LiteDB源码解析系列(4)跳表基本原理
LitDB里面索引的数据结构是用跳表来实现的,我知道的开源项目中使用跳表的还包括Redis,大家可以上网搜索关于Redis的跳表功能的实现。在这一章,我将结合LiteDB中的示例来讲解跳表。
1.跳表与其他数据结构对比
我们经常能够听说B树,红黑树,AVL树,Splay Tree, Treep,但是让我们打开编辑器自己去实现,可能要考虑好很多细节。使用跳表就很简单了,它是一种随机化的数据结构,效率和红黑树及AVL树不相上下,同时它的原理不复杂,只要能看懂链表操作,就能轻松的实现跳表。
1.1 跳表的搜索
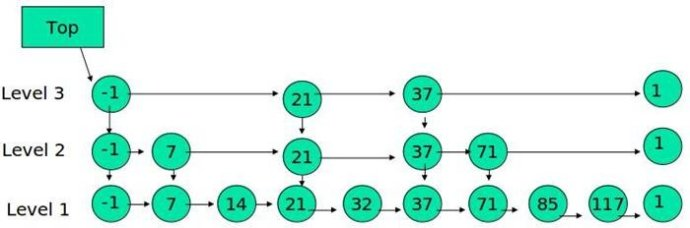
跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
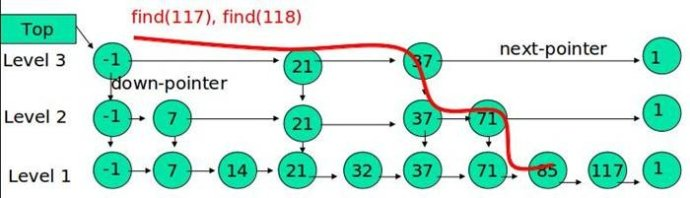
例子:查找元素 117
(1) 比较 21, 比 21 大,往后面找
(2) 比较 37, 比 37大,比链表最大值小,从 37 的下面一层开始找
(3) 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,从后面找
(5) 比较 117, 等于 117, 找到了节点。
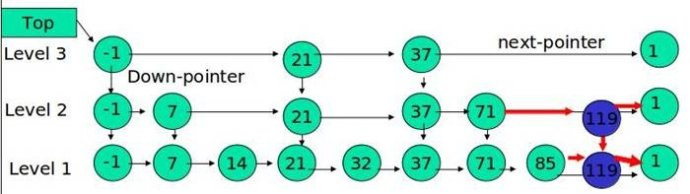
1.2 跳表的插入
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的)然后在 Level 1 ... Level K 各个层的链表都插入元素。
例子:插入 119, K = 2
1.3 跳表的空间复杂度分析
根据上面的分析,每个元素的期望高度为 2, 一个大小为 n 的跳表,其节点数目的期望值是 2n。
2.LiteDB索引跳表插入的可视化动画
根据上面的图文,我们大致可以看出跳表的查询和插入还是比较简单易懂的,下面我还是用可视化的方式展示LiteDB如何插入一条记录,下面的动画里插入的表还是名为"customer"的表,字段为{“Id”,"Age","Name"},目前已经有了10条随机记录,下面的界面是插入第11条记录时,字段为“Age”的索引变化,在下面可视化工具里面可以清楚的看出插入索引时候,查找轨迹的走向:

3.LiteDB索引跳表查找的可视化动画
在上面的数据中我查找Age为9的数据,现在大家可以看到仔细看它索引查询的步骤是先上后下,先左后右的顺序,这就是跳表的精髓所在(点击图片可以放大):

4.结语
关于LiteDB的解析大概就讲到这里,我看这个源码的大致过程就是用vs把类图显示出来,对照类图看各个模块功能,对于索引的添加和查找,就只能想办法将其可视化。LiteDB最新版添加了很好用的功能,后面的项目如果用到,可能还会回来更新一下使用上的细节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号