LInkHashMap源码分析
说LinkHashMap之前,我们先来谈谈什么是LRU算法?
按照英文的直接原义就是Least Recently Used,最近最久未使用法,它是按照一个非常注明的计算机操作系统基础理论得来的:最近使用的页面数据会在未来一段时期内仍然被使用,已经很久没有使用的页面很有可能在未来较长的一段时间内仍然不会被使用。基于这个思想,会存在一种缓存淘汰机制,每次从内存中找到最久未使用的数据然后置换出来,从而存入新的数据!它的主要衡量指标是使用的时间,附加指标是使用的次数。在计算机中大量使用了这个机制,它的合理性在于优先筛选热点数据,所谓热点数据,就是最近最多使用的数据!因为,利用LRU我们可以解决很多实际开发中的问题,并且很符合业务场景。
双向循环链表
public class LinkedHashMap<K,V>extends HashMap<K,V>{
transient LinkedEntry<k,V> header; //头结点
private final boolean accessOrder; //true:访问排序 false:插入排序
public LinkedHashMap(){
init();
accessOrder=false; //默认情况为false,基于插入排序的
}
static class LinkedEntrykK,V> extends HashMapEntry<K, V> //linkedEntry继承了HashMapEntry,也就拥有了父类的所有属性和方法
{
LinkedEntry<K, V> nxt;
LinkedEntry<K, V> prv;
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<k, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
linkedHashMap只是重写了hashMap put方法里的addNewEntry增加新元素方法
header:头结点
eldest:最先进来的结点(最老的)
oldTail:
newTail:新添加的结点
table[index]:一维数组,把新的尾巴加入到table[index]里面来
@Override
void addNewEntry(K key, V value, int hash, int index) {
LinkedEntry<K, V> header = this.header;
LinkedEntry<K, V> eldest = header.nxt;
if (eldest != header && removeEldestEntry(eldest)) {如果头结点不是自己抱自己
remove(eldest.key);
}
LinkedEntry<K, V> oldTail = header.prv;
//添加一个新元素
LinkedEntry<K, V> newTail = new LinkedEntry<K, V>(
key, value, hash, table[index], header(next), oldTail(previous)); //做构造函数时newTail.next指向header
①table[index] = ②oldTail.nxt = ③header.prv = ④newTail; 4=3 4=2 2=1
}
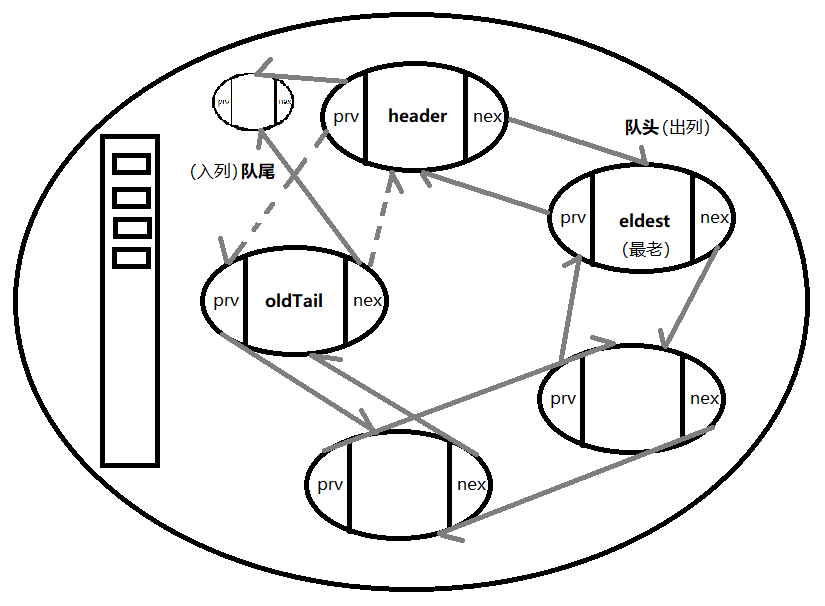 因为新加进来的元素是在队尾插入的,不断插入元素的话就不断移动,如果eldest没有用了,将来就用removeEldestEntry方法移除
因为新加进来的元素是在队尾插入的,不断插入元素的话就不断移动,如果eldest没有用了,将来就用removeEldestEntry方法移除
//默认构造方法,头结点自己指向自己,也就是自己抱自己
@Override void init(){
header]=new uinkedEntry<K,V>();
LinkedEntry(){
super(nu11,nul1,0,null); nxt = prv = this;
隐藏了一列一维数组,将来还是有用的
默认return false;不会移除 方法的作用:是在内存过高时,移除最老的元素,所以需要重写这个方法,return true;
protected boolean removeEldestEntry(Map. Entry<k,V>eldest){ return false;
}
访问
如果要访问 包含头结点顺时针第四个元素,让它成为最新的,就需要把第五个和第三个结点连起来,再在队尾用addNewEntry方法添加一个newTail
e:访问到的元素
@Override
public V get(Object key) {
if (key == null) {
HashMapEntry<k, V> e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTai1((LinkedEntry<K, V>) e);
return e.value;
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<k, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKeyI = e.key;
if (ekey == key Il(e.hash == hash && key.equals(ekey))){ //如果找到了这个元素
if (accessOrder)
makeTail((LinkedEntry<K, V>) e); //将访问到的元素当做尾巴反正队尾添加进来
return e.value;
}
}
return null;
}
private void makeTail(LinkedEntry<k, V> e) {
e.prv.nxt = e.nxt; //e.prv(a).nxt=e.nxt(oldTail)
e.nxt.prv = e.prv;
LinkedEntry<K, V> header = this.header;
LinkedEntryf, V > oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
o1dTail.nxt = header.prv = e;
modCount++;
}
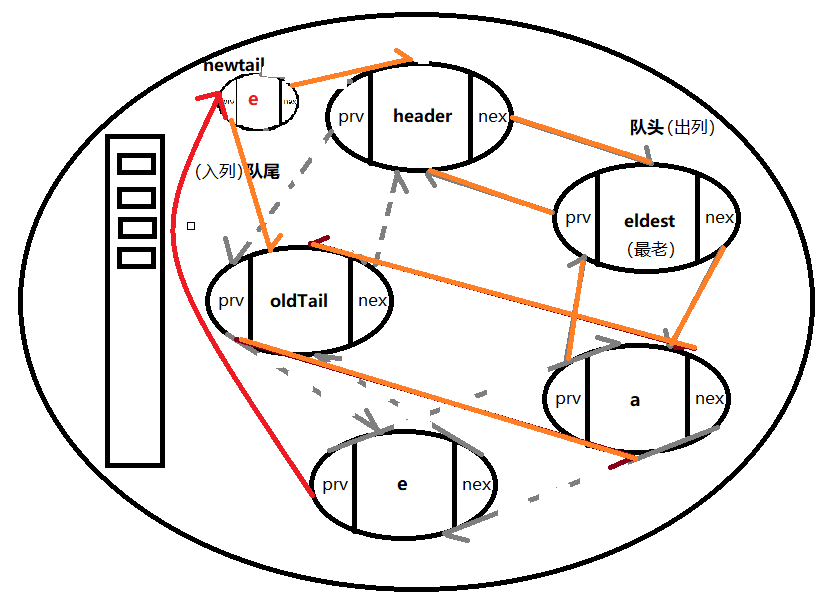
新进来的要放在队头
最后进来的是最新的
顺序存储,谁先存进来的,谁先被移出去。
访问排序,谁最近被访问就是最活跃的,最后才被移出去

