


Lucene
爬虫从网络上爬取巨量数据,数据保存如果放DB中不仅插入慢,随着数据量增大,查询性能也会越发差。最近有一个设想,能否将爬取的数据以文件形式保存,通过lucene框架建立索引的方式来满足快速搜索呢。
菜鸟起飞:
一、Lucene简介:
Lucene是Apache Jakarta家族中的一个开源项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎、索引引擎和部分文本分析引擎。
Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具,是目前最为流行的基于 Java 开源全文检索工具包。
数据总体分为两种:
结构化数据:指具有固定格式或有限长度的数据,如数据库、元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件、word文档等磁盘上的文件。
对于结构化数据的全文搜索很简单,因为数据都是有固定格式的,例如搜索数据库中数据使用SQL语句即可。
对于非结构化数据,有以下两种方法:
顺序扫描法(Serial Scanning)
全文检索(Full-text Search)
顺序扫描法
如果要找包含某一特定内容的文件,对于每一个文档,从头到尾扫描内容,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件,因此速度很慢。
全文检索
将非结构化数据中的一部分信息提取出来,重新组织,使其变得具有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如字典的拼音表和部首检字表就相当于字典的索引,通过查找拼音表或者部首检字表就可以快速的查找到我们要查的字。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
二、全文检索流程
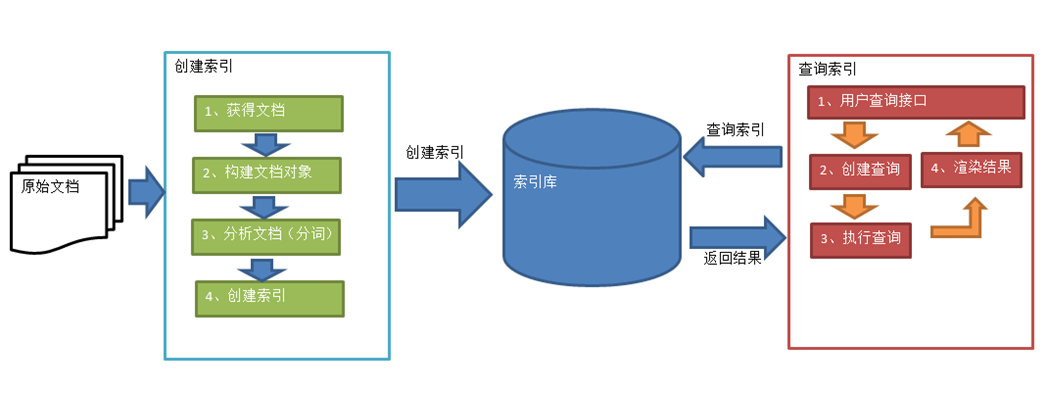
2.1 索引过程
绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
获得原始文档(原始内容即要搜索的内容)
采集文档
创建文档
分析文档
索引文档
2.1.1 获得原始文档
原始文档是指要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等等。
从互联网、数据库、文件系统中获取要搜索的原始信息,这个过程就是信息采集,信息采集的目的是对原始内容进行索引。
在互联网上采集信息的程序称为爬虫。Lucene不提供信息采集的类库,需要自己编写一个爬虫程序实现信息采集,也可以使用一些开源软件实现信息采集,如Nutch、JSoup、Heritrix等等。
对于磁盘上文件内容,可以通过IO流来读取文本文件内容,对于pdf、doc、xls等文件可以通过第三方解析工具来读取文件内容,如Apache POI等。
2.1.2 创建文档对象
获得原始内容的目的是为了创建索引,在索引前需要将原始内容创建成文档(Document),文档中包含多个域(Field),在域中存储内容。
域可以被理解为一个原始文档的属性。例如有一个文本文件test.txt,我们将这个文本文件的内容创建成文档(Document),它就包含了许多域,比如有文件名、文件大小、最后修改时间等等,如图: 
注意:每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field。
2.1.3 分析文档
将原始内容创建和包含域(Field)的文档(Document)后,需要对域中的内容进行分析,分析的过程是经过对原始文档提取单词、字母大小写转换、去除符号、去除停用词等过程后生成最终的语汇单元。
例如分析以下文档后:
Lucene is a Java full-text search engine. Lucene is not a complete application, but rather a code library and API that can easily be used to add search capabilities to applications
分析后得到的语汇单元:
lucene、java、full 、search、engine…
将每个语汇单元叫做一个term,不同的域中拆分出来的相同的语汇单元是不同的 term 。term 中包含两部分一部分是文档的域名,另一部分是内容。例如:文件名中包含 java 和文件内容中包含的 java是不同的 term 。
2.1.4 创建索引
对所有文档分析得出的语汇单元进行索引,最终要实现只搜索语汇单元就能够找到文档(Document)。
2.2 搜索过程
红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面
创建查询
执行搜索,从索引库搜索
渲染搜索结果
2.2.1 用户搜索
用户通过前端页面,将要搜索的关键字传递到后端。
2.2.2 创建查询
用户输入查询关键词执行搜索前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法。
2.2.3执行查询
根据查询对象获得对应的索引,从而找到索引所对应的文档。
2.2.4 渲染结果
以一个友好的界面将查询结果展示给用户,用户根据搜索结果找自己想要的信息,为了帮助用户很快找到自己的结果,提供了很多展示的效果,比如搜索结果中将关键字高亮显示,百度提供的快照等。
三、实现
找了个Lucene 6.6.0 的API,凑合着用
http://lucene.apache.org/core/6_6_0/core/index.html
git-hub:
https://github.com/xiaozhuanfeng/luceneProj
用springboot搭了个工程:
pom.xml
<properties> <lucene.version>6.6.2</lucene.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--工具包 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.1</version> </dependency> <!-- 引入fastjson --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.56</version> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.2</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-memory</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-backward-codecs</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queries</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>${lucene.version}</version> </dependency> </dependencies>
中文分词用IKAnalyzer,只支持到Lucene5x,下载资源,导出jar包,具体放在了gitHub中,放入工程:
package com.example.pca.lucene; import org.apache.lucene.search.TopDocs; import java.io.IOException; public interface ISearch { /** * 创建索引 * @param indexPath 索引文件路径 * @param resourcePath 资源文件路径 * @return */ boolean createIndex(String indexPath, String resourcePath) throws IOException; /** * 关键字查询 * @param indexPath 索引文件路径 * @param keyword 关键字 * @return * @throws IOException */ TopDocs queryIndex(String indexPath, String keyword)throws IOException; }
package com.example.pca.lucene.impl; import com.example.pca.lucene.ISearch; import org.apache.commons.io.FileUtils; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.TextField; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.Term; import org.apache.lucene.search.*; import org.apache.lucene.search.highlight.*; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import java.io.File; import java.io.IOException; import java.util.Collection; public abstract class AbstractSearch implements ISearch { protected Analyzer analyzer; @Override public boolean createIndex(String indexPath, String resourcePath) throws IOException { /* Step1:创建IndexWrite对象 * (1)定义词法分析器 * (2)确定索引存储位置-->创建Directory对象 * (3)得到IndexWriterConfig对象 * (4)创建IndexWriter对象 */ Directory directory = FSDirectory.open(new File(indexPath).toPath()); IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); try (IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig)) { // 清除以前的索引 indexWriter.deleteAll(); // 得到txt后缀的文件集合 Collection<File> txtFiles = FileUtils.listFiles(new File(resourcePath), new String[]{"txt"}, true); for (File file : txtFiles) { String fileName = file.getName(); String content = FileUtils.readFileToString(file, "UTF-8"); /* * Step2:创建Document对象,将Field地下添加到Document中 * Field第三个参数选项很多,具体参考API手册 */ Document document = new Document(); document.add(new Field("fileName", fileName, TextField.TYPE_STORED)); document.add(new Field("content", content, TextField.TYPE_STORED)); /* *Step4:使用 IndexWrite对象将Document对象写入索引库,并进行索引。 */ indexWriter.addDocument(document); } } return false; } @Override public TopDocs queryIndex(String indexPath, String keyword) throws IOException { TopDocs topDocs = null; /* * Step1:创建IndexSearcher对象 * (1)创建Directory对象 * (2)创建DirectoryReader对象 * (3)创建IndexSearcher对象 */ Directory directory = FSDirectory.open(new File(indexPath).toPath()); try (DirectoryReader reader = DirectoryReader.open(directory)) { IndexSearcher indexSearcher = new IndexSearcher(reader); /* * Step2:创建TermQuery对象,指定查询域和查询关键词 */ Term fTerm = new Term("fileName", keyword); Term cTerm = new Term("content", keyword); TermQuery query1 = new TermQuery(fTerm); TermQuery query2 = new TermQuery(cTerm); /* * Step3:创建Query对象 */ Query booleanBuery = new BooleanQuery.Builder().add(query1, BooleanClause.Occur.SHOULD).add(query2, BooleanClause.Occur.SHOULD) .build(); topDocs = indexSearcher.search(booleanBuery, 100); System.out.println("共找到 " + topDocs.totalHits + " 个文件匹配"); //打印结果 printTopDocs(topDocs.scoreDocs, indexSearcher, getHighlighter(booleanBuery)); } catch (InvalidTokenOffsetsException e) { e.printStackTrace(); } return topDocs; } /** * 返回高亮对象 * * @param query * @return */ private Highlighter getHighlighter(Query query) { // 格式化器 Formatter formatter = new SimpleHTMLFormatter("<em>", "</em>"); //算分 QueryScorer scorer = new QueryScorer(query); // 准备高亮工具 Highlighter highlighter = new Highlighter(formatter, scorer); //显示得分高的片段,片段字符长度fragmentSize=1000 Fragmenter fragmenter = new SimpleSpanFragmenter(scorer, 200); //设置片段 highlighter.setTextFragmenter(fragmenter); return highlighter; } private void printTopDocs(ScoreDoc[] scoreDocs, IndexSearcher indexSearcher, Highlighter highlighter) throws IOException, InvalidTokenOffsetsException { for (ScoreDoc scoreDoc : scoreDocs) { Document doc = indexSearcher.doc(scoreDoc.doc); String fileName = doc.get("fileName"); System.out.println("fileName=" + fileName); if (null != highlighter) { //高亮处理 String content = doc.get("content"); System.out.println(content); System.out.println("===================="); String hContent = highlighter.getBestFragment(analyzer, "content", content); System.out.println(hContent); } System.out.println(); } } }
package com.example.pca.lucene.analyzer; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.wltea.analyzer.lucene.IKAnalyzer; @Configuration public class AnalyzerConfig { @Bean("standardAnalyzer") public Analyzer getStandardAnalyzer() { // 使用标准分词器,但对于中文颇为无力 //lucene自带分词器,SmartChineseAnalyzer() //缺点:扩展性差,扩展词库、禁用词库和同义词库等不好处理 /* 第三方分词器 paoding:庖丁解牛,但是其最多只支持到Lucene3,已经过时,不推荐使用。 mmseg4j:目前支持到Lucene6 ,目前仍然活跃,使用mmseg算法。 参考:https://www.jianshu.com/p/03f4a906cfb5 IK-Analyzer:开源的轻量级的中文分词工具包,官方支持到Lucene5。 */ return new StandardAnalyzer(); } @Bean("iKAnalyzer") public Analyzer getIKAnalyzer() { //IK分词,试了下,也可以支持中文 return new IKAnalyzer(); } }
package com.example.pca.lucene.impl; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.springframework.beans.factory.InitializingBean; import org.springframework.stereotype.Service; import javax.annotation.Resource; @Service(value = "englishSearch") public class EnglishSearch extends AbstractSearch implements InitializingBean { @Resource(name = "standardAnalyzer") private Analyzer standardAnalyzer; @Override public void afterPropertiesSet() throws Exception { super.analyzer = standardAnalyzer; } }
package com.example.pca.lucene.impl; import org.apache.lucene.analysis.Analyzer; import org.springframework.beans.factory.InitializingBean; import org.springframework.stereotype.Service; import org.wltea.analyzer.lucene.IKAnalyzer; import javax.annotation.Resource; @Service(value = "chineseSearch") public class ChineseSearch extends AbstractSearch implements InitializingBean { @Resource(name = "iKAnalyzer") private Analyzer iKAnalyzer; @Override public void afterPropertiesSet() throws Exception { super.analyzer = iKAnalyzer; } }
package com.example.pca.lucene; import com.example.pca.utils.ProjectPathUtils; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import javax.annotation.Resource; import java.io.IOException; import static com.example.pca.lucene.constants.FilePkg.FILE_PKG; import static com.example.pca.lucene.constants.FilePkg.INDEX_PKG; @RunWith(SpringRunner.class) @SpringBootTest public class luceneTest { /** * F:\xxxx\ideaProjects\luceneProj\luceneResource\ */ private static final String RESOURCE_PATH = ProjectPathUtils.getProjPath("luceneProj") + FILE_PKG.getPkgName(); /** * F:\xxxx\ideaProjects\luceneProj\luceneIndex\ */ private static final String INDEX_PATH = ProjectPathUtils.getProjPath("luceneProj") + INDEX_PKG.getPkgName(); @Resource(name = "englishSearch") private ISearch englishSearch; @Resource(name = "chineseSearch") private ISearch chineseSearch; @Test public void test1() { System.out.println(RESOURCE_PATH); System.out.println(INDEX_PATH); } @Test public void test2() { try { englishSearch.createIndex(INDEX_PATH + "US\\", RESOURCE_PATH +"US\\"); englishSearch.queryIndex(INDEX_PATH +"US\\", "spring"); }catch (IOException e) { e.printStackTrace(); } } @Test public void test3() { try { chineseSearch.createIndex(INDEX_PATH +"EN\\", RESOURCE_PATH + "EN\\"); chineseSearch.queryIndex(INDEX_PATH +"EN\\", "孙悟空"); }catch (IOException e) { e.printStackTrace(); } } }
在英文资源文件目录下放入文件,测试test2:

中文资源测试,test3
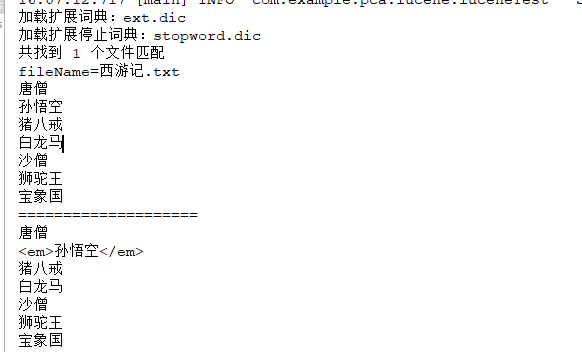
同时测了下,IK分词也是可以支持英文的
@Test public void test4() { try { chineseSearch.createIndex(INDEX_PATH +"US\\", RESOURCE_PATH + "US\\"); chineseSearch.queryIndex(INDEX_PATH +"US\\", "spring"); }catch (IOException e) { e.printStackTrace(); } }
结束语:本人菜鸟一枚,权当作学习,知道有这么个东东。
参考:
https://blog.csdn.net/yuanlaijike/article/details/79452884
https://blog.csdn.net/joker233/article/details/51909833
资源:
https://mvnrepository.com/artifact/com.chenlb.mmseg4j
LK分词器资源
https://blog.csdn.net/m0_37609579/article/details/77865183

