利用Python半自动化生成Nessus报告
0x01 前言
Nessus是一个功能强大而又易于使用的远程安全扫描器,Nessus对个人用户是免费的,只需要在官方网站上填邮箱,立马就能收到注册号了,对应商业用户是收费的。当然,个人用户是有16个IP限制,通过企业邮箱可以体验免费7天的Nessus专业版,IP无限制。
Nessus激活码获取地址:https://www.tenable.com/products/nessus/activation-code
0x02 Nessus使用
登录后通过New Scan创建扫描任务,扫描完成后,我们即可导出扫描报告。Nessus提供4种报告类型导出:

我们选择HTML类型,Report选择Custom,Croup By 选择Host,导出HTML报告。
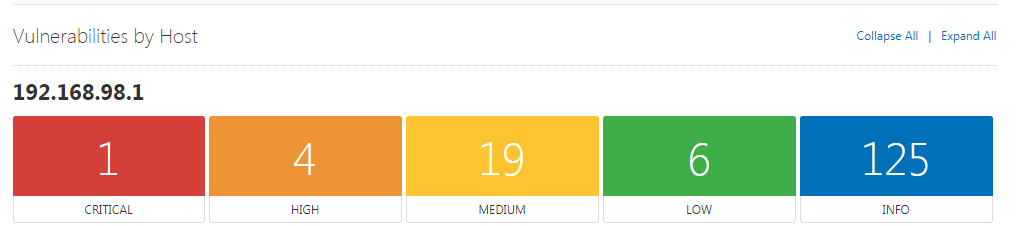
但这些报告还需要进一步整理成我们想要的格式,并且去掉不必要的消息,得到最终我们希望能够得到信息。
那首先我们确认一下,想要得到的信息是哪些呢?
1、服务器IP
2、漏洞危害级别
3、漏洞名称
这三个最基本的信息,对我来说就差不都足够了,我就知道哪些服务器存在高危漏洞,并提供解决漏洞修复建议。
0x03 Python脚本
通过解析html文件,获取相关漏洞信息,并输出到csv文件。
#! /usr/bin/env python
# _*_ coding:utf-8 _*_
#Author:Aaron
from lxml import etree
import csv
import sys
host=''
title=''
result_list=[]
def htm_parse(l):
if '#d43f3a' in etree.tostring(l):
info=u"严重 - "+l.text
elif '#ee9336' in etree.tostring(l):
info=u"高危 - "+l.text
elif '#fdc431' in etree.tostring(l):
info=u"中危 - "+l.text
elif '#3fae49' in etree.tostring(l):
info=u"低危 - "+l.text
elif '#0071b9' in etree.tostring(l):
info=u'信息泄露 - '+l.text
else:
info='Parsing error,Check that the versions are consistent.'
return info
def main(filename):
html = etree.parse(filename,etree.HTMLParser())
ls =html.xpath('/html/body/div[1]/div[3]/div')
for i in ls:
if "font-size: 22px; font-weight: bold; padding: 10px 0;" in etree.tostring(i):
host=i.text
elif "this.style.cursor" in etree.tostring(i):
result=host+" - "+htm_parse(i)
print result
result_list.append(result)
return result_list
if __name__ == '__main__':
filename=sys.argv[1]
list_host = main(filename)
with open('result.csv','wb') as f:
f.write(u'\ufeff'.encode('utf8'))
w = csv.writer(f)
w.writerow(['服务器IP','漏洞级别','漏洞编号','漏洞名称'])
for i in list_host:
data=i.split('-',3)
w.writerow([item.encode('utf8') for item in data])
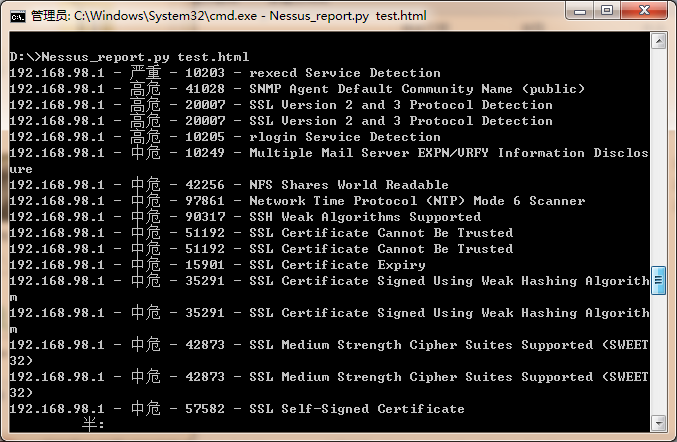
脚本运行效果如下:
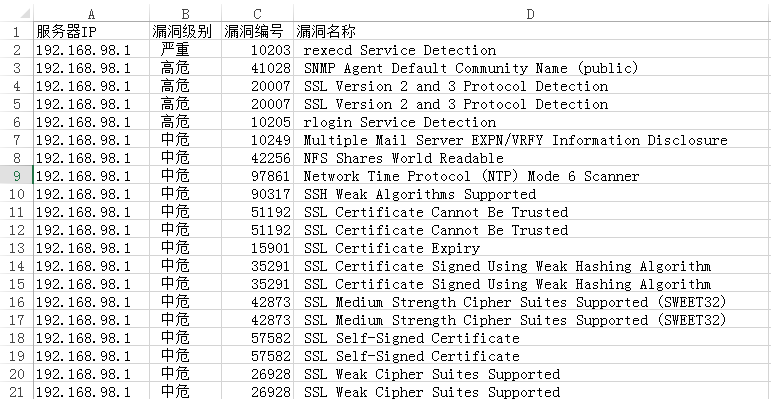
在同目录下生成result.csv,内容如下:
最后,通过excel进行相关信息的筛选、删除和整理,最后汇总成报告。
0x04 小结
本文提供了一个demo,用于半自动化生成Nessus报告,有需要的话,可入库扩展,增加自动翻译,提供修复建议等。Nessus中文漏洞库可参见这个项目,NessusReportInChinese:半自动化将 Nessus 英文报告(csv格式)生成中文 excel ,中文漏洞库已有700多条常见漏洞。
github地址:https://github.com/FunnyKun/NessusReportInChinese

 浙公网安备 33010602011771号
浙公网安备 33010602011771号