【图解数据结构】树及树的遍历
当你第一次学习编码时,大部分人都是将数组作为主要数据结构来学习。
之后,你将会学习到哈希表。如果你是计算机专业的,你肯定需要选修一门数据结构的课程。上课时,你又会学习到链表,队列和栈等数据结构。这些都被统称为线性的数据结构,因为它们在逻辑上都有起点和终点。
当你开始学习树和图的数据结构时,你会觉得它是如此的混乱。因为它的存储方式不是线性的,它们都有自己特定的方式存储数据。
定义
树是众所周知的非线性数据结构。它们不以线性方式存储数据。他们按层次组织数据。
树的定义
树(Tree)是n(n>=0)个结点的有限集。n=0时称为空树。
在任意一颗非空树中:
(1)有且仅有一个特定的称为根(Root)的结点。
(2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1、T2、.....、Tm,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
下图就符合树的定义:

其中根结点A有两个子树:
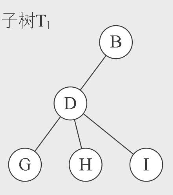
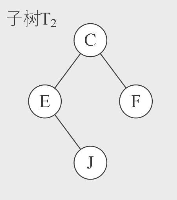
我们硬盘的文件系统就是很经典的树形结构。
“树”它具有以下的特点:
①每个节点有零个或多个子节点;
②没有父节点的节点称为根节点;
③每一个非根节点有且只有一个父节点;
④除了根节点外,每个子节点可以分为多个不相交的子树;
树(
tree)是被称为结点(node)的实体的集合。结点通过边(edge)连接。每个结点都包含值或数据(value/date),并且每结节点可能有也可能没有子结点。树的首结点叫根结点(即
root结点)。如果这个根结点和其他结点所连接,那么根结点是父结点与根结点连接的是子结点。所有的结点都通过边连接。它是树中很重要得一个概念,因为它负责管理节点之间的关系。
叶子结点是树末端,它们没有子结点。像真正的大树一样,我们可以看到树上有根、枝干和树叶。
术语汇总
-
根结点是树最顶层结点
-
边是两个结点之间的连接
-
子结点是具有父结点的结点
-
父结点是与子结点有连接的结点
-
叶子结点是树中没有子结点的结点(树得末端)
-
高度是树到叶子结点(树得末端)的长度
-
深度是结点到根结点的长度
树的结点
树的结点包含一个数据元素及若干指向其子树的分支。
结点拥有的子树数称为结点的度(Degree)。
树的度是树内各结点度的最大值。

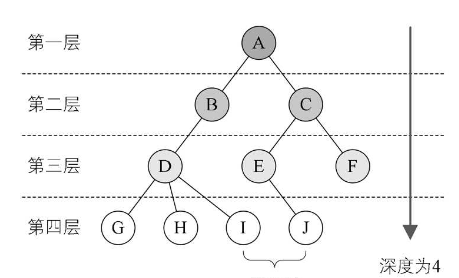
结点的层次从根开始定义起,根为第一层,根的孩子为第二层,以此类推,若某结点在第 i 层,则其子树的根就在第 i+1 层。
其双亲在同一层的结点互为堂兄弟。显然下图中的D、E、F是堂兄弟,而G、H、l、J也是。
树的深度(Depth)或高度是树中结点的最大层次。
树的高度( height)和深度( depth)
-
树的高度是到叶子结点(树末端)的长度,也就是根结点到叶子结点的最大边长度
-
结点的深度是它到根结点的长度,也就是层次
树的存储结构
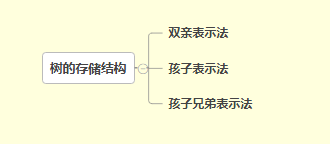
双亲表示法
在每个结点中,附设一个指示器指示其双亲结点到链表中的位置。


优点:parent指针域指向数组下标,所以找双亲结点的时间复杂度为O(1),向上一直找到根节点也快缺点:由上向下找就十分慢,若要找结点的孩子或者兄弟,要遍历整个树
孩子表示法
![]()
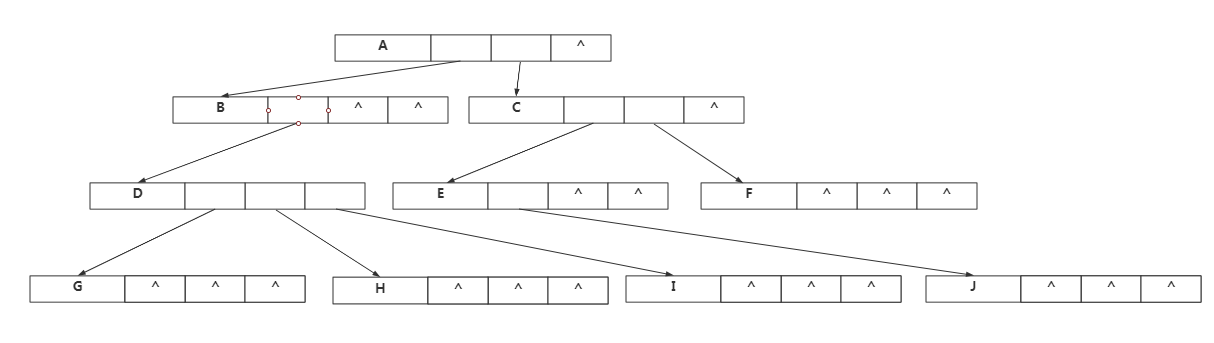
优点:找孩子比较容易
缺点:占用了大量不必要的孩子域空指针。 若要找结点的父亲,要遍历整个树。
改进一:为每个结点添加一个结点度域,方便控制指针域的个数
![]()
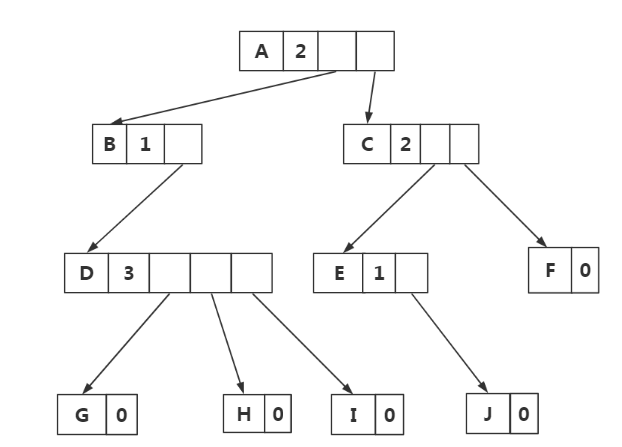
缺点:维护困难,不易实现
改进二:结合顺序结构和链式结构
把所有结点先放在数组里面,每个结点都会有自己的子结点,第一个孩子就用一个指针表示,每个孩子的next指针指向它的兄弟
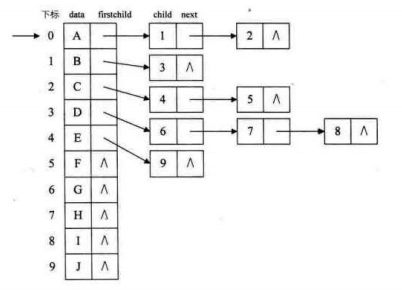
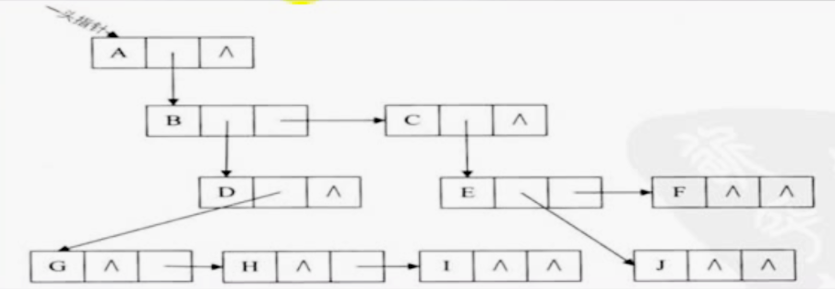
孩子兄弟表示法
任意一棵树,它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。因此,我们设置两个指针 ,分别指向该结点的第一个孩子和此结点的右兄弟

二叉树
二叉树的定义
二叉树(Binary Tree)是n(n>=0)个结点的有限集合,该集合或者为空集(空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树的二叉树组成(子树也为二叉树)。
二叉树的特点
- 每个结点最多有两棵子树,所以二叉树中不存在度大于2的结点。
- 左子树和右子树是有顺序的,次序不能任意颠倒。
- 即使树中某结点只有一棵子树,也要区分它是左子树还是右子树。
二叉树五种基本形态
1、空二叉树
2、只有一个根结点
3、根结点只有左子树
4、根结点只有右子树
5、根结点既有左子树又有右子树
几种特殊的二叉树
斜树

左斜树: 右斜树:
右斜树: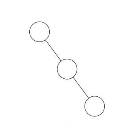
满二叉树

满二叉树: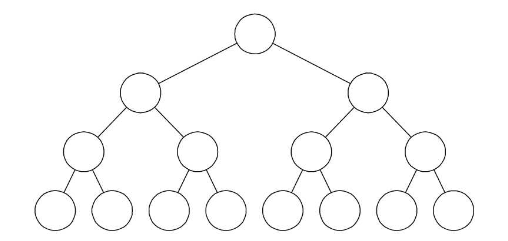
完全二叉树
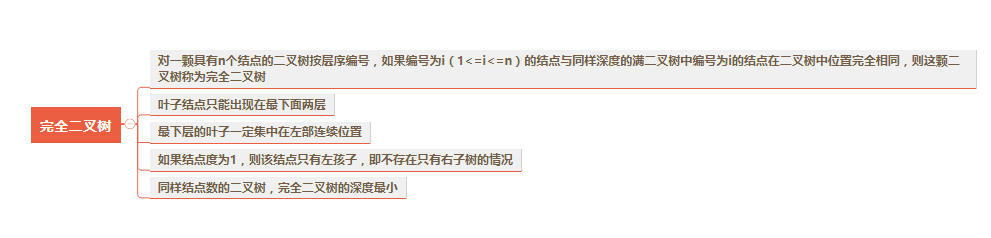
完全二叉树: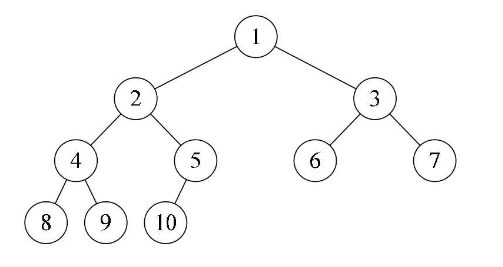
二叉树的性质
二叉树性质1
性质1:在二叉树的第i层上至多有2i-1个结点(i>=1)
二叉树性质2
性质2:深度为k的二叉树至多有2k-1个结点(k>=1)
N=2K-1 K是层次/高度(4) N=15
二叉树性质3
性质3:对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0 = n2+1。
一棵二叉树,除了终端结点(叶子结点),就是度为1或2的结点。假设n1度为1的结点数,则数T 的结点总数n=n0+n1+n2。我们再换个角度,看一下树T的连接线数,由于根结点只有分支出去,没有分支进入,所以连接线数为结点总数减去1。也就是n-1=n1+2n2,可推导出n0+n1+n2-1 = n1+2n2,继续推导可得n0 = n2+1。
二叉树性质4
性质4:具有n个结点的完全二叉树的深度为[log2n +1] ([X]表示不大于X的最大整数)。
2K=N+1 N是结点数(15)
K=log2n+1 < log2n+1
由性质2可知,满二叉树的结点个数为2k-1,可以推导出满二叉树的深度为k=log2(n + 1)。对于完全二叉树,它的叶子结点只会出现在最下面的两层,所以它的结点数一定少于等于同样深度的满二叉树的结点数2k-1,但是一定多于2k-1 -1。因为n是整数,所以2k-1 <= n < 2k,不等式两边取对数得到:k-1 <= log2n <k。因为k作为深度也是整数,因此 k= [log2n ]+ 1。
二叉树性质5
性质5:如果对一颗有n个结点的完全二叉树(其深度为 [ log2n+1 ] )的结点按层序编号(从第1层到第 [log2n+1] 层,每层从左到右),对任一结点 i (1<=i<=n) 有:
如果i=1,则结点i是二叉树的根,无双亲;如果 i>1,则其双亲是结点 [ i / 2 ]。 双亲结点的编号 = 两个子结点中的一个子结点 / 2
- 如果2i>n,则结点i无左孩子(结点i为叶子结点);否则其左孩子是结点2i
如果2i+1>n,则结点 i 无右孩子;否则其右孩子是结点2i+1
结合下图很好理解:
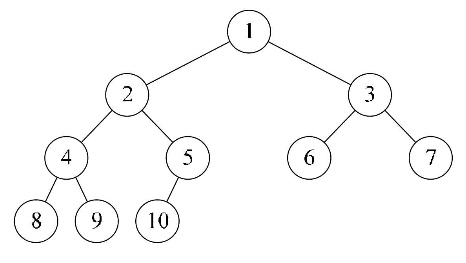
二叉树的存储结构
二叉树顺序存储结构
一般二叉树: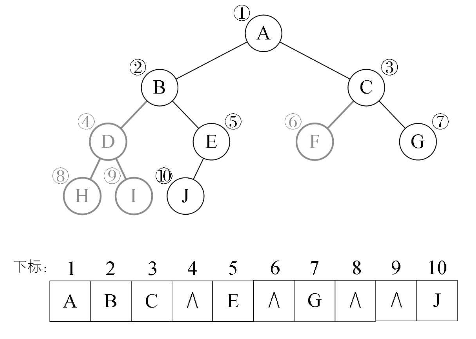
^ 代表不存在的结点。
二叉链表
链表每个结点包含一个数据域和两个指针域:

其中data是数据域,lchild和rchild都是指针域,分别指向左孩子和右孩子。

二叉树的遍历
深度优先搜索(Depth-First Search,DFS)
DFS 在回溯和搜索其他路径之前找到一条到叶节点的路径。让我们看看这种类型的遍历的示例。
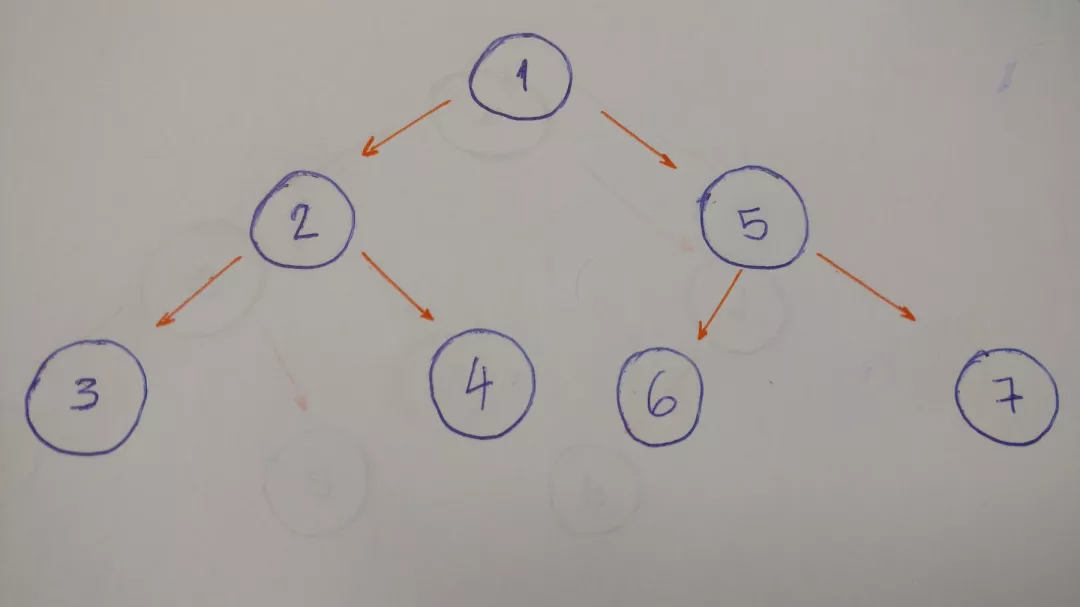
输出结果为: 1–2–3–4–5–6–7
为什么?
让我们分解一下:
-
从根结点(1)开始。输出
-
进入左结点(2)。输出
-
然后进入左孩子(3)。输出
-
回溯,并进入右孩子(4)。输出
-
回溯到根结点,然后进入其右孩子(5)。输出
-
进入左孩子(6)。输出
-
回溯,并进入右孩子(7)。输出
-
完成
当我们深入到叶结点时回溯,这就被称为 DFS 算法。
既然我们对这种遍历算法已经熟悉了,我们将讨论下 DFS 的类型:前序、中序和后序。
前序遍历
这和我们在上述示例中的作法基本类似。
-
输出节点的值
-
进入其左结点并输出。当且仅当它拥有左结点。
-
进入右结点并输出之。当且仅当它拥有右结点
代码实现 -- 迭代实现
/**
* 前序遍历--迭代
*/
public void preOrder(TreeNode node) {
if (node == null) {
return;
} else {
System.out.println("preOrder data:" + node.getData());
preOrder(node.leftChild);
preOrder(node.rigthChild);
}
}
前序遍历 - -栈实现
/**
* 前序遍历--栈
*
* @param node
*/
public void nonRecOrder(TreeNode node) {
if (root == null) {
return;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(node);
while (!stack.isEmpty()) {
//出栈和进栈
TreeNode n = stack.pop();//弹出根节点
//压入子结点
System.out.println("nonRecOrder data: " + n.getData());
//避免叶子结点为空,出现空指针异常
if (n.rigthChild != null) {
stack.push(n.rigthChild);
}
if (n.leftChild != null) {
stack.push(n.leftChild);
}
}
}
中序遍历
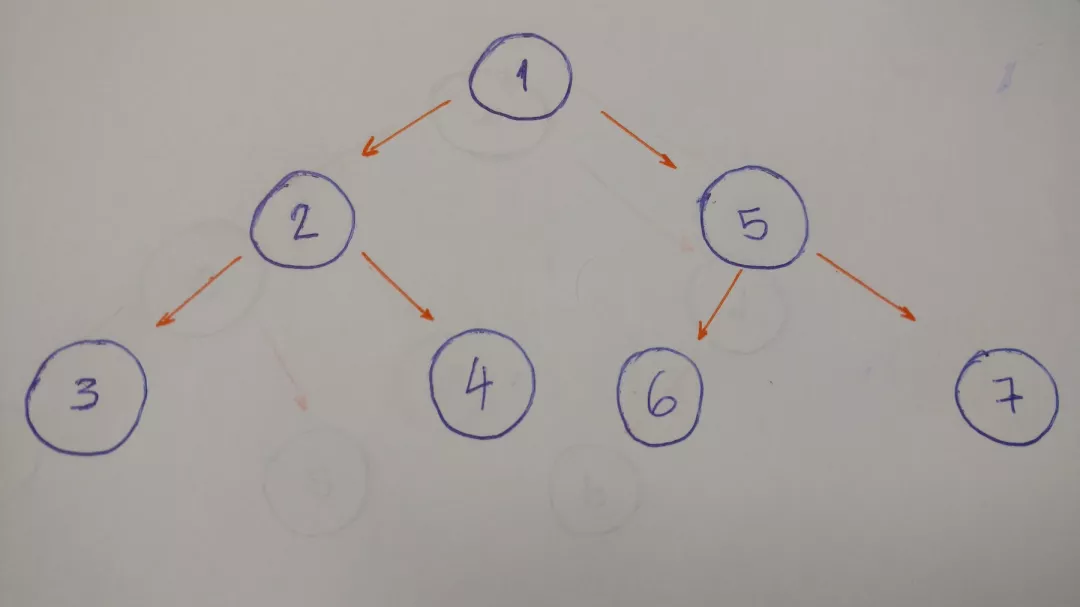
示例中此树的中序算法的结果是3–2–4–1–6–5–7。
左结点优先,之后是中间,最后是右结点。
代码实现:
/**
* 中序遍历--迭代
*/
public void midOrder(TreeNode node) {
if (node == null) {
return;
} else {
midOrder(node.leftChild);
System.out.println("midOrder data:" + node.getData());
midOrder(node.rigthChild);
}
}
后序遍历

以此树为例的后序算法的结果为 3–4–2–6–7–5–1 。
左结点优先,之后是右结点,根结点的最后。
代码实现:
/**
* 后序遍历--迭代
*/
public void
postOrder(TreeNode node) {
if (node == null) {
return;
} else {
postOrder(node.leftChild);
postOrder(node.rigthChild);
System.out.println("postOrder data:" + node.getData());
}
}
自创遍历小技巧(附链接)
先根遍历法(超级简单小技巧)
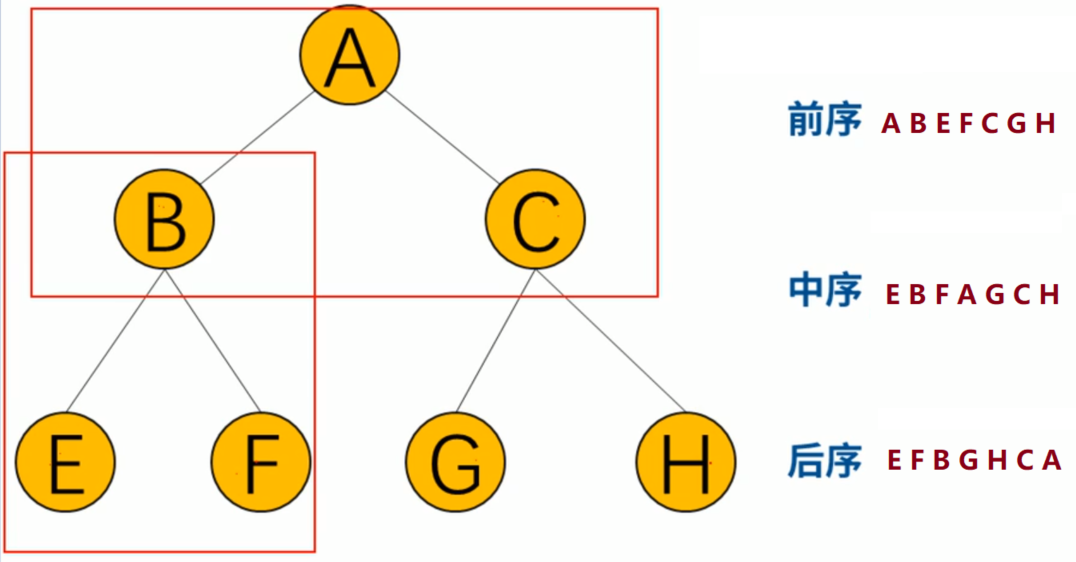
三角形遍历法
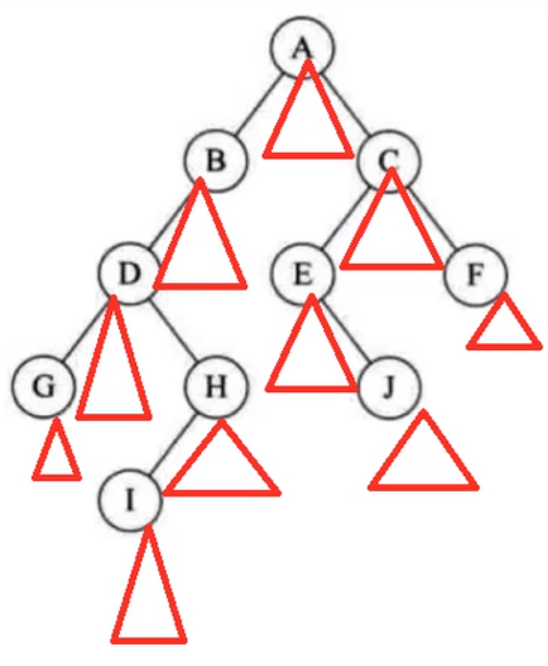 结果: G D I H B A E J C F
结果: G D I H B A E J C F
例子:

上图二叉树遍历结果
前序遍历:ABCDEFGHK
中序遍历:BDCAEHGKF
后序遍历:DCBHKGFEA

