
[计算机视觉]从零开始构建一个微软how-old.net服务/面部属性识别
大概两三年前微软发布了一个基于Cognitive Service API的how-old.net网站,用户可以上传一张包含人脸的照片,后台通过调用深度学习算法可以预测照片中的人脸、年龄以及性别,然后将结果绘制到原图片上返回给用户。那时候深度学习技术在国内刚流行不久(2016年前后),当时这个网站一度引起IT/非IT界的关注。现在已经过去三四年了,深度学习技术在国内互联网‘日渐普及’,大家也见怪不怪。本篇文章从零开始,教大家实现一个类似how-old.net的服务,即通过一张包含了人脸的照片,预测年龄、性别以及种族。

熟悉英文的同学可以直接移步github源码阅读README文件。

任务目标
我们的目标很简单,构建一个神经网络,或者基于已有比较流行的网络结构进行改造,通过素材数据训练后,我们的网络能够预测照片中每张人脸的年龄、性别以及种族。最后将结果绘制显示在原图片中。我们主要目标是完成神经网络的训练以及推理和结果显示,至于完整实现how-old.net需要考虑的那种Web get/post restful API请求暂不需要考虑了,毕竟不是本文重点。
工具准备
训练神经网络或者做深度学习相关的工作,我们最好有一台带有GPU的电脑,一般都是Ubuntu系统,但是我这篇文章的代码是在自己办公PC上开发调试的,有些开源项目并不官方支持Windows10系统,因为这个系统坑比较多,建议大家平时调试还是优先使用Ubuntu。
-
Windows 10
-
Python 3.5
-
tensorflow-gpu 2.1
-
dib/face_recognition (demo中检测人脸)
-
OpenCV3.4
-
scipy、numpy、h5py、pillow
-
Cuda 10.0
-
Cudnn 7.5
-
CPU i7-7700K 4.2GHz
-
GPU GTX 1080
-
16G RAM
我这个硬件配置相对来讲算是比较高了,差点的机器也能跑,可能训练慢点,推理也慢点。
实现原理
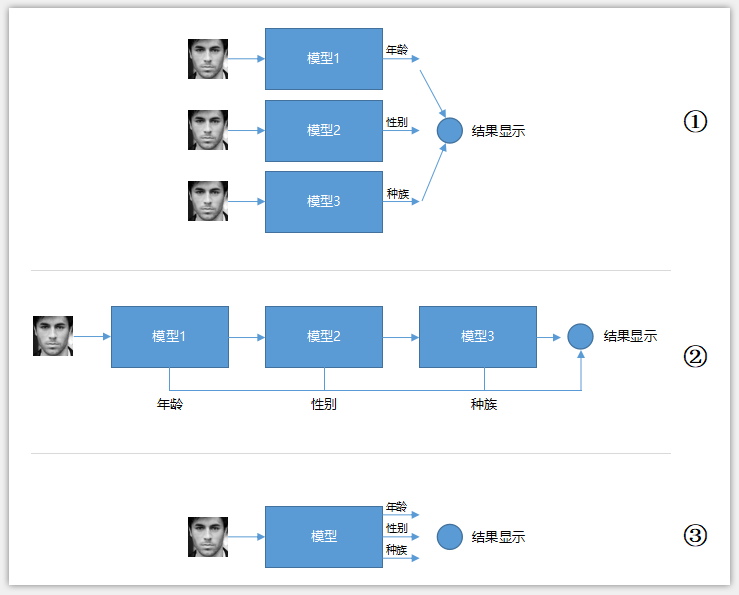
如果对深度学习有一点了解,那么解决本次问题的原理其实相当明了。这是一个典型的分类问题(分类和回归的区别请参见这里:https://www.cnblogs.com/xiaozhi_5638/p/11792274.html),我们可以定义三个单独的网络分别去预测年龄、性别以及种族,也可以只定义一个网络(包含三个输出)同时预测年龄、性别以及种族,前者训练相对来讲简单、网络更容易拟合,但是网络训练完之后实际上线推理速度相对要慢,因为需要推理三次(下图中间),或者并行推理(最上面,需要同时占用硬件资源),而后者训练麻烦,收敛效果可能没有前者好,但是一旦训练完成后,后面推理速度较快,一次推理出三种结果(下图最下面)。我们本次采用后面那种方式,即定义一个网络,能够同时推理出年龄、性别以及种族。
神经网络的训练有两种方式,一种从零开始,网络的权重随机初始化,之后权重调整全靠你自己的数据集;另外一种方式就是在别人已经训练好的权重基础上再去调整,以到达解决我们自己任务的目的,这种方式的好处就是网络的权重不再是随机初始化了,而是初始化为一些比较靠谱的值,我们再在这些靠谱的值基础上进行调整,这种方式肯定比随机初始化要好。除非你的数据集相当庞大并且丰富,否则神经网络的训练一般都是采用使用第二种方式。第二种方式也叫“迁移学习”,类似将别人学习好了的经验拿过来用,这样当然要比从零开始学习更容易。迁移学习的关键点是要能找到合适的、跟我们任务类似的、别人训练好的权重,这句话比较拗口,简单来讲就是,你借鉴的经验必须是有效的,别人10年钓鱼的经验对于你去考驾照来讲是无效的,同样的,你不能借鉴别人10年开车的经验来学习Python编程。那么什么经验是有效的呢?举几个例子,你可以借鉴别人10年开车的经验去学习叉车操控,你也可以借鉴别人学Java编程的经验去学习Python编程。对深度学习来讲,如果别人已经训练好了一个网络,该网络可以做1000个人的人脸分类,那么你可以‘借用’这个网络的权重去做另外100个人的人脸分类(这100不在1000之内),因为这两个任务有相似性。如果别人已经训练好了一个网络,该网络可以用来为艺术系学生的水彩画作业打分,那么你不可以(或者很难)‘借用’这个网络的权重去为艺术系学生的素描画作业打分,因为水彩画和素描画相关性不是很大。当然,这里的能不能借用并不是绝对的,只是能借用程度的多少不一。在实际迁移学习训练过程中,我们可以通过‘冻结’部分网络层的权重,让其不参与我们自己数据集的训练,保持初始值不变,那么这些冻结层的权重就是我们前面说的到‘借用’了,冻结哪些层可以随机调整,代表我们借用的程度。关于迁移学习更具体的数学描述请参考这篇文章:https://www.cnblogs.com/xiaozhi_5638/p/12202074.html
实现过程
解决本次任务时,我们借用牛津大学著名的VGGFace网络结构和其权重,该网络主要用来对2622(VGGFace V1)以及8631(VGGFace V2)个人脸进行分类,网络结构和预训练的权重在网络上均可以下载。我们的任务目标是对人脸的年龄、性别以及种族进行预测,任务类型和VGGFace差不多,都跟人脸有关,所以迁移学习在这里完全可以使用。具体做法为:
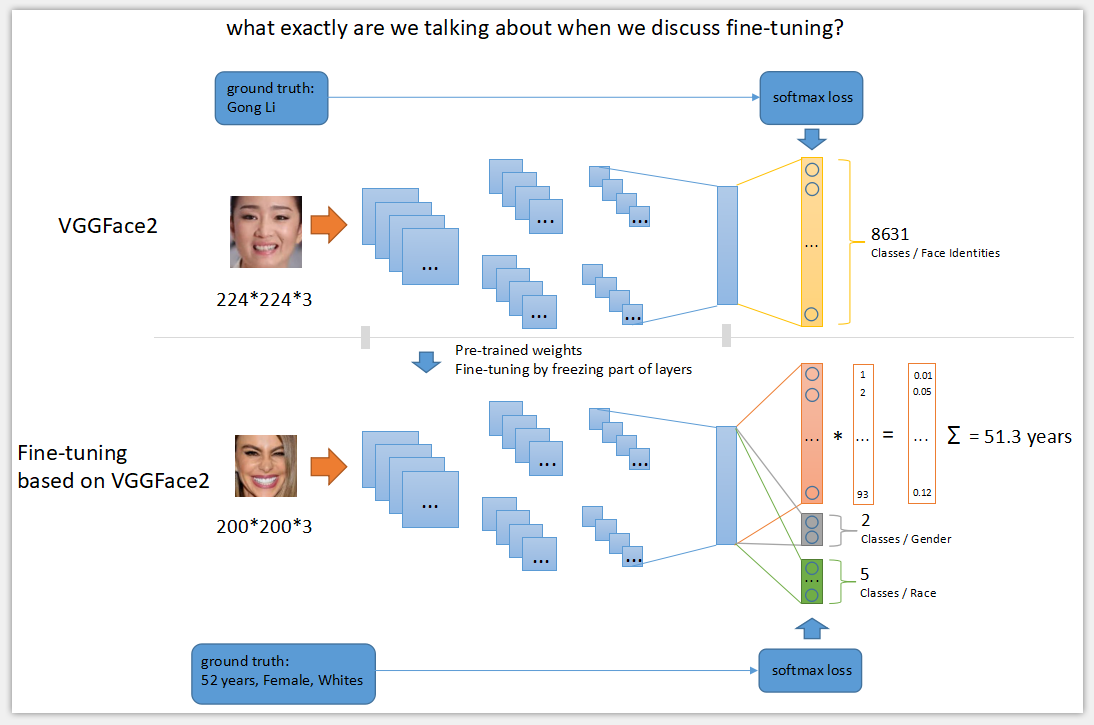
(1)去掉原VGGFace V2顶部的分类全连接层(MLP层),该层主要对前面提取的人脸特征进行8631分类;
(2)再在(1)的基础上接上3个输出分支,每个分支都是做分类任务,分别负责年龄、性别以及种族的预测;
(3)修改原VGGFace V2的输入尺寸,由原来的(224, 224, 3)改为(200, 200, 3),主要原因是我们自己的训练数据集UTKFace的原始尺寸是200*200,当然你也可以保持不变,训练时将图像缩放;
(4)冻结VGGFace V2网络结构的全部层(不包括我们接上去的3个分支),这个意思是借用VGGFace V2的全部经验,权重保持不变;
(5)开始使用UTKFace数据集进行训练;
(6)观察loss的变化效果,如果发现效果不理想,可以适当回到(4)步,将冻结层数减少,这个意思是借用部分VGGFace V2的经验;
当然了,网络的训练远没有上面写的这么简单,需要不断去尝试,修改各种超参数、甚至调整VGGFace V2本身网络结构(部分权重忽略)。
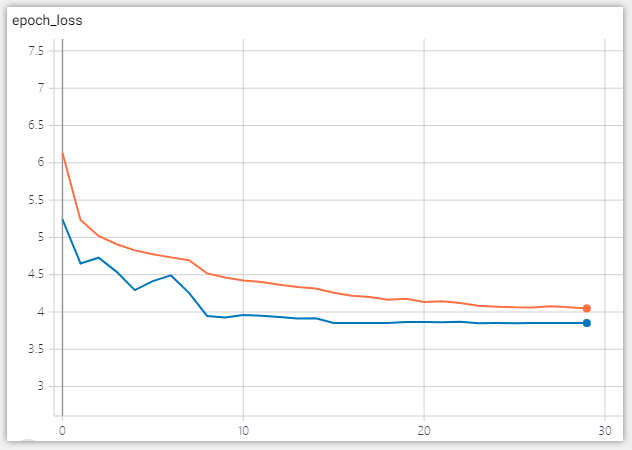
这里再说一下,为什么年龄预测是一个分类问题而不是回归问题?其实有一篇论文对这个有介绍:https://www.cv-foundation.org/openaccess/content_iccv_2015_workshops/w11/papers/Rothe_DEX_Deep_EXpectation_ICCV_2015_paper.pdf 这个论文用实验结果告诉我们分类比回归的效果要好。下面是使用UTKFace数据集进行训练的结果,图中蓝色线为val_loss,图中橙色线条为train_loss,由于训练过程中使用了数据增强,train_loss比val_loss要高一点,属于正常现象:
源码介绍
face.py
定义我们自己的神经网络结构,输入尺寸,冻结层数等等,可以根据需要自己调整。
face_train.py
使用UTKFace数据集训练我们的神经网络,你可以修改代码来适配其他数据集。
face_demo.py
单张图demo
face_video_demo.py
视频文件demo,或者usb 摄像头demo
face_weights/
训练过程中,ModelCheckPoint产生的权重文件,demo可以通过model.load_weights()加载使用。
train_data/
存放训练数据。
vggface_weights/
原VGGFace V2预训练的权重文件,我们在训练的时候需要先加载该权重,然后再在基础上进行微调。注意我使用的是ResNet50的结构,VGGFaceV2内部还支持SeNet50的网络结构。
使用不同的网络结构需要使用不同的预训练权重。
logs/
Tensorboard产生的日志文件,用于对训练进度的监控。
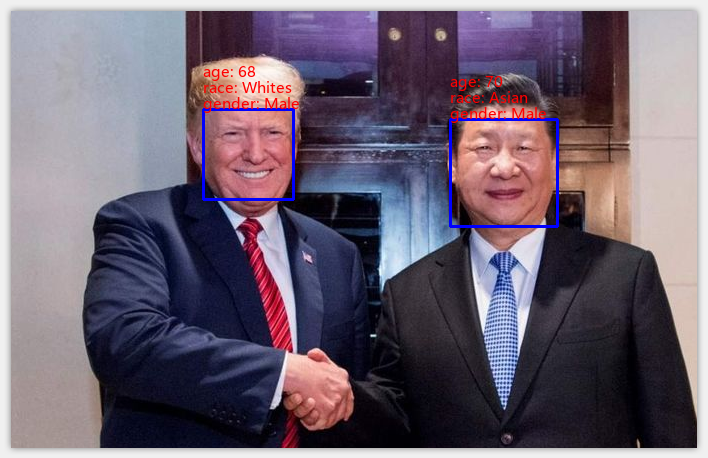
多说无益,直接看源码更易懂,更多细节请关注公众号。建国同志和大大镇楼。
参考
websites
- VGGFace Dataset used for pre-trained weights (VGGFace V1)
- VGGFace2 Dataset used for pre-trained weights (VGGFace V2)
- UTKFace Dataset used for fine-tuning in this repo
- related paper1 why age estimation is a classification task?
- related paper2 about VGGFace dataset
- related paper3 about VGGFace2 dataset
- related paper4 triplet loss in face recognition
历史文章
[计算机视觉]人脸应用:人脸检测、人脸对比、五官检测、眨眼检测、活体检测、疲劳检测
[AI开发]小型数据集解决实际工程问题——交通拥堵、交通事故实时告警
关注公众号,及时关注文章动态

 浙公网安备 33010602011771号
浙公网安备 33010602011771号