


2020JAVA面试题附答案(持续更新版)
前言:勤奋才是改变你命运的唯一捷径。
整理不易,各位看官点赞再看更舒适,养成好习惯(●´∀`●)
JAVA基础
1.JAVA中的几种基本类型,各占用多少字节?
下图单位是bit,非字节 1B=8bit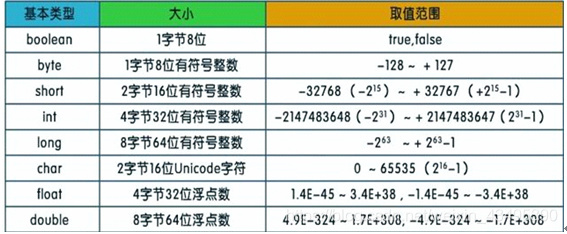
2.String能被继承吗?为什么?
不可以,因为String类有final修饰符,而final修饰的类是不能被继承的,实现细节不允许改变。平常我们定义的String str=”a”;其实和String str=new String(“a”)还是有差异的。
前者默认调用的是String.valueOf来返回String实例对象,至于调用哪个则取决于你的赋值,比如String num=1,调用的是
public static String valueOf(int i) {
return Integer.toString(i);
}
- 1
- 2
- 3
后者则是调用如下部分:
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
- 1
- 2
- 3
- 4
最后我们的变量都存储在一个char数组中
private final char value[];
- 1
3.String, Stringbuffer, StringBuilder 的区别。
String 字符串常量(final修饰,不可被继承),String是常量,当创建之后即不能更改。(可以通过StringBuffer和StringBuilder创建String对象(常用的两个字符串操作类)。)
==StringBuffer 字符串变量(线程安全),==其也是final类别的,不允许被继承,其中的绝大多数方法都进行了同步处理,包括常用的Append方法也做了同步处理(synchronized修饰)。其自jdk1.0起就已经出现。其toString方法会进行对象缓存,以减少元素复制开销。
public synchronized String toString() {
if (toStringCache == null) {
toStringCache = Arrays.copyOfRange(value, 0, count);
}
return new String(toStringCache, true);
}
- 1
- 2
- 3
- 4
- 5
- 6
==StringBuilder 字符串变量(非线程安全)==其自jdk1.5起开始出现。与StringBuffer一样都继承和实现了同样的接口和类,方法除了没使用synch修饰以外基本一致,不同之处在于最后toString的时候,会直接返回一个新对象。
public String toString() {
// Create a copy, don’t share the array
return new String(value, 0, count);
}
- 1
- 2
- 3
- 4
4.ArrayList 和 LinkedList 有什么区别。
ArrayList和LinkedList都实现了List接口,有以下的不同点:
1、ArrayList是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。
2、相对于ArrayList,LinkedList的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
3、LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
5.讲讲类的实例化顺序,比如父类静态数据,构造函数,字段,子类静态数据,构造函数,字段,当 new 的时候, 他们的执行顺序。
此题考察的是类加载器实例化时进行的操作步骤(加载–>连接->初始化)。
父类静态代变量、
父类静态代码块、
子类静态变量、
子类静态代码块、
父类非静态变量(父类实例成员变量)、
父类构造函数、
子类非静态变量(子类实例成员变量)、
子类构造函数。
测试demo
参阅博客《深入理解类加载》
6.用过哪些 Map 类,都有什么区别,HashMap 是线程安全的吗,并发下使用的 Map 是什么,他们内部原理分别是什么,比如存储方式, hashcode,扩容, 默认容量等。
hashMap是线程不安全的,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,采用哈希表来存储的,
参考链接
JAVA8 的 ConcurrentHashMap 为什么放弃了分段锁,有什么问题吗,如果你来设计,你如何设计。
参考链接
7.有没有有顺序的 Map 实现类, 如果有, 他们是怎么保证有序的。
TreeMap和LinkedHashMap是有序的(TreeMap默认升序,LinkedHashMap则记录了插入顺序)。
参考链接
8.抽象类和接口的区别,类可以继承多个类么,接口可以继承多个接口么,类可以实现多个接口么。
1、抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。
2、抽象类要被子类继承,接口要被类实现。
3、接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现
4、接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
5、抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
6、抽象方法只能申明,不能实现。abstract void abc();不能写成abstract void abc(){}。
7、抽象类里可以没有抽象方法
8、如果一个类里有抽象方法,那么这个类只能是抽象类
9、抽象方法要被实现,所以不能是静态的,也不能是私有的。
10、接口可继承接口,并可多继承接口,但类只能单根继承。
9.继承和聚合的区别在哪。
继承指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;在Java中此类关系通过关键字extends明确标识,在设计时一般没有争议性;
聚合是关联关系的一种特例,他体现的是整体与部分、拥有的关系,即has-a的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享;比如计算机与CPU、公司与员工的关系等;表现在代码层面,和关联关系是一致的,只能从语义级别来区分;
参考链接
10.讲讲你理解的 nio和 bio 的区别是啥,谈谈 reactor 模型。
IO(BIO)是面向流的,NIO是面向缓冲区的
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
参考链接1
参考链接2
11.反射的原理,反射创建类实例的三种方式是什么
参考链接1
参考链接2
12.反射中,Class.forName 和 ClassLoader 区别。
参考链接
13.描述动态代理的几种实现方式,分别说出相应的优缺点。
Jdk cglib jdk底层是利用反射机制,需要基于接口方式,这是由于

Proxy.newProxyInstance(target.getClass().getClassLoader(),
target.getClass().getInterfaces(), this);
- 1
- 2
Cglib则是基于asm框架,实现了无反射机制进行代理,利用空间来换取了时间,代理效率高于jdk
参考链接
动态代理与 cglib 实现的区别
同上(基于invocationHandler和methodInterceptor)
14.为什么 CGlib 方式可以对接口实现代理。
同上
15.final 的用途
类、变量、方法
final 修饰的类叫最终类,该类不能被继承。
final 修饰的方法不能被重写。
final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
参考链接
16.写出三种单例模式实现。
懒汉式单例,饿汉式单例,双重检查等
参考链接
17.如何在父类中为子类自动完成所有的 hashcode 和 equals 实现?这么做有何优劣。
同时复写hashcode和equals方法,优势可以添加自定义逻辑,且不必调用超类的实现。
参考链接
18.请结合 OO 设计理念,谈谈访问修饰符 public、private、protected、default 在应用设计中的作用。
访问修饰符,主要标示修饰块的作用域,方便隔离防护
类中的数据成员和成员函数据具有的访问权限包括:public、private、protect、default(包访问权限)
作用域 当前类 同一package 子孙类 其他package
public √ √ √ √
protected √ √ √ ×
default √ √ × ×
private √ × × ×
public 所有类可见
protected 本包和所有子类都可见(本包中的子类非子类均可访问,不同包中的子类可以访问,不是子类不能访问)
default 本包可见(即默认的形式)(本包中的子类非子类均可访问,不同包中的类及子类均不能访问)
priavte 本类可见
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
public: Java语言中访问限制最宽的修饰符,一般称之为“公共的”。被其修饰的类、属性以及方法不仅可以跨类访问,而且允许跨包(package)访问。
private: Java语言中对访问权限限制的最窄的修饰符,一般称之为“私有的”。被其修饰的类、属性以及方法只能被该类的对象访问,其子类不能访问,更不能允许跨包访问。
protect: 介于public 和 private 之间的一种访问修饰符,一般称之为“保护形”。被其修饰的类、属性以及方法只能被类本身的方法及子类访问,即使子类在不同的包中也可以访问。
default:即不加任何访问修饰符,通常称为"默认访问模式"。该模式下,只允许在同一个包中进行访问。
19.深拷贝和浅拷贝区别。
参考链接
20.数组和链表数据结构描述,各自的时间复杂度
参考链接
21.error 和 exception 的区别,CheckedException,RuntimeException 的区别
参考链接
22.请列出 5 个运行时异常。
同上
23.在自己的代码中,如果创建一个 java.lang.String 对象,这个对象是否可以被类加载器加载?为什么
类加载无须等到“首次使用该类”时加载,jvm允许预加载某些类。。。。
参考链接
24.说一说你对 java.lang.Object 对象中 hashCode 和 equals 方法的理解。在什么场景下需要重新实现这两个方法。
参考上边试题(17)
25.在 jdk1.5 中,引入了泛型,泛型的存在是用来解决什么问题。
泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数,泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,以提高代码的重用率
参考链接
26.这样的 a.hashcode() 有什么用,与 a.equals(b)有什么关系。
hashcode
hashcode()方法提供了对象的hashCode值,是一个native方法,返回的默认值与System.identityHashCode(obj)一致。
通常这个值是对象头部的一部分二进制位组成的数字,具有一定的标识对象的意义存在,但绝不定于地址。
作用是:用一个数字来标识对象。比如在HashMap、HashSet等类似的集合类中,如果用某个对象本身作为Key,即要基于这个对象实现Hash的写入和查找,那么对象本身如何实现这个呢?就是基于hashcode这样一个数字来完成的,只有数字才能完成计算和对比操作。
hashcode是否唯一
hashcode只能说是标识对象,在hash算法中可以将对象相对离散开,这样就可以在查找数据的时候根据这个key快速缩小数据的范围,但hashcode不一定是唯一的,所以hash算法中定位到具体的链表后,需要循环链表,然后通过equals方法来对比Key是否是一样的。
equals与hashcode的关系
equals相等两个对象,则hashcode一定要相等。但是hashcode相等的两个对象不一定equals相等。
参考链接
27.有没有可能 2 个不相等的对象有相同的 hashcode。
有
实例:
String str1 = "通话";
String str2 = "重地";
System.out.println(String.format("str1:%d | str2:%d", str1.hashCode(),str2.hashCode()));
System.out.println(str1.equals(str2));
执行结果:str1:1179395 | str2:1179395
false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
28.Java 中的 HashSet 内部是如何工作的。
底层是基于hashmap实现的
参考链接
什么是序列化,怎么序列化,为什么序列化,反序列化会遇到什么问题,如何解决。
参考链接
29. JDK 和 JRE 有什么区别?
JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境。
JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需环境。
具体来说 JDK 其实包含了 JRE,同时还包含了编译 java 源码的编译器 javac,还包含了很多 java 程序调试和分析的工具。简单来说:如果你需要运行 java 程序,只需安装 JRE 就可以了,如果你需要编写 java 程序,需要安装 JDK。
30. == 和 equals 的区别是什么?
== 解读:
对于基本类型和引用类型 == 的作用效果是不同的,如下所示:
基本类型:比较的是值是否相同;
引用类型:比较的是引用是否相同;
实例:
String x = "string";
String y = "string";
String z = new String("string");
System.out.println(x==y); // true,引用相同
System.out.println(x==z); // false,==:string比较引用,开辟了新的堆内存空间,所以false
System.out.println(x.equals(y)); // true,equals:string:比较值,相同
System.out.println(x.equals(z)); // true,equals:string比较值,相同
- 1
- 2
- 3
- 4
- 5
- 6
- 7
equals 解读:
equals 本质上就是 ==,只不过 String 和 Integer 等重写了 equals 方法,把它变成了值比较。看下面的代码就明白了。
首先来看默认情况下 equals 比较一个(有相同值的对象),代码如下:
public class Cat {
private String name;
public Cat(String name){
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public static void main(String[] args) {
Cat c1 = new Cat("cat1");//c1是Cat的实例化对象,c2同理
Cat c2 = new Cat("cat2");
String s1 = new String("隔壁老王");
String s2 = new String("隔壁老王");
System.out.println(c1.equals(c2));//false,equals在比较的类对象的时候比较的是引用
System.out.println(s1.equals(s2)); //true,而在比较string的时候,因为重写了equals方法,和基本数据类型一样,比较的是值,所以为true
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
总结 :== 对于基本类型来说是值比较(不难理解,八种基本数据类型是可以有确定值的),对于引用类型来说是比较的是引用(数组、类、接口没有确定值);而 equals 默认情况下是引用比较,只是很多类重新了 equals 方法,比如 String、Integer 等把它变成了值比较,所以一般情况下 equals 比较的是值是否相等。
31.java 中的 Math.round(-1.5) 等于多少?
等于 -1,因为在数轴上取值时,中间值(0.5)向右取整,所以正 0.5 是往上取整,负 0.5 是直接舍弃。同理,Math.round(1.5) = 2
32.写一个字符串反转函数。
// StringBuffer reverse
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("abcdefg");
System.out.println(stringBuffer.reverse()); // gfedcba
// StringBuilder reverse
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("abcdefg");
System.out.println(stringBuilder.reverse()); // gfedcba
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
33.String 类的常用方法都有那些?
indexOf():返回指定字符的索引。
charAt():返回指定索引处的字符。
replace():字符串替换。
trim():去除字符串两端空白。
split():分割字符串,返回一个分割后的字符串数组。
getBytes():返回字符串的 byte 类型数组。
length():返回字符串长度。
toLowerCase():将字符串转成小写字母。
toUpperCase():将字符串转成大写字符。
substring():截取字符串。
equals():字符串比较。
34.抽象类必须要有抽象方法吗?
不需要,抽象类不一定非要有抽象方法。
示例代码:
public abstract class noAbstractMethod{
public static void main(String[] args) {
sayHi();
}
public static void sayHi() {
System.out.println("hi~");
}
}
结果:hi~
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
35.java 中 IO 流分为几种?
按功能来分:输入流(input)、输出流(output)。
按类型来分:字节流和字符流。
字节流和字符流的区别是:字节流按 8 位传输以字节为单位输入输出数据,字符流按 16 位传输以字符为单位输入输出数据。
36.Files的常用方法都有哪些?
Files.exists():检测文件路径是否存在。
Files.createFile():创建文件。
Files.createDirectory():创建文件夹。
Files.delete():删除一个文件或目录。
Files.copy():复制文件。
Files.move():移动文件。
Files.size():查看文件个数。
Files.read():读取文件。
Files.write():写入文件。
37.List、Set、Map 之间的区别是什么?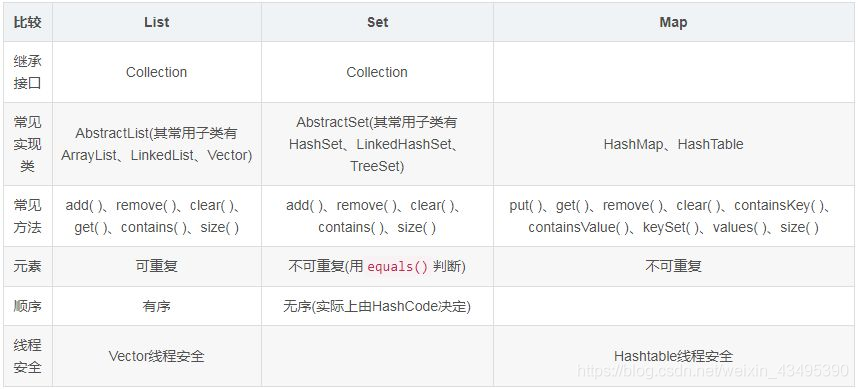
38.如何实现数组和 List 之间的转换?
List转换成为数组:调用ArrayList的toArray方法。
数组转换成为List:调用Arrays的asList方法。
39. ArrayList 和 Vector 的区别是什么?
Vector是同步的,而ArrayList不是。然而,如果你寻求在迭代的时候对列表进行改变,你应该使用CopyOnWriteArrayList。
ArrayList比Vector快,它是异步,不会过载。
ArrayList更加通用,因为我们可以使用Collections工具类轻易地获取同步列表和只读列表。
40.Array 和 ArrayList 有何区别?
Array可以容纳基本类型和对象,而ArrayList只能容纳对象。
Array是指定大小的,而ArrayList大小是固定的。
Array没有提供ArrayList那么多功能,比如addAll、removeAll和iterator等。
41.在 Queue 中 poll()和 remove()有什么区别?
poll() 和 remove() 都是从队列中取出一个元素,但是 poll() 在获取元素失败的时候会返回空,但是 remove() 失败的时候会抛出异常。
42. 哪些集合类是线程安全的?
vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
statck:堆栈类,先进后出。
hashtable:就比hashmap多了个线程安全。
enumeration:枚举,相当于迭代器。
43.迭代器 Iterator 是什么?
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
44.Iterator 怎么使用?有什么特点?
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,公共基类Collection提供iterator()方法。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
45. Iterator 和 ListIterator 有什么区别?
Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List,见名知意,Set并不能使用ListIterator
Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
ListIterator实现了Iterator接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
46.synchronized 和 volatile 的区别是什么?
volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的。
volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性。
volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化。
JVM 知识
1.什么情况下会发生栈内存溢出。
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常。 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。
参考链接
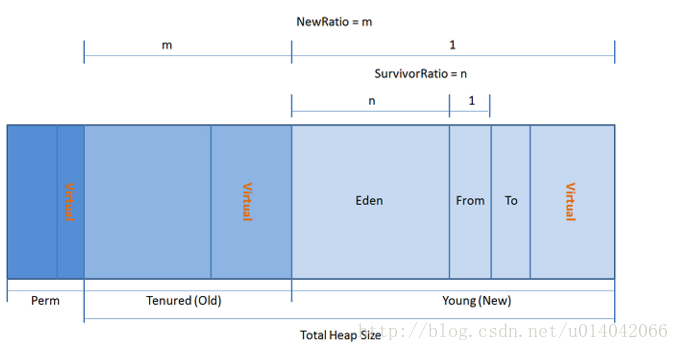
2.JVM 的内存结构,Eden 和 Survivor 比例。
eden 和 survior 是按8比1分配的
参考链接
3.jvm 中一次完整的 GC 流程是怎样的,对象如何晋升到老年代,说说你知道的几种主要的jvm 参数。
对象诞生即新生代->eden,在进行minor gc过程中,如果依旧存活,移动到from,变成Survivor,进行标记代数,如此检查一定次数后,晋升为老年代,
参考链接1
参考链接2
参考链接3
4.你知道哪几种垃圾收集器,各自的优缺点,重点讲下 cms,包括原理,流程,优缺点
Serial、parNew、ParallelScavenge、SerialOld、ParallelOld、CMS、G1
参考链接
5.垃圾回收算法的实现原理。
参考链接
6.当出现了内存溢出,你怎么排错。
首先分析是什么类型的内存溢出,对应的调整参数或者优化代码。
参考链接
7.JVM 内存模型的相关知识了解多少,比如重排序,内存屏障,happen-before,主内存,工作内存等。
内存屏障:为了保障执行顺序和可见性的一条cpu指令
重排序:为了提高性能,编译器和处理器会对执行进行重拍
happen-before:操作间执行的顺序关系。有些操作先发生。
主内存:共享变量存储的区域即是主内存
工作内存:每个线程copy的本地内存,存储了该线程以读/写共享变量的副本
参考链接1
参考链接2
参考链接3
8.简单说说你了解的类加载器。
类加载器的分类(bootstrap,ext,app,curstom),类加载的流程(load-link-init)
参考链接
9.讲讲 JAVA 的反射机制。
Java程序在运行状态可以动态的获取类的所有属性和方法,并实例化该类,调用方法的功能
参考链接
10.你们线上应用的 JVM 参数有哪些。
-server
-Xms6000M
-Xmx6000M
-Xmn500M
-XX:PermSize=500M
-XX:MaxPermSize=500M
-XX:SurvivorRatio=65536
-XX:MaxTenuringThreshold=0
-Xnoclassgc
-XX:+DisableExplicitGC
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=0
-XX:+CMSClassUnloadingEnabled
-XX:-CMSParallelRemarkEnabled
-XX:CMSInitiatingOccupancyFraction=90
-XX:SoftRefLRUPolicyMSPerMB=0
-XX:+PrintClassHistogram
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintHeapAtGC
-Xloggc:log/gc.log
11.g1 和 cms 区别,吞吐量优先和响应优先的垃圾收集器选择。
Cms是以获取最短回收停顿时间为目标的收集器。基于标记-清除算法实现。比较占用cpu资源,切易造成碎片。
G1是面向服务端的垃圾收集器,是jdk9默认的收集器,基于标记-整理算法实现。可利用多核、多cpu,保留分代,实现可预测停顿,可控。
参考链接
请解释如下 jvm 参数的含义:
-server -Xms512m -Xmx512m -Xss1024K
-XX:PermSize=256m -XX:MaxPermSize=512m -XX:MaxTenuringThreshold=20
XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly。
Server模式启动
最小堆内存512m
最大512m
每个线程栈空间1m
永久代256m
最大永久代512m
最大转为老年代检查次数20
Cms回收开启时机:内存占用80%
命令JVM不基于运行时收集的数据来启动CMS垃圾收集周期
开源框架知识
1.简单讲讲 tomcat 结构,以及其类加载器流程。
Server- --多个service
Container级别的:–>engine–》host–>context
Listenter
Connector
Logging、Naming、Session、JMX等等
通过WebappClassLoader 加载class
参考链接1
参考链接2
参考链接3
参考链接4
2.tomcat 如何调优,涉及哪些参数。
硬件上选择,操作系统选择,版本选择,jdk选择,配置jvm参数,配置connector的线程数量,开启gzip压缩,trimSpaces,集群等
参考链接
3.讲讲 Spring 加载流程。
通过listener入口,核心是在AbstractApplicationContext的refresh方法,在此处进行装载bean工厂,bean,创建bean实例,拦截器,后置处理器等。
参考链接
4.讲讲 Spring 事务的传播属性。
七种传播属性。
事务传播行为
所谓事务的传播行为是指,如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为。在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
①TransactionDefinition.PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
②TransactionDefinition.PROPAGATION_REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
③TransactionDefinition.PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
④TransactionDefinition.PROPAGATION_NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
⑤TransactionDefinition.PROPAGATION_NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
⑥TransactionDefinition.PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
⑦TransactionDefinition.PROPAGATION_NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
参考链接
5.Spring 如何管理事务的。
编程式和声明式
同上
6.Spring 怎么配置事务(具体说出一些关键的 xml 元素)。
配置事务的方法有两种:
1)、基于XML的事务配置。
<?xml version="1.0" encoding="UTF-8"?>
<!-- from the file 'context.xml' -->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd">
<!-- 数据元信息 -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@rj-t42:1521:elvis"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</bean>
<!-- 管理事务的类,指定我们用谁来管理我们的事务-->
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- 首先我们要把服务对象声明成一个bean 例如HelloService -->
<bean id="helloService" class="com.yintong.service.HelloService"/>
<!-- 然后是声明一个事物建议tx:advice,spring为我们提供了事物的封装,这个就是封装在了<tx:advice/>中 -->
<!-- <tx:advice/>有一个transaction-manager属性,我们可以用它来指定我们的事物由谁来管理。
默认:事务传播设置是 REQUIRED,隔离级别是DEFAULT -->
<tx:advice id="txAdvice" transaction-manager="txManager">
<!-- 配置这个事务建议的属性 -->
<tx:attributes>
<!-- 指定所有get开头的方法执行在只读事务上下文中 -->
<tx:method name="get*" read-only="true"/>
<!-- 其余方法执行在默认的读写上下文中 -->
<tx:method name="*"/>
</tx:attributes>
</tx