Elasticsearch、分词器、kibana的linux安装和使用
安装包提供 https://pan.baidu.com/s/1qeRSkws2e1RKoRAWg7zUXw 提取码 p8ne
由于es出于安全考虑,不可以用root用户操作es。
如果使用root用户操作和启动会报错,当然应该有相应的解决方案,但是出于安全考虑先创建用户,一下安装步骤是我已经安装完成的操作步骤,所以没有详细截图。
一、使用root创建一个新用户。
在创建密码时提示密码长度问题可以不予理会。
完成后一定要把文件上传到此用户的目录下才能进行操作,/home/root01/下。
如果没有其他需求则不用分配权限和用户组等等...
#1.新建用户 useradd root01 #2.设置密码 会提示输入密码一共两次 passwd root #3.切换至root01用户 su - root01 #4.上传安装包 elasticsearch-6.8.0.tar.gz等等三个
如图
二、安装es
以下操作切换至新用户 root01 操作
解压es,顺序必须是es --> 再可视化或分词器
解压
tar xvf elasticsearch-6.8.0.tar.gz
删除安装包(可选)
rm -rf elasticsearch-6.8.0.tar.gz
重命名
mv elasticsearch-6.8.0 elasticsearch
为了方便操作修改了文件名。
基础配置(可选)
#修改jvm内存大小
vim /home/es-33/elasticsearch/config/jvm.options
-Xms256m
-Xmx256m
#如果你的可分配内存有限
启动配置(必要)
#配置数据目录
path.data: ../data
#配置logs目录
path.logs: ../logs
#开启远程访问
network.host: 0.0.0.0
此处我写的两个目录都是相对路径,因为我将此目录创建在了此文件的上级目录中,根据需求写相对或者绝对都可以的。
去bin目录下启动

执行
#前台启动 退出命令 ctrl c
./elasticsearh
#后台启动
./elasticsearh -d
可能会报错 需要切换至root用户操作解决
错误1:
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
解决:
vi /etc/security/limits.conf
#可打开的文件描述符的最大数(软限制)
* soft nofile 65536
#可打开的文件描述符的最大数(硬限制)
* hard nofile 131072
#单个用户可用的最大进程数量(软限制)
* soft nproc 4096
#单个用户可用的最大进程数量(硬限制)
* hard nproc 4096
错误2:
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
#打开sysctl.conf
vi /etc/sysctl.conf
#添加以下配置
vm.max_map_count=262144
#测试生效
sysctl -p
执行完以上操作以后基本可以使用了
继续测试启动...

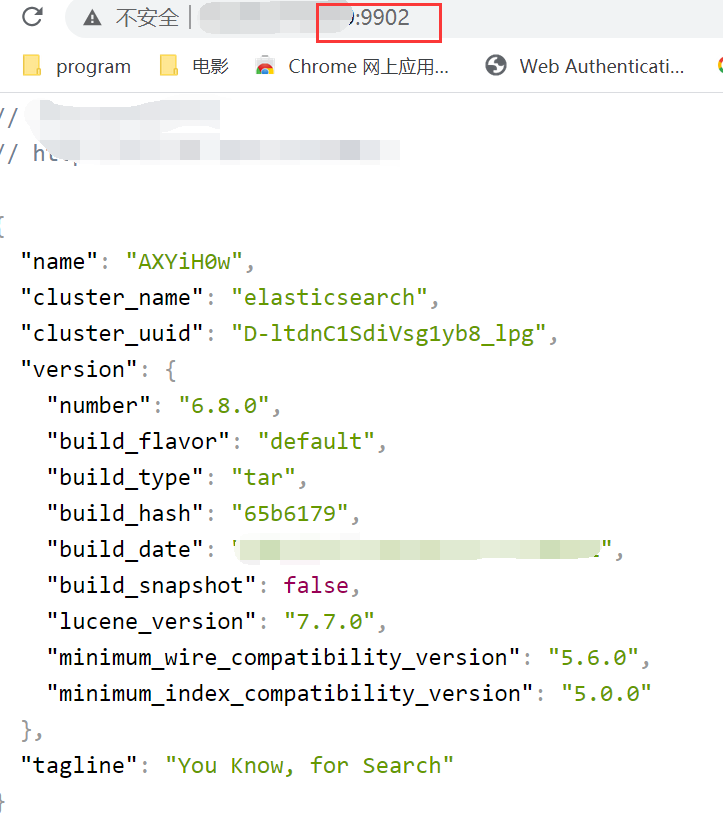
启动成功,默认端口为9200访问即可,我修改了端口为9902所以如图就访问成功了
三、安装可视化 kibana
切换至root01用户
#解压
tar kibana-6.8.0-linux-x86_64.tar.gz
#删除原压缩包(可选)
rm -rf kibana-6.8.0-linux-x86_64.tar.gz
#重命名 mv 原文件名 新文件名
mv kibana-6.8.0-linux-x86_64.tar.gz kibana
修改配置文件
#修改配置文件
vim /home/es-33/kibana/config/kibana.yml
server.host: "0.0.0.0"
i18n.locale: "zh-CN"
启动
#启动 #一定要先启动es再启动kibana
kibana/bin/ ./kibana #访问 http://ip:5601(默认端口)

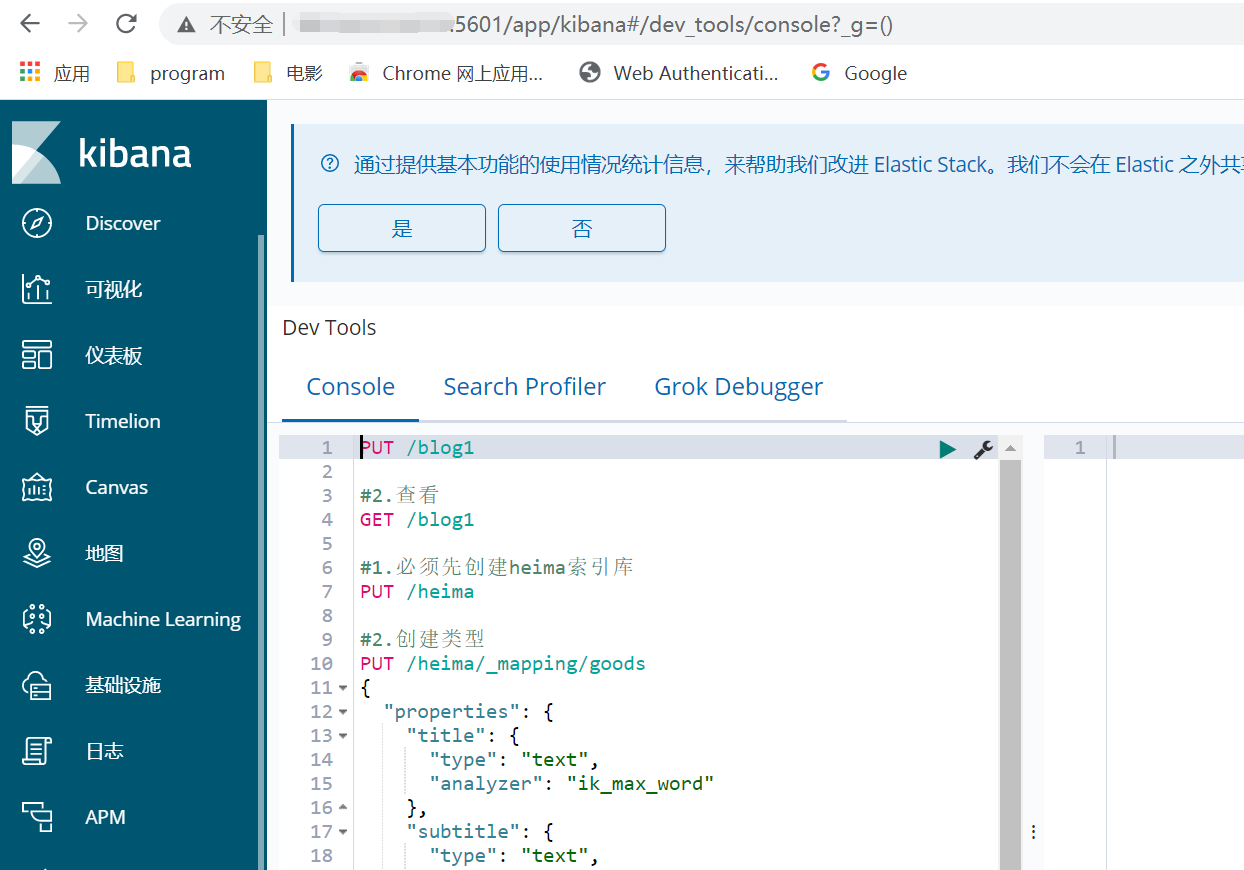
四、安装分词词库
#切换至es组件目录下
cd /home/root01/elasticsearch/plugins
#创建es读取分词的文件夹
mkdir analysis-ik
#切换文件夹
cd analysis-ik
#需要将分词库解压到此文件下
unzip elasticsearch-analysis-ik-6.8.0.zip
扩展自定义词库
安装完成分词库以后可以看到
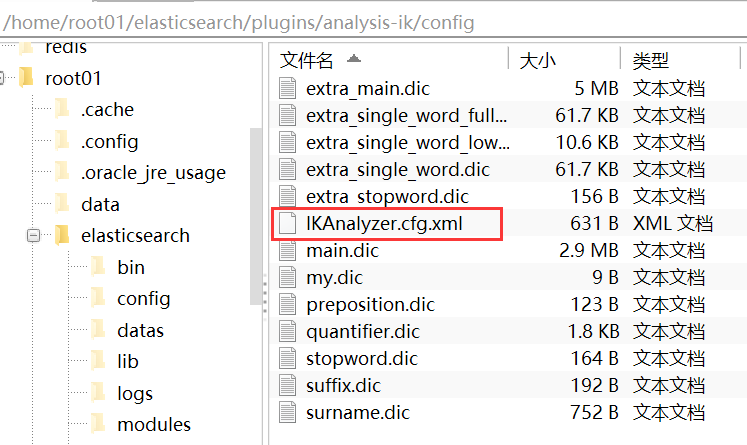
圈红的时是加载自定义词库文件的配置文件,dic后缀的文件为官方词库
一些生僻的或者人名分词需要创建自己的分词词库,例如我在这里创建的my.dic
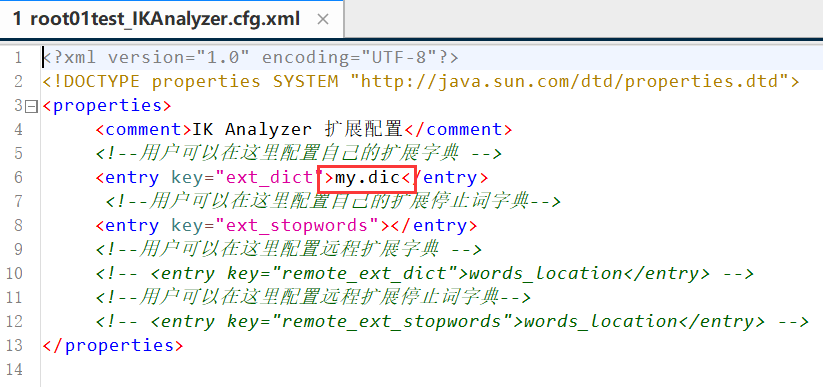
此时重启es和可视化可以看到重启es时加载到了自定义词库了
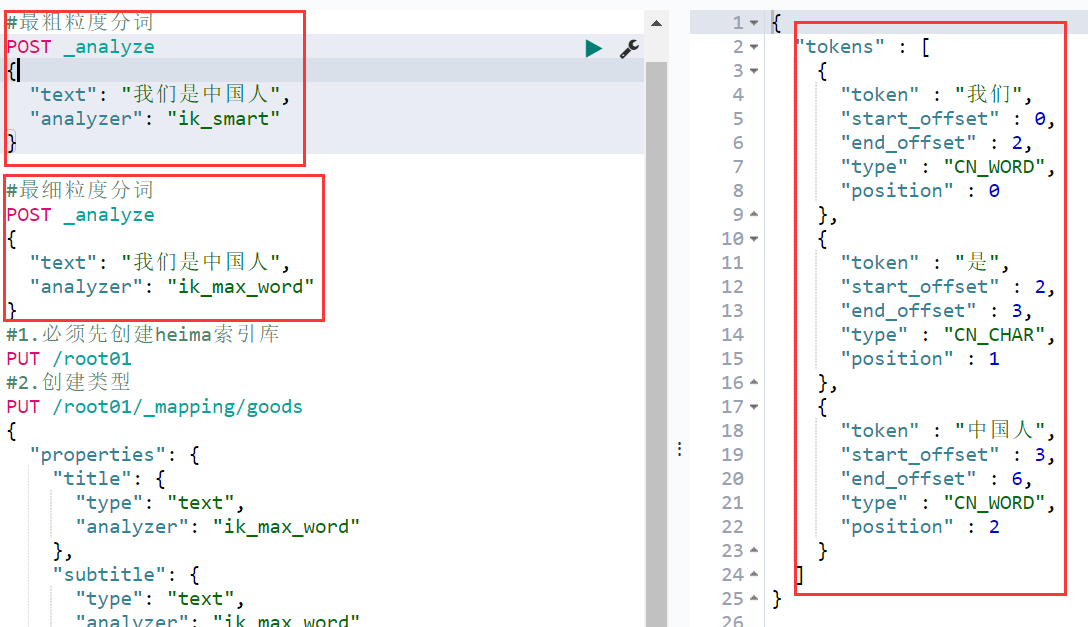
最后测一下分词,关于分词解释
#最粗粒度分词 POST _analyze { "text": "我们是中国人", "analyzer": "ik_smart" } #最细粒度分词 POST _analyze { "text": "我们是中国人", "analyzer": "ik_max_word" }