
皮尔逊、斯皮尔曼、肯德尔相关系数
相关系数和特征选择
相关系数和特征选择,一个是属性,一个是特征。一般,把数据集中的各列成为属性,而对算法模型表现有益的属性成为特征。例如,在预测泰坦尼克乘客的存活情况时,乘客姓名这个属性对我们的预测可能没有帮助,甚至会干扰模型表现;而乘客年龄、性别或许与存活情况有很强的关系,这时,可以称他们为特征。特征选择其实是区分属性与特征的一个过程。特征选择有多种方式,比如基于统计的特征选择和基于模型的特征选择,而基于同济的特征选择又可以细分为基于相关系数和基于假设检验这两种方式。
相关系数介绍
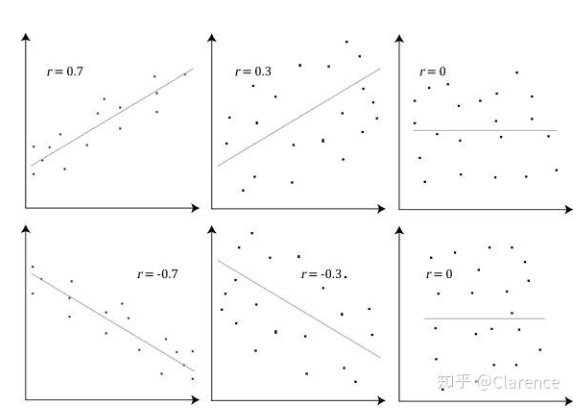
相关系数是变量间相关程度的度量,取值范围介于-1到1之间。正值表示正相关,即变量变化方向是一致的,比如Y随着X的变化而变大;负值表示负相关,变量的变化方向相反,比如Y随着X的变大而变小。绝对值越接近1,表示两个变量之间关系越密切;越接近0,表示两个变量之间的关系越不密切。相关系数对应的相关强度如下:
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
相关系数也称为线性相关系数,这是因为,相关系数并不是刻画了X,Y之间一般关系的程度,而只是线性关系的程度。当先关系数为1或-1时,两者有严格的线性关系;当相关系数为0时,则成X与Y不相关。不相关是指X和Y之间没有线性关系,但X与Y之间可能有其他的函数关系,比如平方关系,对数关系(可以通过散点图来确定这一点)
相关系数有多种定义方式,最常见的是皮尔逊相关系数,除此之外,还有斯皮尔曼秩相关系数和肯德尔秩相关系数。我们通常所说的相关系数是指皮尔逊相关系数。
皮尔逊相关系数
皮尔逊相关系数适用场景是呈正态分布的连续变量,当数据集的数量超过500时,可以近似认为数据呈正态分布,因为按照中心极限定理,当数据量足够大时,可以认为数据时近似正态分布的。
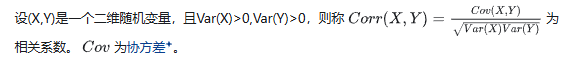
下面通过一个例子来理解协方差的公式计算。
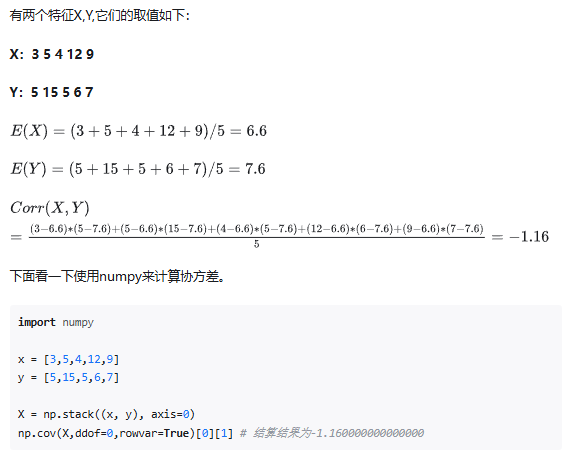
根据协方差的定义,可以知道协方差可以为正、为负,也可以为零。

从上面可以看出,协方差其实已经是在计算X与Y的相关程度了。但是协方差是有量纲的量,即有单位的量。举个例子,X表示身高,单位是cm,Y表示体重,单位是kg,那协方差计算出来后单位是cm*kg。假设我们想比较身高和体重的相关度与身高和年龄的相关度,会发现,两者的单位不一致,不太好比较。所以,为了消除量纲的影响,对协方差除以相同的量纲的量,就得到了相关系数。
与平均值和标准差一样,皮尔逊相关系数对离群值敏感,对此,可以采用“掐头去尾”的方法,减少离群值的影响。尽管如此,数据科学家在进行数据探索时,通常还会使用皮尔逊相关系数。
与皮尔逊相关系数相比,斯皮尔曼相关系数、肯德尔相关系数,是基于数据秩的相关系数。由于这些估计量操作的是秩,而非数据值,所以它们对离群值稳健, 并可以处理特定类型的非线性关系。多数情况下, 基于秩的估计量适用于小规模的数据集以及特定的假设检验。
斯皮尔曼相关系数
斯皮尔曼相关系数,又称斯皮尔曼秩相关系数,是秩相关系数的一种。“秩”,即秩序,可以理解为一种顺序或排序,根据变量在数据内的位置进行计算。
与皮尔逊相关系数相比,斯皮尔曼相关系数没有那些限制,比如要符合正态分布、样本容量要超过一定数量(比如30个),除此之外,斯皮尔曼相关系数不受离群值影响,适用于非线性。对于斯皮尔曼相关系数,我们不需要关心数据如何变化,符合什么样的分布,只需要关心每个变量对应数值的位置。如果两个变量的对应值,在各组内的排列顺位是相同或类似的(或者理解为一个变量是另外一个变量的严格单调函数),则具有显著的相关性。

从上面的计算过程可以看出,斯皮尔曼相关系数基于秩去计算,异常值要么排在第一要么排在最后,因此,受异常值的影响非常小。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~