
向量变分自动编码器(VQ-VAE)
Oord等人的这篇论文提出了使用离散潜在嵌入进行变分自动编码的想法。提出的模型成为向量量化变分自动编码器
基本思想
VAE由3部分组成:
1.一个编码器网络,参数化潜在的后验
2.先验分布
3.输入数据分布为
通常我们假设先验和后验呈对角方差正态分布。然后使用编码器来预测后验的均值和方差。
然而,作者使用离散潜在变量(而不是连续正态分布)。后验分布和先验分布是分类的,从这些分布中抽取的样本索引表。换句话说:
1.编码器对分类分布进行建模,从中进行采样以获得整数值
2.这些整数值用于索引嵌入字典
3.然后将索引值传递给解码器
为什么要这样做?
许多重要的现实世界对象都是离散的。例如,在图像中,我们可能有“猫”、“汽车”等类别,并且在这些类别之间进行插值可能没有意义。离散表示也更容易建模。因为每个类别都有一个值,而如果我们有一个连续的潜在空间,那么我们将需要规范化这个密度函数并学习不同变量之间的依赖关系,这可能非常复杂。
此外,作者声称他们的模型不会遭受后塌陷的影响,而后塌陷是一个普遍困扰VAE并妨碍使用复杂解码器的问题。
架构
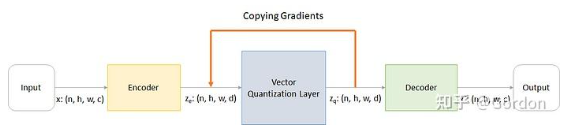
通过以下步骤解释工作原理:
1.编码器接收图像
2.矢量量化层采用
3.解码器消耗
矢量量化层
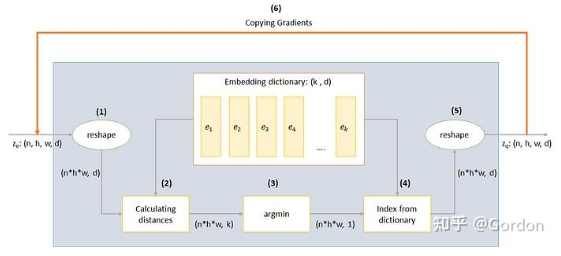
VQ层的工作通过上图中编码的六个步骤来解释:
1.reshape:除了最后一维之外的所有维度都合并为一,这样我们就有
2.计算距离:对于每个
3.argmin:为每个
4.字典索引:为每个
5.reshape:转换回形状
6.幅值梯度:如果您跟进到现在,您会意识到不可能通过反向传播来训练该架构,因为梯度不会流过argmin。因此,我们尝试通过将梯度从
损失函数
总损失实际上油三个部分组成:
1.重建损失:优化解码器和编码器
reconstruction_loss = -log( p(x|z_q) )
2.代码本损失:由于梯度绕过嵌入,我们使用字典学习算法,该算法使用L2误差将嵌入向量
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
// sg 表示停止梯度运算符,意味着没有梯度 stop gradient
3.commitment量化损失:由于嵌入空间的体积是无量纲的,如果嵌入
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
// β 是一个超参数,控制我们想要衡量的Commitment损失与其他组件相比的多少
代码
结论
从这篇论文中我们可以学习到两个主要思想:
1.如何训练离散潜在嵌入及其重要性
2.如何在不可微函数的情况下近似梯度


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架