

jieba分词
jieba分词,聊斋29
代码:
import jieba
txt = open("D:\python-learning\liaozhai.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "小倩" or word == "鬼妻":
rword = "聂小倩"
elif word == "采臣":
rword = "唐僧"
elif word == "黑山" or word == "万妖群魔之首":
rword = "黑山老妖"
elif word == "十四娘":
rword = "辛十四娘"
elif word == "子楚":
rword = "孙子楚"
elif word == "赵阿宝":
rword = "阿宝"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
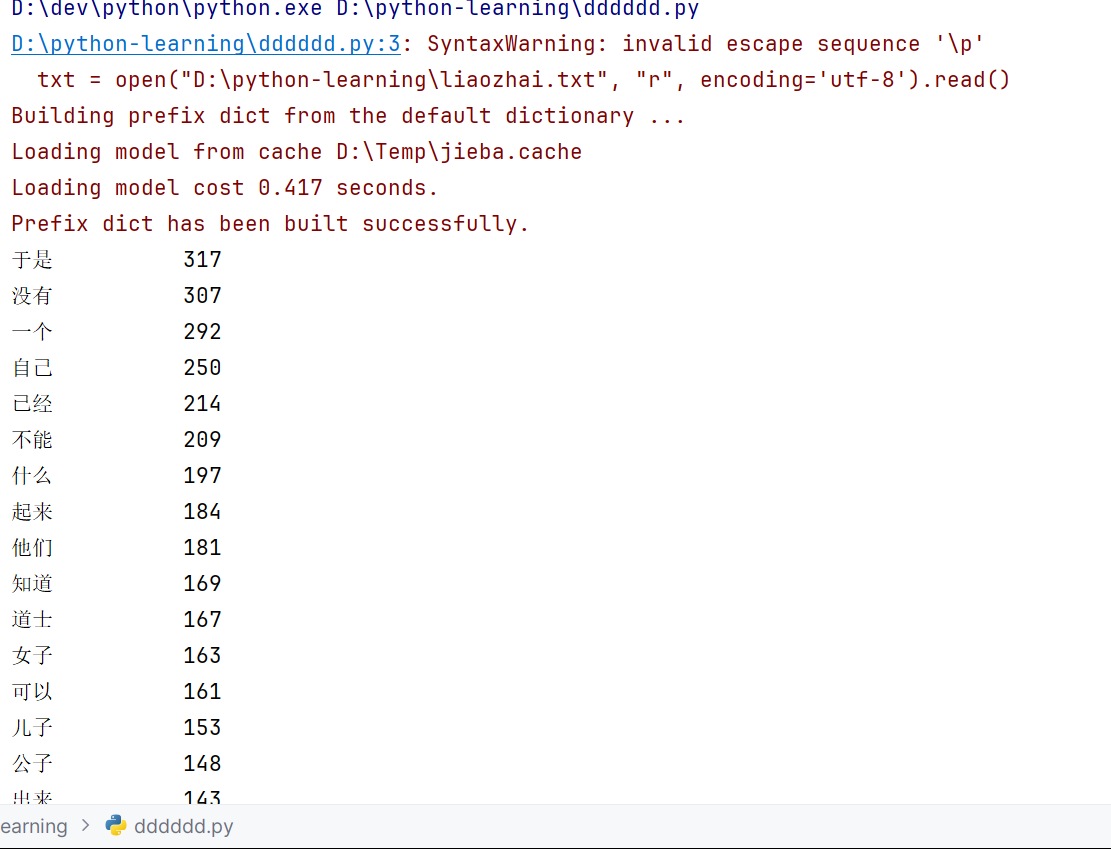
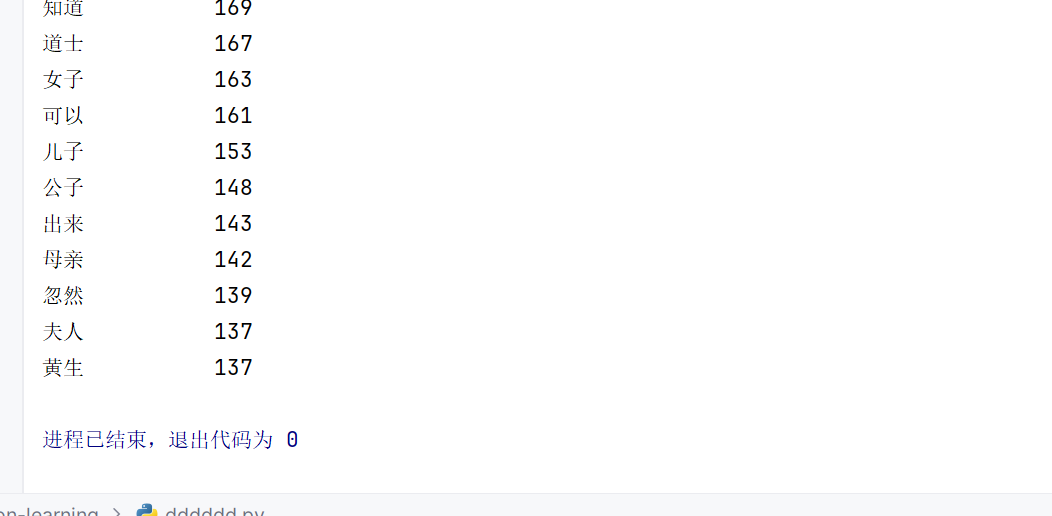
for i in range(20):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)