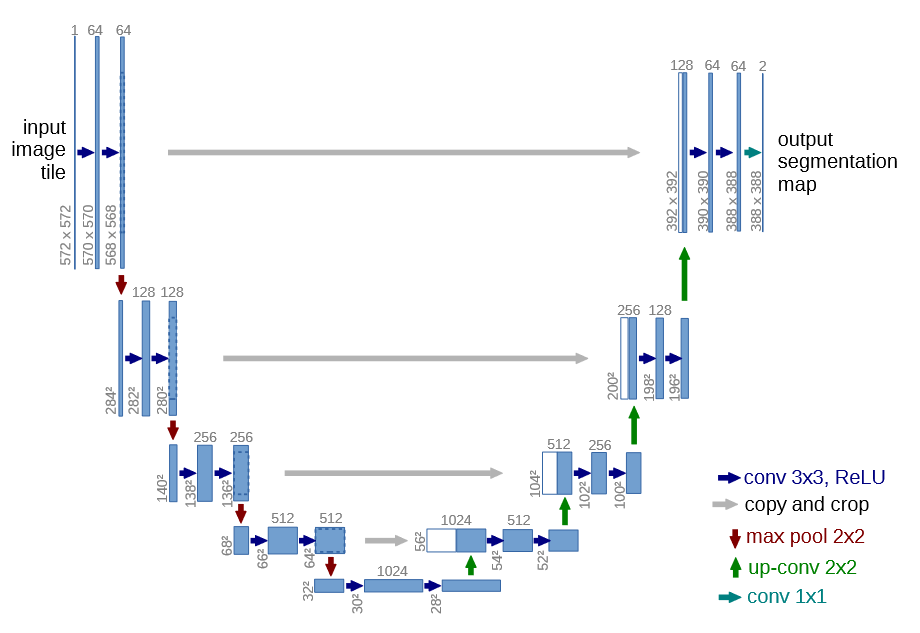
UNet 网络
网络结构
-
conv 3 \(\times\) 3, ReLU : 就是卷积层,其中卷积核大小是3 \(\times\) 3 ,然后经过Relu激活。
-
copy and crop :意思是复制和裁剪。对于输出的尺寸,进行复制并进行中心裁剪,方便和后面上采样生成的尺寸进行拼接。
-
max pool 2 \(\times\) 2 :就是最大池化层,卷积核为2 \(\times\) 2。
-
up-conv 2 \(\times\) 2:反卷积,来实现上采样。
-
conv 1 \(\times\) 1:这里就是卷积层,卷积和的大小为2 \(\times\) 2。
代码
左边代码
第一块内容
# 由572*572*1变成了570*570*64
self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0)
self.relu1_1 = nn.ReLU(inplace=True)
# 由570*570*64变成了568*568*64
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0)
self.relu1_2 = nn.ReLU(inplace=True)
由Unet网络架构图,可以看出输入图像是1x572x572大小,其中的1代表的是通道数(后续可以自己更改成自己想要的,比如3通道),输出通道是64,并且通过conv3x3,得知卷积核为3x3尺寸,并且由图片中的尺寸变成570x570,因此可以得出相关的参数值in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0,整个图片的蓝色箭头的卷积操作都是这样,因此kernel_size=3, stride=1, padding=0可以固定了。只需要更改输入和输出通道数的大小即可。
最大池化层1
# 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2)
第二块内容
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128
self.relu2_2 = nn.ReLU(inplace=True)
最大池化层2
# 采用最大池化进行下采样 280*280*128->140*140*128
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2)
Unet左边部分汇总
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0) # 由572*572*1变成了570*570*64
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 由570*570*64变成了568*568*64
self.relu1_2 = nn.ReLU(inplace=True)
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128
self.relu2_2 = nn.ReLU(inplace=True)
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 280*280*128->140*140*128
self.conv3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0) # 140*140*128->138*138*256
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 138*138*256->136*136*256
self.relu3_2 = nn.ReLU(inplace=True)
self.maxpool_3 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 136*136*256->68*68*256
self.conv4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0) # 68*68*256->66*66*512
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 66*66*512->64*64*512
self.relu4_2 = nn.ReLU(inplace=True)
self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 64*64*512->32*32*512
self.conv5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0) # 32*32*512->30*30*1024
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=0) # 30*30*1024->28*28*1024
self.relu5_2 = nn.ReLU(inplace=True)
左边的前向传播
def forward(self, x):
x1 = self.conv1_1(x)
x1 = self.relu1_1(x1)
x2 = self.conv1_2(x1)
x2 = self.relu1_2(x2) # 这个后续需要使用
down1 = self.maxpool_1(x2)
x3 = self.conv2_1(down1)
x3 = self.relu2_1(x3)
x4 = self.conv2_2(x3)
x4 = self.relu2_2(x4) # 这个后续需要使用
down2 = self.maxpool_2(x4)
x5 = self.conv3_1(down2)
x5 = self.relu3_1(x5)
x6 = self.conv3_2(x5)
x6 = self.relu3_2(x6) # 这个后续需要使用
down3 = self.maxpool_3(x6)
x7 = self.conv4_1(down3)
x7 = self.relu4_1(x7)
x8 = self.conv4_2(x7)
x8 = self.relu4_2(x8) # 这个后续需要使用
down4 = self.maxpool_4(x8)
x9 = self.conv5_1(down4)
x9 = self.relu5_1(x9)
x10 = self.conv5_2(x9)
x10 = self.relu5_2(x10)
右边代码
右半部分每一层最开始的数据,由两部分组成,一部分由up-conv 2x2的上采样组成,另外一部风是由左边部分进行复制并进行中心裁剪后得到的,然后对这两部分进行拼接。
右边所有上采样代码
# 接下来实现上采样中的up-conv2*2
self.up_conv_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=2, stride=2, padding=0) # 28*28*1024->56*56*512
self.up_conv_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2, padding=0) # 52*52*512->104*104*256
self.up_conv_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2, padding=0) # 100*100*256->200*200*128
self.up_conv_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2, padding=0) # 196*196*128->392*392*64
右边卷积操作1
self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0) # 56*56*1024->54*54*512
self.relu6_1 = nn.ReLU(inplace=True)
self.conv6_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 54*54*512->52*52*512
self.relu6_2 = nn.ReLU(inplace=True)
右边卷积操作2
self.conv7_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=0) # 104*104*512->102*102*256
self.relu7_1 = nn.ReLU(inplace=True)
self.conv7_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 102*102*256->100*100*256
self.relu7_2 = nn.ReLU(inplace=True)
右边卷积操作3
self.conv8_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=0) # 200*200*256->198*198*128
self.relu8_1 = nn.ReLU(inplace=True)
self.conv8_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 198*198*128->196*196*128
self.relu8_2 = nn.ReLU(inplace=True)
右边卷积操作4
self.conv9_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=0) # 392*392*128->390*390*64
self.relu9_1 = nn.ReLU(inplace=True)
self.conv9_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 390*390*64->388*388*64
self.relu9_2 = nn.ReLU(inplace=True)
最后一个卷积
# 最后的conv1*1
self.conv_10 = nn.Conv2d(in_channels=64, out_channels=2, kernel_size=1, stride=1, padding=0)
copy and crop的实现
# 中心裁剪,
def crop_tensor(self, tensor, target_tensor):
target_size = target_tensor.size()[2]
tensor_size = tensor.size()[2]
delta = tensor_size - target_size
delta = delta // 2
# 如果原始张量的尺寸为10,而delta为2,那么"delta:tensor_size - delta"将截取从索引2到索引8的部分,长度为6,以使得截取后的张量尺寸变为6。
return tensor[:, :, delta:tensor_size - delta, delta:tensor_size - delta]
第一次上采样,裁剪,并实现拼接操作
# 第一次上采样,需要"Copy and crop"(复制并裁剪)
up1 = self.up_conv_1(x10) # 得到56*56*512
# 需要对x8进行裁剪,从中心往外裁剪
crop1 = self.crop_tensor(x8, up1)
# 拼接操作
up_1 = torch.cat([crop1, up1], dim=1)
第二次上采样,裁剪,并实现拼接操作
# 第二次上采样,需要"Copy and crop"(复制并裁剪)
up2 = self.up_conv_2(y2)
# 需要对x6进行裁剪,从中心往外裁剪
crop2 = self.crop_tensor(x6, up2)
# 拼接
up_2 = torch.cat([crop2, up2], dim=1)
第三次上采样,裁剪,并实现拼接操作
# 第三次上采样,需要"Copy and crop"(复制并裁剪)
up3 = self.up_conv_3(y4)
# 需要对x4进行裁剪,从中心往外裁剪
crop3 = self.crop_tensor(x4, up3)
up_3 = torch.cat([crop3, up3], dim=1)
第四次上采样,裁剪,并实现拼接操作
# 第四次上采样,需要"Copy and crop"(复制并裁剪)
up4 = self.up_conv_4(y6)
# 需要对x2进行裁剪,从中心往外裁剪
crop4 = self.crop_tensor(x2, up4)
up_4 = torch.cat([crop4, up4], dim=1)
最终代码
import torch
import torch.nn as nn
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0) # 由572*572*1变成了570*570*64
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 由570*570*64变成了568*568*64
self.relu1_2 = nn.ReLU(inplace=True)
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128
self.relu2_2 = nn.ReLU(inplace=True)
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 280*280*128->140*140*128
self.conv3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0) # 140*140*128->138*138*256
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 138*138*256->136*136*256
self.relu3_2 = nn.ReLU(inplace=True)
self.maxpool_3 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 136*136*256->68*68*256
self.conv4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0) # 68*68*256->66*66*512
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 66*66*512->64*64*512
self.relu4_2 = nn.ReLU(inplace=True)
self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 64*64*512->32*32*512
self.conv5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0) # 32*32*512->30*30*1024
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=0) # 30*30*1024->28*28*1024
self.relu5_2 = nn.ReLU(inplace=True)
# 接下来实现上采样中的up-conv2*2
self.up_conv_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=2, stride=2, padding=0) # 28*28*1024->56*56*512
self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0) # 56*56*1024->54*54*512
self.relu6_1 = nn.ReLU(inplace=True)
self.conv6_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 54*54*512->52*52*512
self.relu6_2 = nn.ReLU(inplace=True)
self.up_conv_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2, padding=0) # 52*52*512->104*104*256
self.conv7_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=0) # 104*104*512->102*102*256
self.relu7_1 = nn.ReLU(inplace=True)
self.conv7_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 102*102*256->100*100*256
self.relu7_2 = nn.ReLU(inplace=True)
self.up_conv_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2, padding=0) # 100*100*256->200*200*128
self.conv8_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=0) # 200*200*256->198*198*128
self.relu8_1 = nn.ReLU(inplace=True)
self.conv8_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 198*198*128->196*196*128
self.relu8_2 = nn.ReLU(inplace=True)
self.up_conv_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2, padding=0) # 196*196*128->392*392*64
self.conv9_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=0) # 392*392*128->390*390*64
self.relu9_1 = nn.ReLU(inplace=True)
self.conv9_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 390*390*64->388*388*64
self.relu9_2 = nn.ReLU(inplace=True)
# 最后的conv1*1
self.conv_10 = nn.Conv2d(in_channels=64, out_channels=2, kernel_size=1, stride=1, padding=0)
# 中心裁剪,
def crop_tensor(self, tensor, target_tensor):
target_size = target_tensor.size()[2]
tensor_size = tensor.size()[2]
delta = tensor_size - target_size
delta = delta // 2
# 如果原始张量的尺寸为10,而delta为2,那么"delta:tensor_size - delta"将截取从索引2到索引8的部分,长度为6,以使得截取后的张量尺寸变为6。
return tensor[:, :, delta:tensor_size - delta, delta:tensor_size - delta]
def forward(self, x):
x1 = self.conv1_1(x)
x1 = self.relu1_1(x1)
x2 = self.conv1_2(x1)
x2 = self.relu1_2(x2) # 这个后续需要使用
down1 = self.maxpool_1(x2)
x3 = self.conv2_1(down1)
x3 = self.relu2_1(x3)
x4 = self.conv2_2(x3)
x4 = self.relu2_2(x4) # 这个后续需要使用
down2 = self.maxpool_2(x4)
x5 = self.conv3_1(down2)
x5 = self.relu3_1(x5)
x6 = self.conv3_2(x5)
x6 = self.relu3_2(x6) # 这个后续需要使用
down3 = self.maxpool_3(x6)
x7 = self.conv4_1(down3)
x7 = self.relu4_1(x7)
x8 = self.conv4_2(x7)
x8 = self.relu4_2(x8) # 这个后续需要使用
down4 = self.maxpool_4(x8)
x9 = self.conv5_1(down4)
x9 = self.relu5_1(x9)
x10 = self.conv5_2(x9)
x10 = self.relu5_2(x10)
# 第一次上采样,需要"Copy and crop"(复制并裁剪)
up1 = self.up_conv_1(x10) # 得到56*56*512
# 需要对x8进行裁剪,从中心往外裁剪
crop1 = self.crop_tensor(x8, up1)
up_1 = torch.cat([crop1, up1], dim=1)
y1 = self.conv6_1(up_1)
y1 = self.relu6_1(y1)
y2 = self.conv6_2(y1)
y2 = self.relu6_2(y2)
# 第二次上采样,需要"Copy and crop"(复制并裁剪)
up2 = self.up_conv_2(y2)
# 需要对x6进行裁剪,从中心往外裁剪
crop2 = self.crop_tensor(x6, up2)
up_2 = torch.cat([crop2, up2], dim=1)
y3 = self.conv7_1(up_2)
y3 = self.relu7_1(y3)
y4 = self.conv7_2(y3)
y4 = self.relu7_2(y4)
# 第三次上采样,需要"Copy and crop"(复制并裁剪)
up3 = self.up_conv_3(y4)
# 需要对x4进行裁剪,从中心往外裁剪
crop3 = self.crop_tensor(x4, up3)
up_3 = torch.cat([crop3, up3], dim=1)
y5 = self.conv8_1(up_3)
y5 = self.relu8_1(y5)
y6 = self.conv8_2(y5)
y6 = self.relu8_2(y6)
# 第四次上采样,需要"Copy and crop"(复制并裁剪)
up4 = self.up_conv_4(y6)
# 需要对x2进行裁剪,从中心往外裁剪
crop4 = self.crop_tensor(x2, up4)
up_4 = torch.cat([crop4, up4], dim=1)
y7 = self.conv9_1(up_4)
y7 = self.relu9_1(y7)
y8 = self.conv9_2(y7)
y8 = self.relu9_2(y8)
# 最后的conv1*1
out = self.conv_10(y8)
return out
if __name__ == '__main__':
input_data = torch.randn([1, 1, 572, 572])
unet = Unet()
output = unet(input_data)
print(output.shape)
# torch.Size([1, 2, 388, 388])
这个结构是先对图片进行卷积和池化,在Unet论文中是池化4次,比方说一开始图片是224 \(\times\) 224,那么会变成112 \(\times\) 112,56 \(\times\) 56, 14$ \times$ 14四个不同尺寸的特征。然后我们对14$\times$14的特征图做上采样或反卷积,得到28 \(\times\) 28的特征图。这个28 \(\times\) 28的特征图进行通道上的拼接concat,然后再对拼接之后的特征图做卷积和上采样,得到56 \(\times\) 56的特征图,再与之前的56 \(\times\) 56的特征拼接,卷积,再上采样,经过四次上采样可以得到一个与输入图像尺寸相同的224 \(\times\) 224的预测结果。
其实整体来看,这个也是一个Encoder-Decoder的结构:
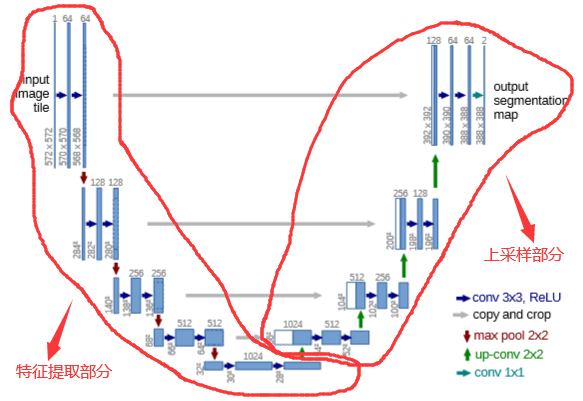
Unet网络非常的简单,前半部分就是特征提取,后半部分是上采样,由于网络的整体结构是一个大写的英文字母U,所以叫做U-net。
- Encoder:左半部分,由两个3 \(\times\) 3的卷积层(RELU)再加上2 \(\times\) 2的maxpooling层组成一个下采样的模块(见代码)。
- Dncoder:右半部分,由一个上采样的卷积层 + 特征拼接concat + 两个3 \(\times\) 3的卷积层(RELU)反复构成(见代码)。
在当时,Unet相比更早提出的FCN网络,使用拼接来作为特征图的融合方式。
- FCN是通过特征图对应像素值的相加来融合特征的。
- U-NET通过通道数的拼接,这样可以形成更厚的特征,当然这样会更加消耗显存。
Unet的好处我感觉是:网络层越深得到的特征图,有着更大的视野域,浅层卷积关注纹理特征,深层网络关注本质的那种特征,所以深层浅层特征都是有各自的意义的;另外一点事通过反卷积得到的更大尺寸特征图的边缘,是缺少信息的,毕竟每一次下采样提炼特征的同时,也必然会损失一些边缘特征,而失去的特征并不能从上采样中找回,因此通过特征的拼接,来实现边缘特征的找回。
参考博客:
https://www.cnblogs.com/PythonLearner/p/14041874.html
https://blog.csdn.net/knighthood2001/article/details/138075554

 浙公网安备 33010602011771号
浙公网安备 33010602011771号