
httprunner2.x--HttpRunner自动化测试用例分层思想
HttpRunner自动化测试用例分层思想
转载:https://blog.csdn.net/weixin_42007999/article/details/105768092
在 HttpRunner 中提出了测试用例的分层思想。通过上一节脚手架的功能,实际已经体现了这种思想,将不同种类和作用的文件置于不同的目录,增加了测试的可维护性和复用性。
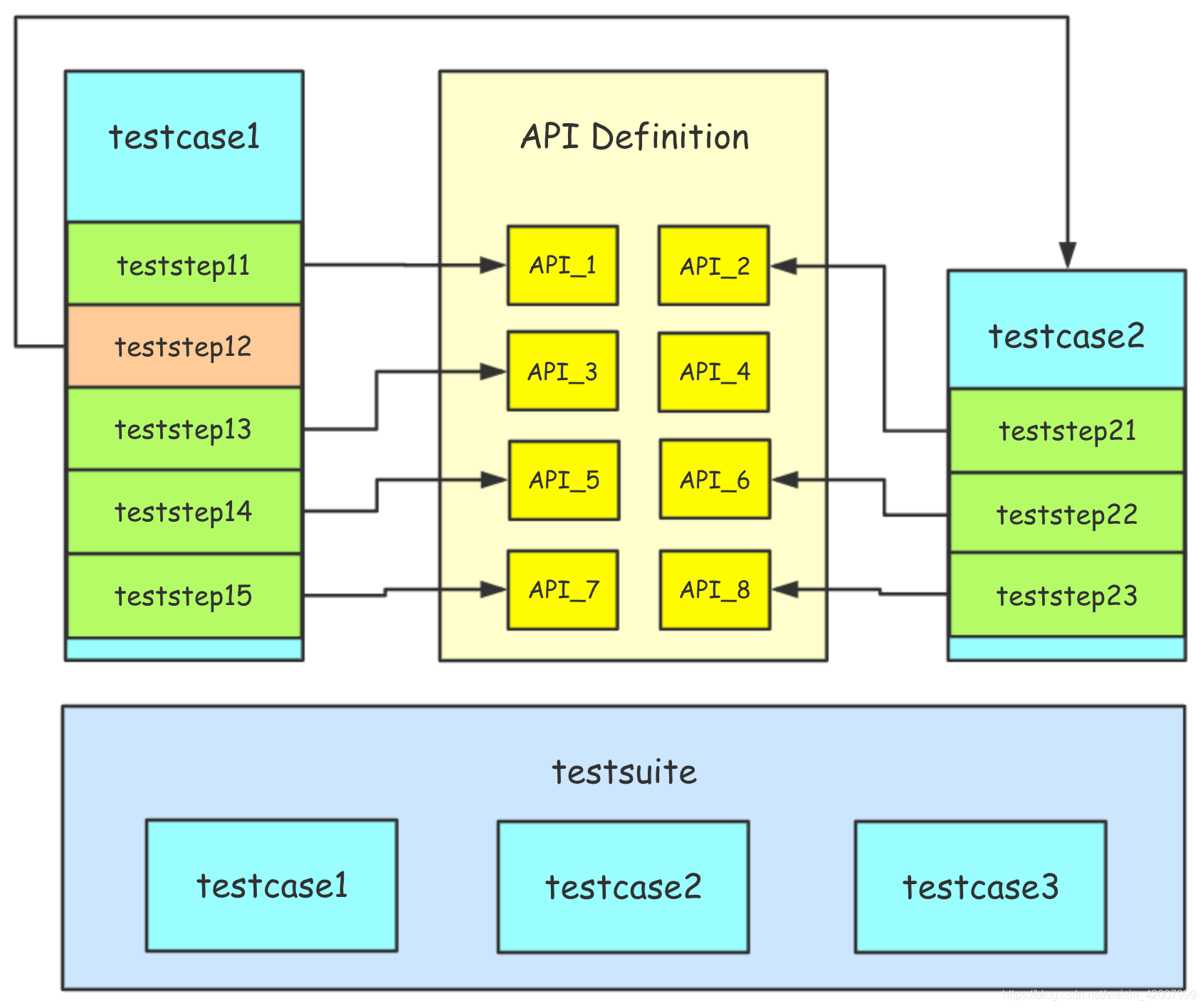
HttpRunner 测试用例分层机制的核心是:将接口定义、测试步骤、测试用例、测试场景进行分离,单独进行描述和维护,从而尽可能地减少自动化测试用例的维护成本。
HttpRunner 官方说明: https://docs.httprunner.org/prepare/testcase-layer/
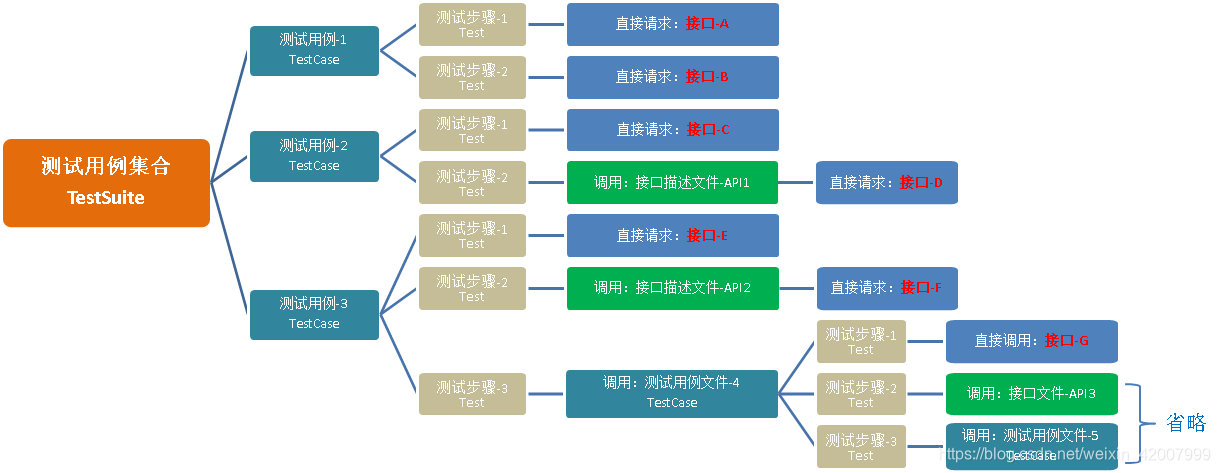
用例分层思想基本内容如下:
1. 接口定义文件:针对每个被测接口(API),单独定义一个文件。该文件可以被用例调用,也可以独立运行。
2. 定义用例文件:
- 定义一个独立的测试用例文件(testcase),包括至少一个测试步骤(test);
- 每个测试步骤中包括请求的接口、预期结果、实际结果等用例的基本要素;
- 可以调用接口定义文件;
- 可以调用其他的测试用例文件。
3. 测试用例集合文件:设置批量运行测试用例。测试用例集合(testsuite)是测试用例的“无序”集合,集合中的测试用例应该都是相互独立,不存在先后依赖关系的;如果确实存在先后依赖关系,那就需要在测试用例中完成依赖的处理。
4. 在测试用例集合的基础上,HttpRunner 实现了参数化数据驱动机制:
- 将用例中使用到的数据以变量(参数)的形式代替;
- 将测试数据单独存储,例如存储到csv文件或者环境变量中;
- 系统运行的时候,自动去存储的文件中获取测试数据。
注意:
- 用例之间可以进行嵌套调用,既可以调用“接口定义文件”,又可以调用“其他测试用例文件”,相当于多个用例之间可以实现“链条式”的调用,进而实现不同的业务流程和场景的测试。
- 测试用例集合虽然也是对用例的调用,但是没有规范这些用例的执行顺序,是一个无序的集合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号