


MapReduce原理
春节遇到疫情,假期延长了,收拾下放浪的心,对工作遇到的一些技术做下小结。
前段时间一直在搞知识图谱项目,面对海量的数据,要做数据范围划分、清洗、消歧、建模,用到了MR技术,下面做下简单的记录。
一、概念:
MapReduce:是一种编程思想,即映射(map)和规约(reduce)。
二、应用场景
一般通过Hadoop处理海量离线数据。当然有兴趣的可以研究下spark,据说生态更为丰富、性能更好、功能更强。
三、MapReduce1.0运行模型
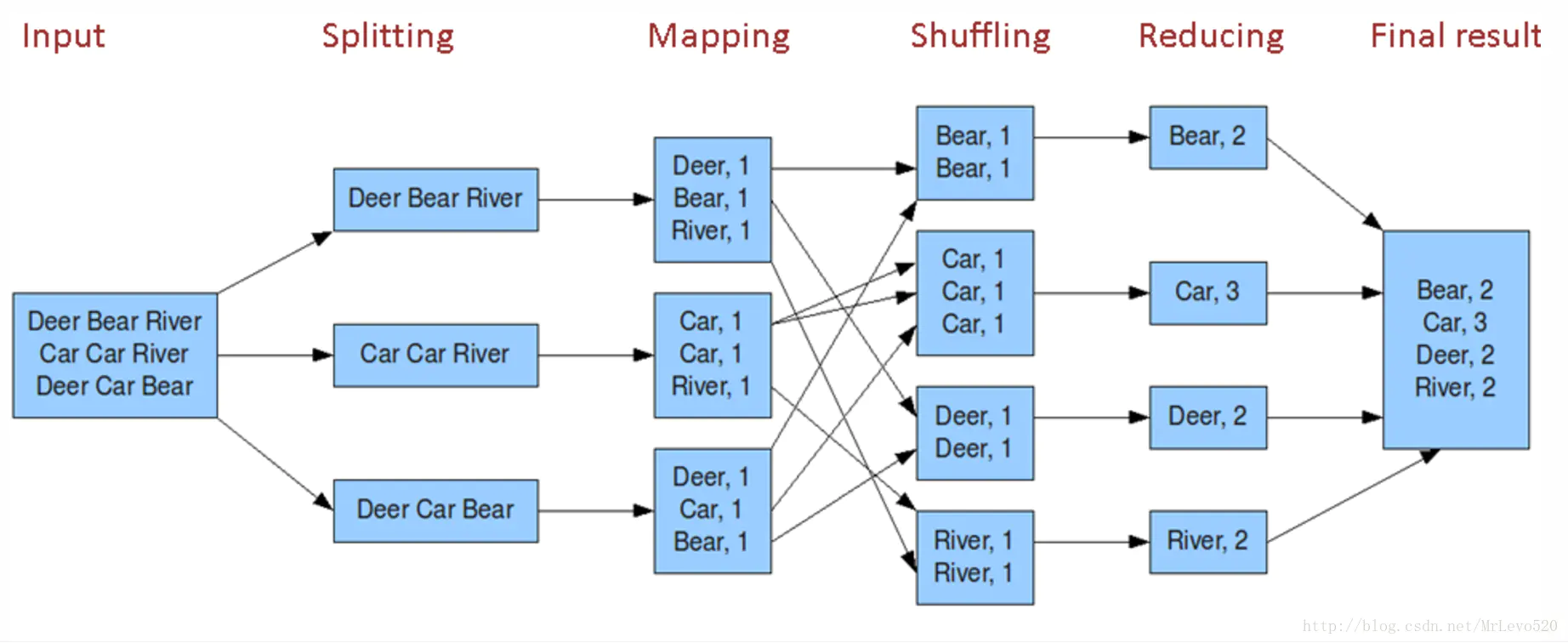
input->splitting->mapping->combing(可选)->shuffling->reduecing
combing是一个本地化的reduce过程,目的是为了提高宽带传输效率。应用这个过程原则是结果不改变最终reduce结果。
如:计算单词数量,最大值,最小值等
反之:如计算平均值不可以使用这个combine。
四、MapReduce 1.x的架构
一个JobTracker+多个taskTracker
JobTracker:负责资源管理和作业调度;
TrakTracker:定期向JobTracker汇报节点的健康、资源、作业情况,接收JT的命令,比如启动/杀死任务;
客户端:配置作业,提交作业;
HDFS:用来在其他实体之间共享作业文件,保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面;
具体如图:
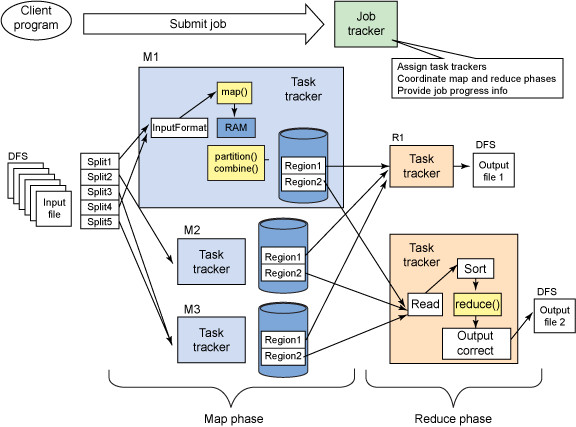
输入文件路径配置:可以是单文件、多文件,或者是单文件夹或多文件夹;
输出文件路径配置:一个MR指定一个输出文件夹。
五、处理流程

1、输入文本信息,由InputFormat -> FileInputFormat -> TextInputFormat,通过getSplits方法获得Split数组,然后在用getRecordReader 方法对Split做处理,每读一行交给一个map处理;
2、每个节点上的所有map,交由该节点上的Partitioner处理(Shuffling的过程),按key将map放在其他节点上去还是继续在该节点下处理;
3、排序;
4、结果交由reduce处理;
5、处理完成后由 OutputFormat ->FileOutputFormat ->TextOutputFormat 写到本地或Hadoop上;
Split:MR处理的的数据块,MR中最小的计算单元,默认是与HDFS中的Block(HDFS中的最小存储单元,默认128M)是一一对应的,也可以手工设置(不建议修改)
InputFormat:将输入的数据进行分片(Split) InputSplit[] getSplits(JobConf var1, int var2)
TextInputFormat:用来处理文本格式的数据
OutputFormat: 输出:
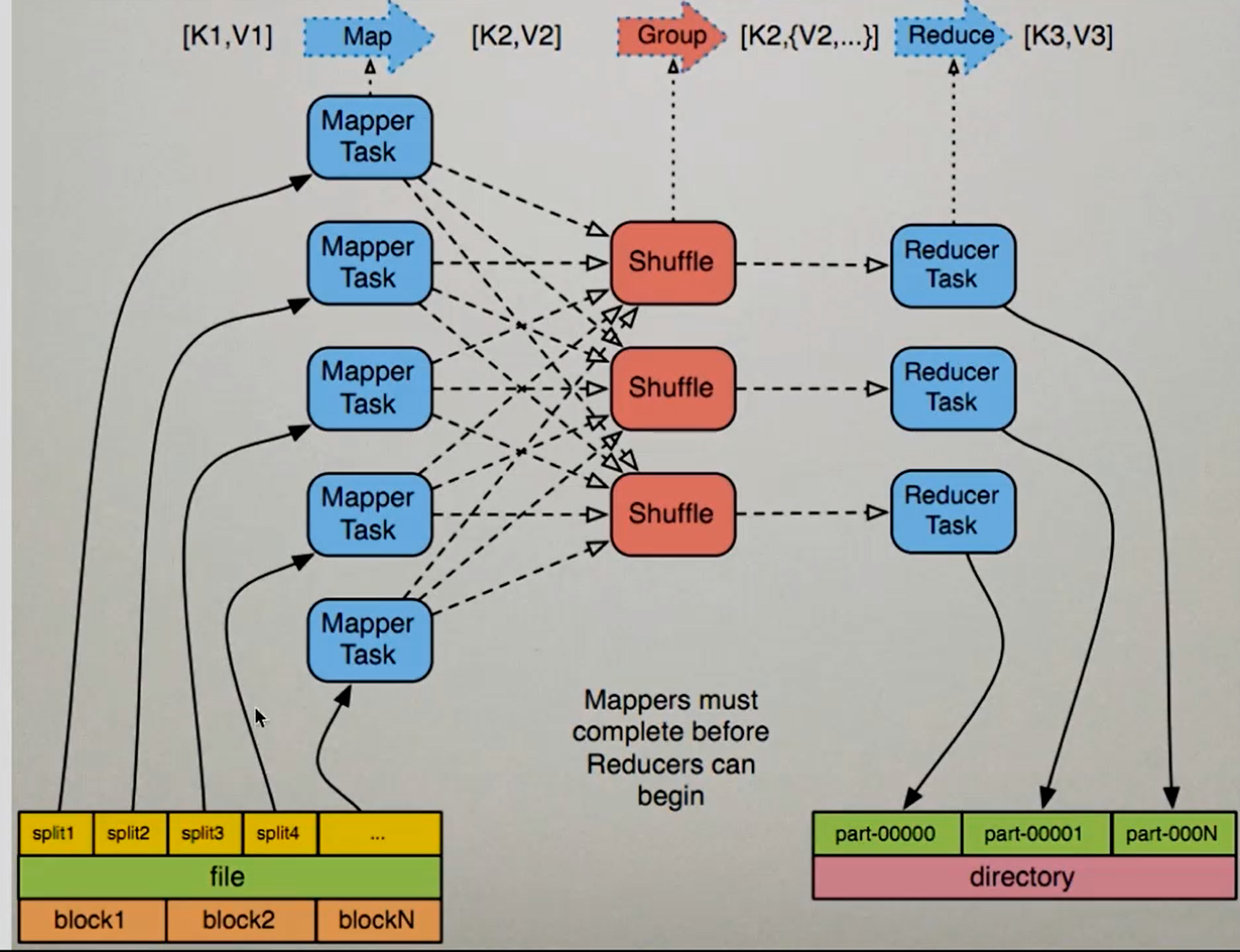
上图图解:
一般来说,一个Split对应一个Block,但上图是一个设置过后的。
一个file文件被分成了n个Block,对应着就是2n个Split,经过InputFormat处理后,每个Split交由一个Mapper处理,通过Shuffling的分组和排序后产生多个Reducer,每个Reducer就会产生一个文件
六、注意点
1、有时候为了完成业务需要,我们需要许多个MR协调工作,即MR1文件输出作为MR2的输入文件,所以尽量保证顺序靠前的MR的准确性(输入文件完整、代码质量ok),避免浪费时间重复执行;
2、多个MR协调,检查每个输入文件和输出文件路径是否正确;
3、MR执行时,最好根据业务需要统计数据并打印到输出(如:统计人口文件数据总共有那些民族等),便于根据业务分析数据是否有遗漏,和最终出报表;
参考:
https://blog.csdn.net/asd54090/article/details/80920592

