
Python正则表达式(转)
正则表达式(Regular expression)是组成搜索模式的一组字符序列,是记录文本规则的代码,用来检查文本中是否包含指定模式的字符串,通过定义一个规则来匹配字符串。正则表达式广泛应用于在字符串查找和处理中,大多文本编辑器基本都支持正则表达式查找。本文将简要介绍正则表达式语法,然后介绍Python语言中正则表达式使用方法。
正则表达式
Unix之父Ken Tompson将正则表达式引入Unix,后面发展成了grep(Global Regular Expression Print)命令,由于grep不支持+、|与? ,且分组比较麻烦,AT&T的Alfred Aho开发了egrep命令。随着Unix的版本不断演化,Unix中的程序(比如Linux三剑客中的awk、sed)所支持的正则表达式有差异,比较混乱。在1986年制定了POSIX(Portable Operating System Interface)标准,其中统一了正则表达式的语法。
POSIX标准把正则表达式分为两种:BRE(Basic Regular Expressions)和ERE(Extended Regular Expressions )。BRE就是unix系统使用的grep命令,ERE对应egrep命令,是BRE的扩展。而linux系统使用的是GNU标准,linux发行版集成了GNU(Gnu’s Not Unix)套件,GNU在实现了POXIS标准的同时,做了一定的扩展。也包括GNU Basic Regular Expressions 和GNU Extends Regular Expressions。
正则表达式除了POSIX标准之外还有一个Perl分支,Perl与sed和awk兼容,后来演化成为PCRE(Perl Compatible Regular Expressions),是一个用C语言编写的正则表达式函数库,功能很强大,性能比POSIX正则表达式好。PCRE被引入了其他语言中,比如PHP, Tcl, Python, Ruby, C++, Java, R语言等等。
普通正则
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| * | 重复零次或更多次 |
扩展正则
扩展正则:grep加 -E 参数
- grep -E ' 404 | 500' nginx.log
| 代码/语法 | 说明 |
|---|---|
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
| | | 表示或 |
零宽断言
| 语法 | 说明 |
|---|---|
| (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 |
| (?!exp) | 匹配后面不是exp的位置 |
| (?<!exp) | 匹配前面不是exp的位置 |
正则表达式实例
正则表达式在线测试工具:
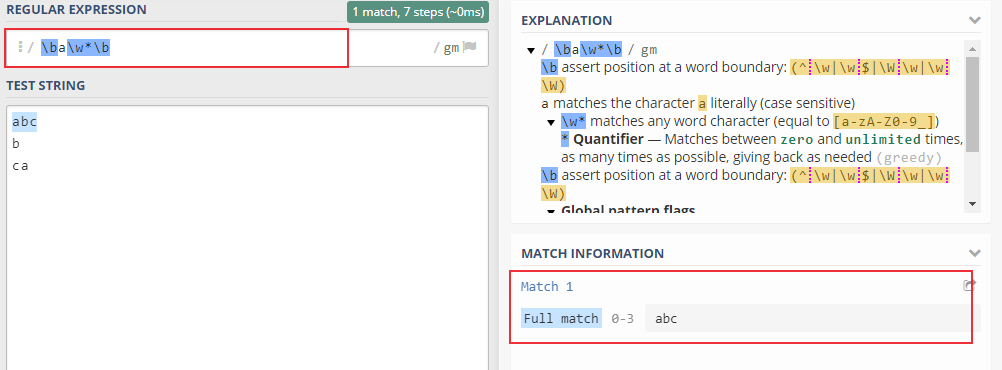
1. 匹配以字母a开头的单词
\ba\w*\b
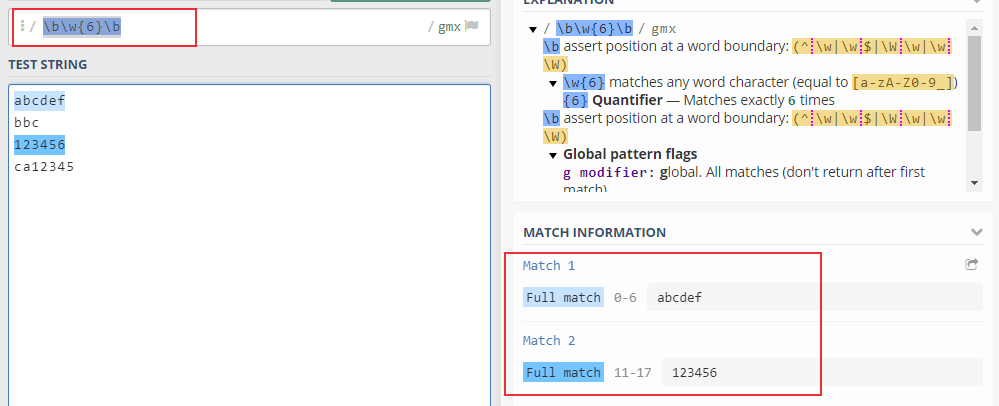
2. 匹配刚好6个字符的单词
\b\w{6}\b
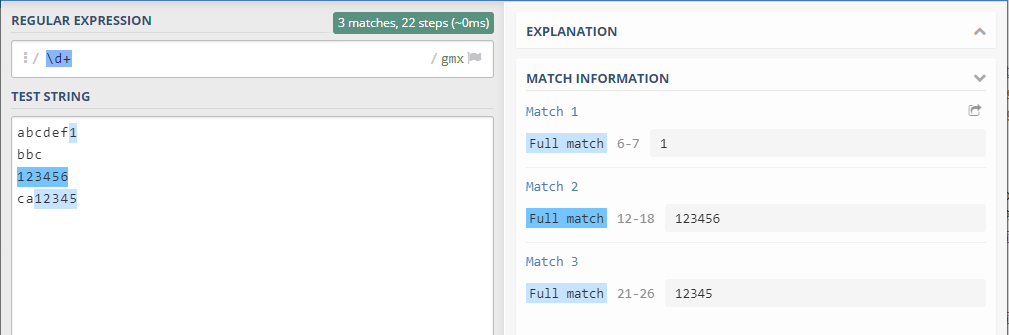
3. 匹配1个或更多连续的数字
\d+
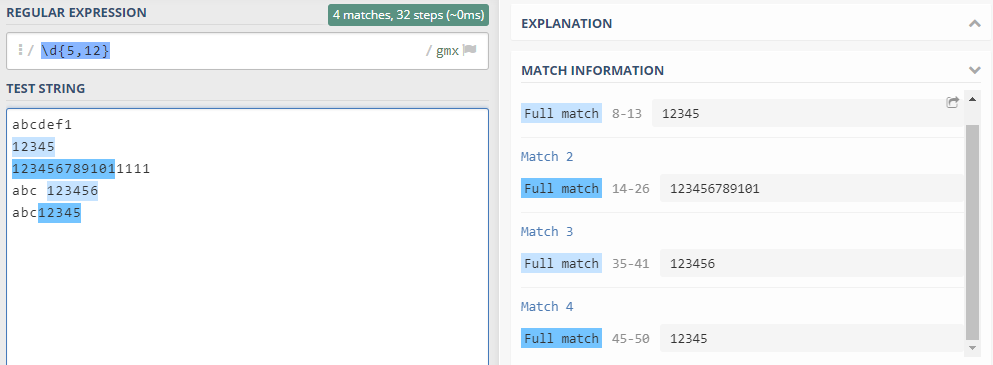
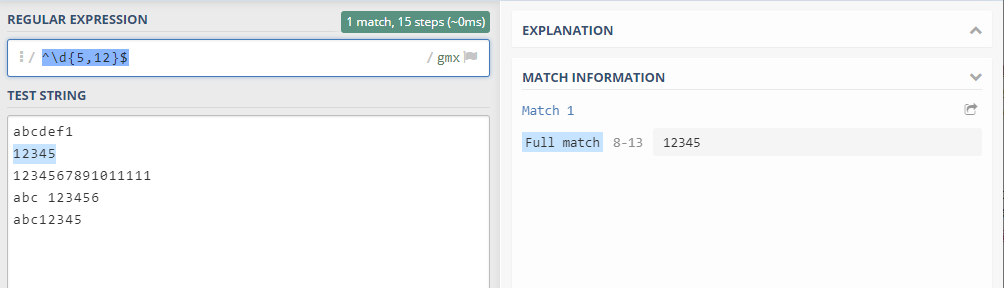
4. 5位到12位QQ号
\d{5,12}
^\d{5,12}$
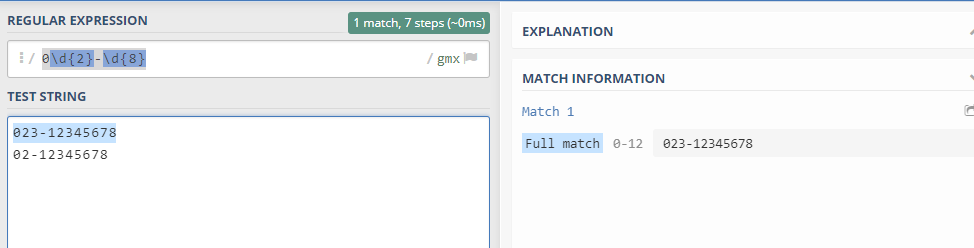
5. 匹配电话号码
0\d{2}-\d{8}
6. 只匹配3位数字
^\d{3}$

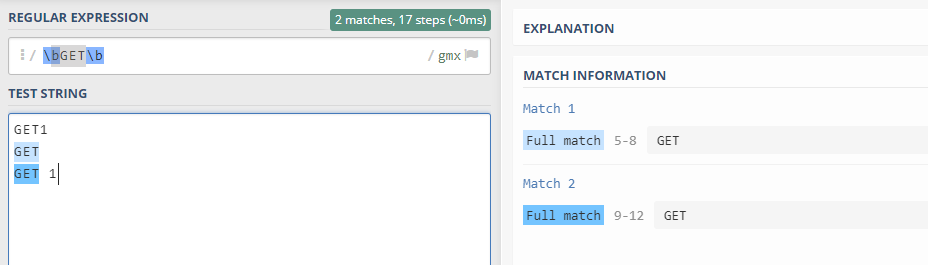
7. 查找单词‘GET’
\bGET\b
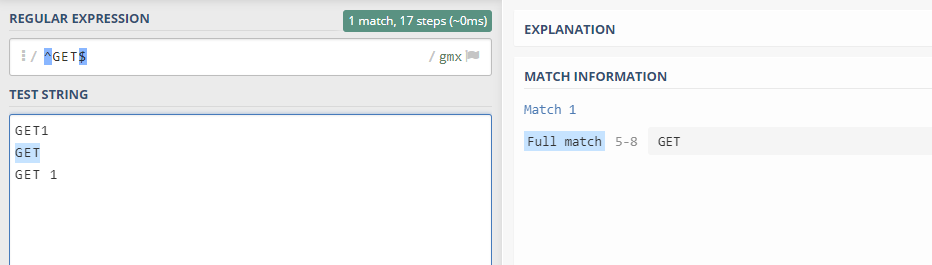
^GET$
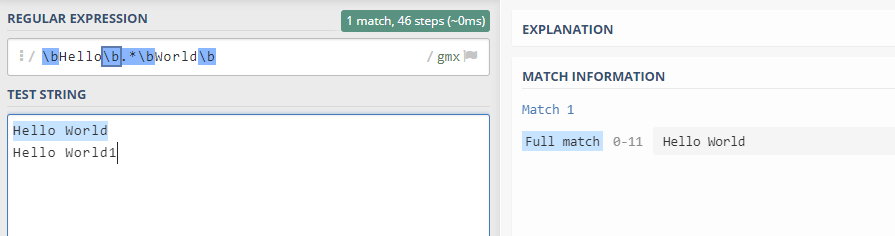
8. 查找‘Hello World’
\bHello\b.*\bWorld\b
Python正则表达式
Python有一个内置正则表达式模块 re ,可以使用它来进行字符串操作:
import re
re模块提供了以下4种方法:
- findall:返回所有匹配项
- search:如果匹配到目标字符,返回一个匹配对象,用于判断是否存在目标字符串
- split:分割
- sub:替换
匹配数字、字母
text = '1&\nbsp;hour(s) 2&\nbsp;min 25&\nbsp;s'
re.findall(r'\d+',text) # 匹配时间(数字)
re.findall(r'\d+|(?<=;)\w+',text) # 匹配时间和单位
output:
['1', '2', '25']
['1', 'hour', '2', 'min', '25', 's']
re.findall(r'\d{2}+',text) # 匹配2位数字
查找替换两个字符串之间内容
替换字符target_text:
xpath_path = '//*[contains(text(),"target_text")]/../td[5]/span' # xpath路径
repl = "需要替换成的字符串"
re.sub(r"(?<=\").*?(?=\")", repl, xpath_path) # 替换要查找的文本
output:
'//*[contains(text(),"需要替换成的字符串")]/../td[5]/span'
添加千位分割符
number = '12345678'
re.sub(r"\B(?=(?:\d{3})+(?!\d))", ",",number) # 替换要查找的文本
re.sub(r"\B(?:(?:\d{3})+(?!\d))", ",",number)
output:
'12,345,678'
'12,'
(?:\d{3})+(?!\d):
- 查找3n(数字) + 非数字 组合
(?:exp) :
- 匹配exp,不捕获匹配的文本(非获取匹配),也不给此分组分配组号,当执行了第一次匹配时,匹配到了行尾,直接将345678替换成了“,”。
参考文档
- 正则表达式30分钟入门教程:https://deerchao.cn/tutorials/regex/regex.htm
- github项目learn-regex:https://github.com/ziishaned/learn-regex
- https://www.w3schools.com/python/python_regex.asp

 浙公网安备 33010602011771号
浙公网安备 33010602011771号