13 序列去重
old_lst = [2, 2, 1, 1, 3, 4] new_lst = list(set(old_lst)) new_lst.sort(key=old_lst.index) print(new_lst) new_lst1 = [] for i in old_lst: if i not in new_lst1: new_lst1.append(i) print(new_lst1)
14 python中新式类和经典类的区别
a. 在python里凡是继承了object的类,都是新式类
b. Python3里只有新式类
c. Python2里面继承object的是新式类,没有写父类的是经典类
d. 经典类目前在Python里基本没有应用
15 如何用python实现单例模式
第一种:__new__
class Singalton: def __new__(cls, *args, **kwargs): if not hasattr(cls, 'instance'): cls.instance = super(Singalton, cls).__new__(cls, *args, **kwargs) return cls.instance obj1 = Singalton() obj2 = Singalton() obj1.attr1 = 'value1' print(obj1.attr1, obj2.attr1) print(obj1 is obj2)
第二种:装饰器
class Singalton: def __new__(cls, *args, **kwargs): if not hasattr(cls, 'instance'): cls.instance = super(Singalton, cls).__new__(cls, *args, **kwargs) return cls.instance obj1 = Singalton() obj2 = Singalton() obj1.attr1 = 'value1' print(obj1.attr1, obj2.attr1) print(obj1 is obj2)
16 反转一个整数
def fan(n): if n >= 0: n_str = str(n) new_n = int(n_str[::-1]) else: n_str = str(n) new_n = -int(n_str[:0:-1]) return new_n if __name__ == '__main__': n1 = 123 n2 = -123 print(type(fan(n1)),fan(n1)) print(type(fan(n2)),fan(n2))
17 实现遍历目录和子目录
import os def scanf(path): file_lst = os.listdir(path) for obj in file_lst: print(obj) if os.path.isfile(obj): print(obj) elif os.path.isdir(obj): scanf(obj) else: print('over') if __name__ == '__main__': scanf('G:\学习与资料')
18 一行代码实现1-100之和
print(sum(range(0, 101)))
19 遍历列表时删除元素
我们规定删除大于10的数字
第一种:列表推导式
lst = [1, 5, 12, 5, 13, 6, 9, 10] new_lst = [i for i in lst if i < 10] print(new_lst)
第二种:遍历删除
lst = [1, 5, 12, 5, 13, 6, 9, 10] for i in lst: if i >= 10: lst.remove(i) print(lst)
第三种:filter()
lst = [1, 5, 12, 5, 13, 6, 9, 10] new_lst = filter(lambda x : x < 10, lst) print(list(new_lst))
20 全字母短句 PANGRAM 是包含所有英文字母的句子,比如:A QUICK BROWN FOX JUMPS OVER THE LAZY DOG. 定义并实现一个方法 get_missing_letter, 传入一个字符串采纳数,返回参数字符串变成一个 PANGRAM 中所缺失的字符。应该忽略传入字符串参数中的大小写,返回应该都是小写字符并按字母顺序排序(请忽略所有非 ACSII 字符)
下面示例是用来解释,双引号不需要考虑:
(0)输入: "A quick brown for jumps over the lazy dog"
返回: ""
(1)输入: "A slow yellow fox crawls under the proactive dog"
返回: "bjkmqz"
(2)输入: "Lions, and tigers, and bears, oh my!"
返回: "cfjkpquvwxz"
(3)输入: ""
返回:"abcdefghijklmnopqrstuvwxyz"
def get_missing_letter(a): a1 = set('abcdefghijklmnopqrstuvwxyz') a2 = set(a) new_a = ''.join(sorted(a1-a2)) return new_a print(get_missing_letter('python'))
21 求出列表的所有奇数
lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] new_lst = [i for i in lst if i % 2 != 0] print(new_lst)
22 python中变量的作用域
函数作用域的LEGB
L: local 函数内部作用域
E: enclosing 函数内部与内嵌函数之间
G: global 全局作用域
B: build-in 内置作用
python在函数里面的查找分为4种,称之为LEGB,也正是按照这是顺序来查找的
23 字符串123装换为'123',不适用内置函数,如int()
def zhuan_huan(a): num = 0 for i in a: for j in range(10): if i == str(j): num = num*10 + j return num print(zhuan_huan('120'))
24 统计一个文本中单词频数最高的四个单词
import re def search(path): dictone = {} with open(path) as f: for line in f: line = re.sub('\W+', ' ', line)#把一些特殊的字符换为空格 lineone = line.split() for oneline in lineone: if not dictone[oneline]: dictone[oneline] = 1 else: dictone += 1 num_ten = sorted(dictone.items(), key=lambda x: x[1], reverse=True)[:10] num_ten = [x[0] for x in num_ten] return num_ten
25 请写出一个函数满足以下条件
该函数的输入是一个仅包含数字的list,输出一个新的list,其中每一个元素要满足以下条件:
1、该元素是偶数
2、该元素在原list中是在偶数的位置(index是偶数)
def num_list(lst): return [i for i in lst if i%2==0 and lst.index(i)%2 == 0] num = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] print(num_list(num))
26 用一行代码生成[1,4,9,16,25,36,49,64,81,100]
lst = [i**2 for i in range(1, 11)] print(lst)
27 两个有序列表,l1,l2,对这两个列表进行合并不可使用extend
def sort_by(lst1, lst2): new_lst = [] while len(lst1)> 0 and len(lst2) > 0: if lst1[0] < lst2[0]: new_lst.append(lst1[0]) del lst1[0] elif lst1[0] > lst2[0]: new_lst.append(lst2[0]) del lst2[0] elif lst1[0] == lst2[0]: new_lst.append(lst2[0]) del lst1[0], lst2[0] if lst1 == []: new_lst += lst2 if lst2 == []: new_lst += lst1 return new_lst lst1 = [1, 2, 3, 4, 5, 9, 11, 15] lst2 = [3, 4, 6, 8, 9 , 11, 12, 19] print(sort_by(lst1, lst2))
28 给定一个任意长度数组,实现一个函数
让所有奇数都在偶数前面,而且奇数升序排列,偶数降序排序,如字符串'1982376455',变成'1355798642'
def ji_ou(s): s1, s2 = [], [] for i in s: if int(i) % 2 == 0: s2.append(i) else: s1.append(i) new_s = sorted(s1) + sorted(s2) new_s = ''.join(new_s) return new_s s = '1982376455' print(ji_ou(s))
29 写出一个函数找出整数组中第二大的数
def search(lst): num = sorted(lst, reverse=True)[1] return num lst = [1, 3, 5, 2, 4, 0] print(search(lst))
30 阅读如下代码,它会输出什么结果
def multi(): return [lambda x : i*x for i in range(4)] print([m(3) for m in multi()])
[9, 9, 9, 9]
31 统计一段字符串中字符出现的次数
def count_word(s): out_dict = {} for i in set(s): out_dict[i] = list(s).count(i) return out_dict print(count_word('dwadwakigjihefha'))
32 遍历一个类的所有属性,并打印每一个属性名
class Car: def __init__(self, name, loss): self.name = name self.loss = loss def getName(self): return self.name def getPrice(self): return self.loss[0] def getLoss(self): return self.loss[1] * self.loss[2] bmw = Car('奔驰', [100, 1, 50]) # 实例化 print(getattr(bmw, 'name')) # 使用getattr传入name属性 print(dir(bmw)) # 答应实例的属性
33 写一个类,并让他尽可能多的支持字符操作
class Array: __list = [] def __init__(self): print "constructor" def __del__(self): print "destruct" def __str__(self): return "this self-defined array class" def __getitem__(self,key): return self.__list[key] def __len__(self): return len(self.__list) def Add(self,value): self.__list.append(value) def Remove(self,index): del self.__list[index] def DisplayItems(self): print "show all items---" for item in self.__list: print item
34 动态的获取和设置对象的属性
dir([obj]):
调用这个方法将返回包含obj大多数属性名的列表(会有一些特殊的属性不包含在内)。obj的默认值是当前的模块对象。
hasattr(obj, attr):
这个方法用于检查obj是否有一个名为attr的值的属性,返回一个布尔值。
getattr(obj, attr):
调用这个方法将返回obj中名为attr值的属性的值,例如如果attr为'bar',则返回obj.bar。
setattr(obj, attr, val):
调用这个方法将给obj的名为attr的值的属性赋值为val。例如如果attr为'bar',则相当于obj.bar = val。
35 写一个函数找出一个整数数组中,第二大的数
def find_sec(lst): new_lst = list(set(lst)) sec_num = sorted(new_lst, reverse=True)[1] return sec_num lst = [4, 6, 3, 1, 5, 5] print(find_sec(lst))
36 python交换2个变量的值
a, b = 1, 2 a, b = b, a print(a, b)
37 map函数和reduce函数
map函数:根据指定的函数对指定的序列做映射
reduce函数:会对参数序列中元素进行累积
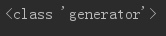
38 x是什么类型?
x = (i for i in range(10)) print(type(x))
39 请用一行代码 实现将1-N 的整数列表以3为单位分组
lst = [[x for x in range(1, 101)][i:i+3] for i in range(0, 100, 3)] print(lst)
40 请鞋一段正则表达式 匹配出ip地址
import re pattern = re.compile('^(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)\.(25[0-5]|2[0-4]\d|[0-1]\d{2}|[1-9]?\d)$') str1 = '192.168.225.255' x = pattern.findall(str1) print(x)
上述代码分析:
25[0-5]:匹配250-255
2[0-4]\d:匹配200-249
[0-1]\d{2}:匹配000-199
[1-9]?\d:匹配0-99
41 str1 = “abbbccc”,用正则匹配为abccc,不管有多少b,就出现一次
import re str1 = 'abbbbccc' pattern = re.sub('b+', 'b', str1) print(pattern)
42 写出开头匹配字母和下划线,末尾是数字的正则表达式
^\w.*\d$
43 怎么过滤评论中的表情
用正则匹配出评论中的表情,然后使用sub将表情替换为空
44 进程Process
import os from multiprocessing import Process import time def pro_func(name, age, **kwargs): for i in range(5): print("子进程进行中 name=%s,age=%d,pid=%d"%(name, age, os.getpid())) print(kwargs) time.sleep(0.2) if __name__ == '__main__': p = Process(target=pro_func, args=('李强', 30), kwargs={'m':20}) p.start() time.sleep(0.5) p.terminate() #一种强行关闭子进程的方法 p.join()
45 进程间的消息队列
from multiprocessing import Process, Queue import os, time, random def write(q): for value in ['A', 'B', 'C']: print('put %s to queue...'%value) q.put(value) time.sleep(random.random()) def read(q): while True: if not q.empty(): value = q.get(True) print('get %s from the queue'%value) time.sleep(random.random()) else: break if __name__ == '__main__': q = Queue() pw = Process(target=write, args=(q,)) pr = Process(target=read, args=(q,)) pw.start() pw.join() pr.start() pr.join() print('所有数据写完,并且读完')
46 进程池
from multiprocessing import Pool import os,time,random def worker(msg): start = time.time() print("%s 开始执行,进程号为%d"%(msg,os.getpid())) # random.random()随机生成0-1之间的浮点数 time.sleep(random.random()*2) stop = time.time() print(msg,'执行完毕,耗时%0.2f'%(stop - start)) if __name__ == '__main__': po = Pool(3) #定义一个进程池,最大进程数3 for i in range(0,10): po.apply_async(worker,(i,)) print("---start----") po.close() po.join() print("----end----")
47 进程池中使用queue
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到如下的错误信息:
RuntimeError: Queue objects should only be shared between processs through inheritance
from multiprocessing import Manager,Pool import os,time,random def reader(q): print("reader 启动(%s),父进程为(%s)"%(os.getpid(),os.getpid())) for i in range(q.qsize()): print("reader 从Queue获取到消息:%s"%q.get(True)) def writer(q): print("writer 启动(%s),父进程为(%s)"%(os.getpid(),os.getpid())) for i in 'itcast': q.put(i) if __name__ == "__main__": print("(%s)start"%os.getpid()) q = Manager().Queue()#使用Manager中的Queue po = Pool() po.apply_async(writer,(q,)) time.sleep(1) po.apply_async(reader,(q,)) po.close() po.join() print("(%s)End"%os.getpid())
48 多线程共同操作同一个数据互斥锁同步
import threading import time class MyThread(threading.Thread): def run(self): global num time.sleep(1) if mutex.acquire(1): num += 1 msg = self.name + 'set num to ' + str(num) print(msg) mutex.release() num = 0 mutex = threading.Lock() def test(): for i in range(5): t = MyThread() t.start() if __name__ == "__main__": test()
49 请介绍下python的线程同步
一 setDaemon(False) 默认情况下就是setDaemon(False),主线程执行完自己的任务以后,就退出了,此时子线程会继续执行自己的任务,直到自己的任务结束
import threading, time def thread(): time.sleep(2) print('子线程结束') def main(): t1 = threading.Thread(target=thread) t1.start() print('主线程结束') if __name__ == '__main__': main()
二 setDaemon(True) ) 当我们使用setDaemon(True)时,这是子线程为守护线程,主线程一旦执行结束,则全部子线程被强制终止
import threading, time def thread(): time.sleep(2) print('子线程结束') def main(): t1 = threading.Thread(target=thread) t1.setDaemon(True) t1.start() print('主线程结束') if __name__ == '__main__': main()
三 join(线程同步) join 所完成的工作就是线程同步,即主线程任务结束以后,进入堵塞状态,一直等待所有的子线程结束以后,主线程再终止。
当设置守护线程时,含义是主线程对于子线程等待timeout的时间将会杀死该子线程,最后退出程序,所以说,如果有10个子线程,全部的等待时间就是每个timeout的累加和,简单的来说,就是给每个子线程一个timeou的时间,让他去执行,时间一到,不管任务有没有完成,直接杀死。
没有设置守护线程时,主线程将会等待timeout的累加和这样的一段时间,时间一到,主线程结束,但是并没有杀死子线程,子线程依然可以继续执行,直到子线程全部结束,程序退出。
import threading, time def thread(): time.sleep(2) print('子线程结束') def main(): t1 = threading.Thread(target=thread) t1.setDaemon(True) t1.start() # t1.join() # 不设置时堵塞主线程,等待子线程结束后主线程再结束 t1.join(timeout=1) # 设置timeout=1时,主线程堵塞1s,然后杀死所有子线程,然后主进程结束 print('主线程结束') if __name__ == '__main__': main()
50 多线程交互访问数据,访问到了就不访问了?如何做?
创建一个已访问数据列表,用于储存已访问的数据,并且加上互斥锁,在多线程访问数据的时候查看数据是否在已访问的数据中,若已存在就直接跳过。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号