
变分自编码器VAE
基本思路
把一堆真实样本通过编码器网络变换成一个理想的数据分布,然后这个数据分布再传递给一个编码器网络,得到一堆生成样本,生成样本与真实样本足够接近的话,就训练出了一个自编码器模型。那VAE就是在自编码器模型上进一步变分处理,使得编码器的输出结果能对应到目标分布的均值和方差,如下图所示:
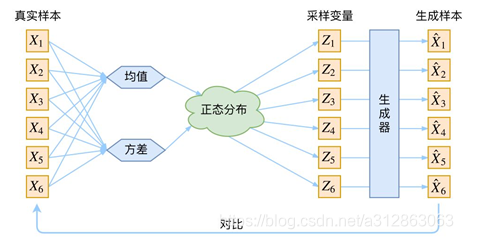
VAE的设计思路
VAE最想解决的问题是如何构造编码器和解码器,使得图片能够编码成易于表示的形态,并且这一形态能够尽可能无损地解码回原始真实图像。
这似乎听起来与PCA有些相似,而PCA本身是用来做矩阵降维的:
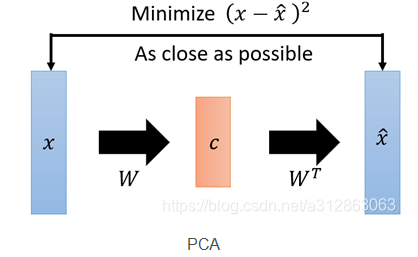
如图,
回顾上述介绍,我们会发现PCA与我们想要构造的自编码器的相似之处是在于,如果把矩阵
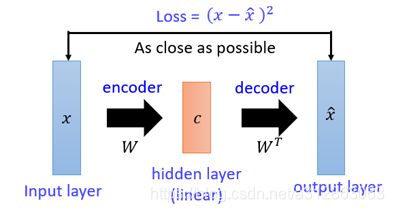
现在我们需要对这一雏形进行改进。首先一个最明显能改进的地方就是用神经网络代替
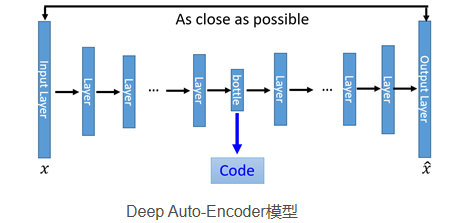
这一替代的明显好处是,引入了神经网络强大的拟合能力,使得编码的维度能够比原始图像(X)的维度低非常多。在一个手写数字图像的生成模型中,Deep Auto Encoder能够把一个784维的向量(28*28图像)压缩到只有3维,并且解码回的图像具备清楚的辨认度。
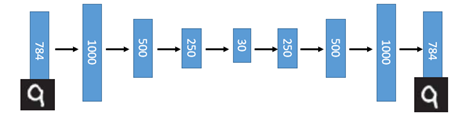
至此我们构造出了一个重构图像比较清晰的自编码模型,但这并没有达到我们真正想要构造的生成模型的标准,因为,对于一个生成模型而言,解码器部分应该是单独能够提取出来的,并且对于在规定维度下任意采样的一个编码,都应该能通过解码器产生一张清晰且真实的图像。
我们先来分析一下现有模型无法达到这一标准的原因。
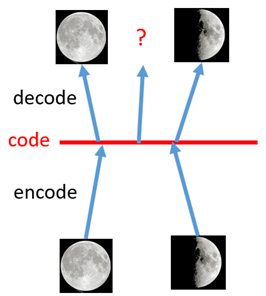
如上图所示,假设有两张训练图片,一张是全月图,一张是半月图,经过训练我们的自编码器模型已经能无损地还原这两张图片。接下来,我们在code空间上,两张图片的碧娜骂起点中间处取一点,然后将这一点交给解码器,我们希望新的生成图片是一张清晰的图片(类似3/4全月的样子)。但是,实际的结果是,生成图片是模糊且无法辨认的乱码图。一个比较合理的解释是,因为编码和解码的过程使用了深度神经网络,这是一个非线性的变换过程,所以在code空间上点与点之间的迁移是非常没有规律的。
如何解决这个问题呢?我们可以引入噪声,使得图片的编码区域得到扩大,从而掩盖掉失真的空白编码点。通过增加输入的多样性从而增强输出的鲁棒性。当我们给输入图片进行编码之前引入一点噪声,使得每张图片的编码点出现在绿色箭头范围内,这样一来所得到的latent space 就能覆盖到更多的编码点。此时我们再从中间点抽取去还原便可以得到一个我们比较希望得到的输出。
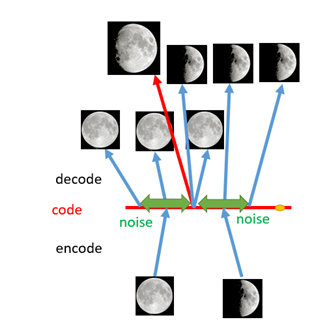
如上图所示,现在在给两张图片编码的时候加上一点噪音,使得每张图片的编码点出现在绿色箭头所示范围内,于是在训练模型的时候,绿色箭头范围内的点都有可能被采样到,这样解码器在训练时会把绿色范围内的点都尽可能还原成和原图相似的图片。然后我们可以关注之前那个失真点,它处于全月图和半月图编码的交界上,于是解码器希望它既要尽量相似于全月图,又要尽量相似于半月图,于是它的还原结果就是两种图的折中。
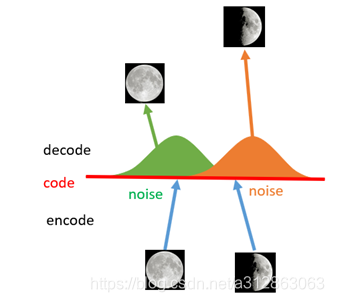
因此我们发现,给编码器增添一些噪音,可以有效覆盖失真区域。不过这还并不充分,因为在上图的距离训练区域很远的黄色点处,它依然不会被覆盖到,仍是个失真点。为了解决这个问题,我们试图把噪音无限拉大,使得对于每一个样本呢,它的编码会覆盖整个编码空间,不过我们得保证,在原编码附近编码的概率最高,离原编码点越远,编码概率越低。在这种情况下,图像的编码就由原先离散的编码点变成了一条连续的编码分布曲线,如下图所示:
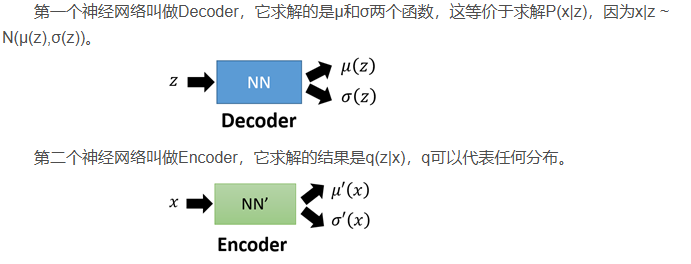
VAE的模型架构
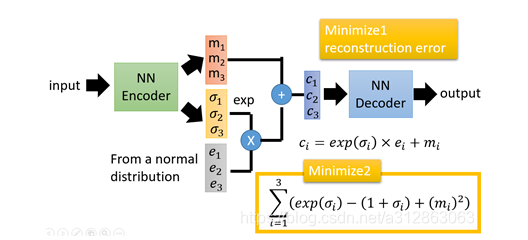
在auto-encoder中,编码器是直接产生一个编码的,但是在VAE中,为了给编码添加合适的噪音,编码器会输出两个编码,一个是原有编码
方差
损失函数方面,除了必要的重构损失外,VAE还增添了一个损失函数,这同样是必要的部分,因为如果不加的话,整个模型就会出现问题:为了保证生成图片的质量越高,编码器肯定希望噪音对自身生成图片的干扰越小,于是分配给噪音的权重越小,这样只需要将
隐变量
隐变量是指通过模型从观测数据中推断出来的变量。比如,我们将一个输入对象送入一个神经网络的编码层,得到的由隐含层输出的向量就可以成为latent variable。
variations,变分法
泛函
将一个给定的输入数值
变分法就是用于求泛函数的极值。
VAE的作用原理
对于生成模型,主流的理论模型可以分为隐马尔可夫模型HMM、朴素贝叶斯模型NB和高斯混合模型GMM,而VAE的理论基础就是高斯混合模型。
高斯混合模型:任何一个数据的分布,都可以看作是若干高斯分布的叠加。
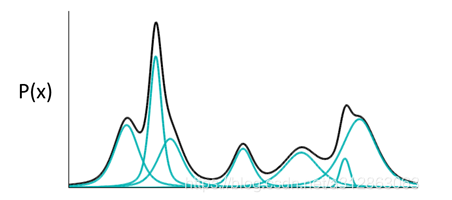
于是我们可以利用这一理论模型去考虑如何给数据进行编码。一种最直接的思路是,直接用每一组高斯分布的参数作为一个编码值实现编码。
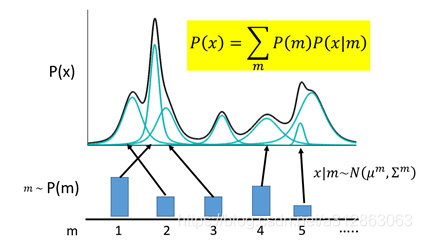
如上图所示,
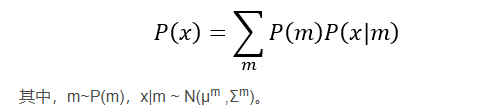

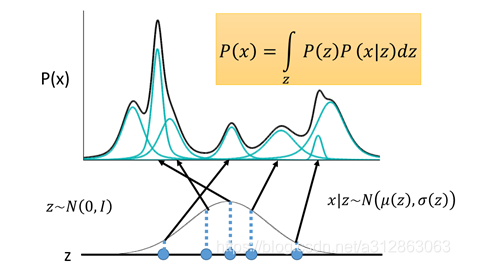

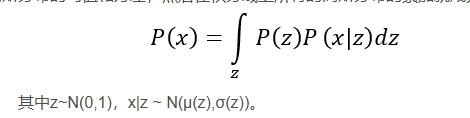

从宏观角度来看,调节
条件概率
定义两个时间A和事件B,求A和B同时发生的概率:
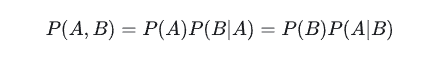
KL散度,又称KL距离或者相对熵,用于衡量两个概率分布之间的距离。
给定真实分布
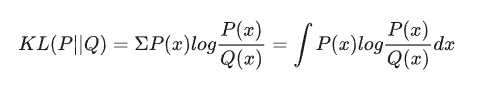
KL散度的一些性质:

代码
# -*- coding: utf-8 -*-
"""
VAE on mnist
"""
import torch
import matplotlib.pyplot as plt
from torchvision import datasets, transforms
from torch import nn, optim
from torch.nn import functional as F
from tqdm import tqdm
import os
os.chdir(os.path.dirname(__file__))
'模型结构'
class Encoder(torch.nn.Module):
#编码器,将input_size维度数据压缩为latent_size维度的mu和sigma
def __init__(self, input_size, hidden_size, latent_size):
super(Encoder, self).__init__()
self.linear = torch.nn.Linear(input_size, hidden_size)
self.mu = torch.nn.Linear(hidden_size, latent_size)
self.sigma = torch.nn.Linear(hidden_size, latent_size)
def forward(self, x):# x: bs,input_size
x = F.relu(self.linear(x)) #-> bs,hidden_size
mu = self.mu(x) #-> bs,latent_size
sigma = self.sigma(x)#-> bs,latent_size
return mu,sigma
class Decoder(torch.nn.Module):
#解码器,将latent_size维度的数据转换为output_size维度的数据
def __init__(self, latent_size, hidden_size, output_size):
super(Decoder, self).__init__()
self.linear1 = torch.nn.Linear(latent_size, hidden_size)
self.linear2 = torch.nn.Linear(hidden_size, output_size)
def forward(self, x): # x:bs,latent_size
x = F.relu(self.linear1(x)) #->bs,hidden_size
x = torch.sigmoid(self.linear2(x)) #->bs,output_size
return x
class VAE(torch.nn.Module):
#将编码器解码器组合
def __init__(self, input_size, output_size, latent_size, hidden_size):
super(VAE, self).__init__()
self.encoder = Encoder(input_size, hidden_size, latent_size)
self.decoder = Decoder(latent_size, hidden_size, output_size)
def forward(self, x): #x: bs,input_size
# 压缩,获取mu和sigma
mu,sigma = self.encoder(x) #mu,sigma: bs,latent_size
# 采样,获取采样数据
eps = torch.randn_like(sigma) #eps: bs,latent_size
z = mu + eps*sigma #z: bs,latent_size
# 重构,根据采样数据获取重构数据
re_x = self.decoder(z) # re_x: bs,output_size
return re_x,mu,sigma
#损失函数
#交叉熵,衡量各个像素原始数据与重构数据的误差
loss_BCE = torch.nn.BCELoss(reduction = 'sum')
#均方误差可作为交叉熵替代使用.衡量各个像素原始数据与重构数据的误差
loss_MSE = torch.nn.MSELoss(reduction = 'sum')
#KL散度,衡量正态分布(mu,sigma)与正态分布(0,1)的差异,来源于公式计算
loss_KLD = lambda mu,sigma: -0.5 * torch.sum(1 + torch.log(sigma**2) - mu.pow(2) - sigma**2)
'超参数及构造模型'
#模型参数
latent_size =16 #压缩后的特征维度
hidden_size = 128 #encoder和decoder中间层的维度
input_size= output_size = 28*28 #原始图片和生成图片的维度
#训练参数
epochs = 20 #训练时期
batch_size = 32 #每步训练样本数
learning_rate = 1e-4 #学习率
device =torch.device('cuda' if torch.cuda.is_available() else 'cpu')#训练设备
#确定模型,导入已训练模型(如有)
modelname = 'vae.pth'
model = VAE(input_size,output_size,latent_size,hidden_size).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
try:
model.load_state_dict(torch.load(modelname))
print('[INFO] Load Model complete')
except:
pass
'训练模型'
#准备mnist数据集 (数据会下载到py文件所在的data文件夹下)
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('/data', train=True, download=True,
transform=transforms.ToTensor()),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('/data', train=False, transform=transforms.ToTensor()),
batch_size=batch_size, shuffle=False)
#训练及测试
loss_history = {'train':[],'eval':[]}
for epoch in range(epochs):
#训练
model.train()
#每个epoch重置损失,设置进度条
train_loss = 0
train_nsample = 0
t = tqdm(train_loader,desc = f'[train]epoch:{epoch}')
for imgs, lbls in t: #imgs:(bs,28,28)
bs = imgs.shape[0]
#获取数据
imgs = imgs.to(device).view(bs,input_size) #imgs:(bs,28*28)
#模型运算
re_imgs, mu, sigma = model(imgs)
#计算损失
loss_re = loss_BCE(re_imgs, imgs) # 重构与原始数据的差距(也可使用loss_MSE)
loss_norm = loss_KLD(mu, sigma) # 正态分布(mu,sigma)与正态分布(0,1)的差距
loss = loss_re + loss_norm
#反向传播、参数优化,重置
loss.backward()
optimizer.step()
optimizer.zero_grad()
#计算平均损失,设置进度条
train_loss += loss.item()
train_nsample += bs
t.set_postfix({'loss':train_loss/train_nsample})
#每个epoch记录总损失
loss_history['train'].append(train_loss/train_nsample)
#测试
model.eval()
#每个epoch重置损失,设置进度条
test_loss = 0
test_nsample = 0
e = tqdm(test_loader,desc = f'[eval]epoch:{epoch}')
for imgs, label in e:
bs = imgs.shape[0]
#获取数据
imgs = imgs.to(device).view(bs,input_size)
#模型运算
re_imgs, mu, sigma = model(imgs)
#计算损失
loss_re = loss_BCE(re_imgs, imgs)
loss_norm = loss_KLD(mu, sigma)
loss = loss_re + loss_norm
#计算平均损失,设置进度条
test_loss += loss.item()
test_nsample += bs
e.set_postfix({'loss':test_loss/test_nsample})
#每个epoch记录总损失
loss_history['eval'].append(test_loss/test_nsample)
#展示效果
#按标准正态分布取样来自造数据
sample = torch.randn(1,latent_size).to(device)
#用decoder生成新数据
gen = model.decoder(sample)[0].view(28,28)
#将测试步骤中的真实数据、重构数据和上述生成的新数据绘图
concat = torch.cat((imgs[0].view(28, 28),
re_imgs[0].view( 28, 28), gen), 1)
plt.matshow(concat.cpu().detach().numpy())
plt.show()
#显示每个epoch的loss变化
plt.plot(range(epoch+1),loss_history['train'])
plt.plot(range(epoch+1),loss_history['eval'])
plt.show()
#存储模型
torch.save(model.state_dict(),modelname)
'调用模型'
#按标准正态分布取样来自造数据
sample = torch.randn(1,latent_size).to(device)
#用decoder生成新数据
generate = model.decoder(sample)[0].view(28,28)
#展示生成数据
plt.matshow(generate.cpu().detach().numpy())
plt.show()
后验坍塌
一般认为解码器
当后验不坍塌时:
换句话说encoder部分,从
当后验发生坍塌:当输入
当后验发生坍塌:当输入
-
噪声过大意味着
-
信号太弱:
训练
decoder未训练好: MSEloss远远大于KL loss,适当降低噪声,则KL损失增加
decoder训练不错:MSE loss 小于KL loss,噪声增加, KLloss减小,使得拟合变得困难,MSE 增大,decoder想办法提高生成能力
参考文献:
https://blog.csdn.net/a312863063/article/details/87953517
https://zhuanlan.zhihu.com/p/620113235
https://zhuanlan.zhihu.com/p/112513743
https://blog.csdn.net/wr1997/article/details/115255712


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律