01-01 Ceph的工作原理与流程简述
一:系统概述
1 什么是Ceph?
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式的存储系统。
“统一的”:意味着Ceph可以一套存储系统同时提供对象存储、块存储和文件系统存储三种功能,以便在满足不同应用需求的前提下简化部署和运维。
“分布式”:在Ceph系统中则意味着真正的无中心结构和没有理论上限的系统规模可扩展性。
2 为什么要关注Ceph?
首先,Ceph本身确实具有较为突出的优势。其先进的核心设计思想,概括为八个字—“无需查表,算算就好”。
其次,Ceph目前在OpenStack社区中备受重视。
二: ceph系统层次
自下向上,可以将Ceph系统分为四个层次:
基础存储系统RADOS(Reliable, Autonomic, Distributed Object Store,即可靠的、自动化的、分布式的对象存储)
基础库LIBRADOS
高层应用接口:包括了三个部分:RADOS GW(RADOS Gateway)、 RBD(Reliable Block Device)和Ceph FS(Ceph File System)
应用层

三:RADOS
Ceph的底层是RADOS,它由两个组件组成:
一种是为数众多的、负责完成数据存储和维护功能的OSD( Object Storage Device)。
另一种则是若干个负责完成系统状态检测和维护的Monitor。
OSD和monitor之间相互传输节点状态信息,共同得出系统的总体工作状态,并形成一个全局系统状态记录数据结构,即所谓的cluster map。这个数据结构与RADOS提供的特定算法相配合,便实现了Ceph“无需查表,算算就好”的核心机制以及若干优秀特性

OSD的逻辑结构
OSD可以被抽象为两个组成部分,即系统部分和守护进程(OSD deamon)部分。
OSD的系统部分本质上就是一台安装了操作系统和文件系统的计算机,其硬件部分至少包括一个单核的处理器、一定数量的内存、一块硬盘以及一张网卡。
在上述系统平台上,每个OSD拥有一个自己的OSD deamon。这个deamon负责完成OSD的所有逻辑功能,包括与monitor和其他OSD(事实上是其他OSD的deamon)通信以维护更新系统状态,与其他OSD共同完成数据的存储和维护,与client通信完成各种数据对象操作等等。
四:寻址流程
三次映射:
File -> Object -> PG -> OSD
(ion,ono) -> oid -> pgid -> (osd1,osd2,osd3)
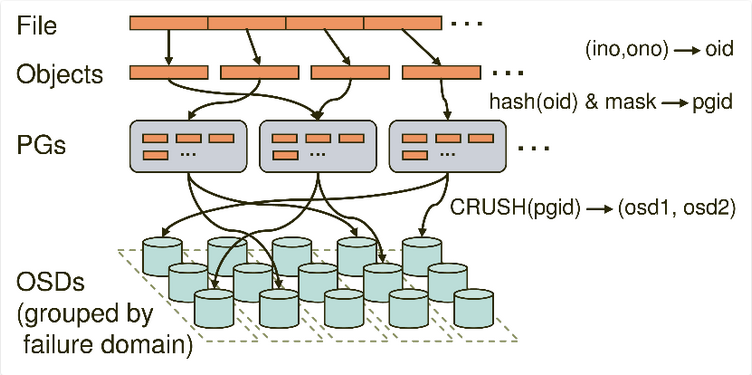
几个概念:
01 File —— 此处的file就是用户需要存储或者访问的文件。对于一个基于Ceph开发的对象存储应用而言,这个file也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
02 Ojbect —— 此处的object是RADOS所看到的“对象”。Object与上面提到的file的区别是,object的最大size由RADOS限定(通常为2MB或4MB),以便实现底层存储的组织管理。因此,当上层应用向RADOS存入size很大的file时,需要将file切分成统一大小的一系列object(最后一个的大小可以不同)进行存储。
03 PG(Placement Group)—— 顾名思义,PG的用途是对object的存储进行组织和位置映射。具体而言,一个PG负责组织若干个object(可以为数千个甚至更多),但一个object只能被映射到一个PG中,即,PG和object之间是“一对多”映射关系。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD之间是“多对多”映射关系。在实践当中,n至少为2,如果用于生产环境,则至少为3。一个OSD上的PG则可达到数百个。事实上,PG数量的设置牵扯到数据分布的均匀性问题。
04 OSD——即object storage device。
05 Failure domain
寻址流程
01 File -> object映射:
这次映射的目的是,将用户要操作的file,映射为RADOS能够处理的object。其映射十分简单,本质上就是按照object的最大size对file进行切分。这种切分的好处有二:一是让大小不限的file变成最大size一致、可以被RADOS高效管理的object;二是让对单一file实施的串行处理变为对多个object实施的并行化处理。

02 Object -> PG映射:
在file被映射为一个或多个object之后,就需要将每个object独立地映射到一个PG中去。计算公式: hash(oid) & mask -> pgid
根据RADOS的设计,给定PG的总数为m(m应该为2的整数幂),则mask的值为m-1。因此,哈希值计算和按位与操作的整体结果事实上是从所有m个PG中近似均匀地随机选择一个。基于这一机制,当有大量object和大量PG时,RADOS能够保证object和PG之间的近似均匀映射。
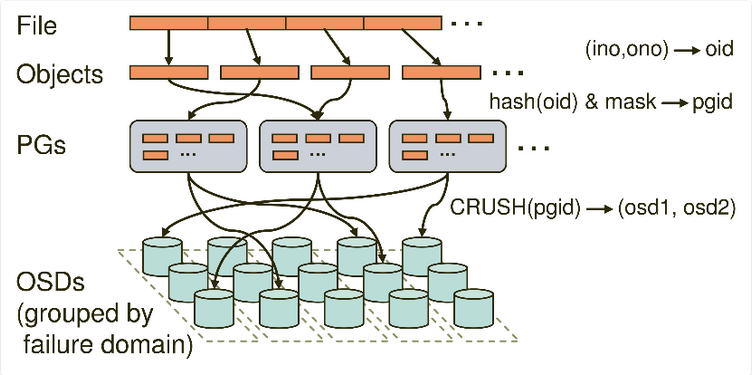
03 PG -> OSD映射:
和“object -> PG”映射中采用的哈希算法不同,这个CRUSH算法的结果不是绝对不变的,而是受到其他因素的影响。其影响因素主要有二:一是当前系统状态,也就是cluster map。当系统中的OSD状态、数量发生变化时,cluster map可能发生变化,而这种变化将会影响到PG与OSD之间的映射。二是存储策略配置。这里的策略主要与安全相关。利用策略配置,系统管理员可以指定承载同一个PG的3个OSD分别位于数据中心的不同服务器乃至机架上,从而进一步改善存储的可靠性。

五:数据操作流程
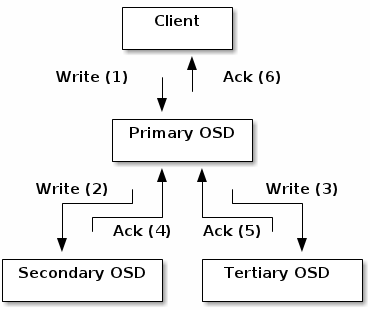
当某个client需要向Ceph集群写入一个file时,首先需要在本地完成寻址流程,将file变为一个object,然后找出存储该object的一组三个OSD。
找出三个OSD后,client将直接和Primary OSD通信,发起写入操作(步骤1)。Primary OSD收到请求后,分别向Secondary OSD和Tertiary OSD发起写入操作(步骤2、3)。当Secondary OSD和Tertiary OSD各自完成写入操作后,将分别向Primary OSD发送确认信息(步骤4、5)。当Primary OSD确信其他两个OSD的写入完成后,则自己也完成数据写入,并向client确认object写入操作完成(步骤6)
六:集群维护
由若干个monitor共同负责整个Ceph集群中所有OSD状态的发现与记录,并且共同形成cluster map的master版本,然后扩散至全体OSD以及client。OSD使用cluster map进行数据的维护,而client使用cluster map进行数据的寻址。
monitor并不主动轮询各个OSD的当前状态。正相反,OSD需要向monitor上报状态信息。常见的上报有两种情况:一是新的OSD被加入集群,二是某个OSD发现自身或者其他OSD发生异常。在收到这些上报信息后,monitor将更新cluster map信息并加以扩散。
Cluster map的内容:
Epoch,即版本号,为一个单调递增序列,Epoch越大,则cluster map版本越新。
各个OSD的网络地址。
各个OSD的状态。up或者down,表明OSD是否正常工作;in或者out,表明OSD是否在至少一个PG中。
CRUSH算法配置参数。表明了Ceph集群的物理层级关系(cluster hierarchy),位置映射规则(placement rules)
新增一个OSD
首先根据配置信息与monitor通信,monitor将其加入cluster map,并设置为up且out状态,再将最新版本的cluster map发给这个新OSD。
自动化的故障恢复(Failure recovery)
收到monitor发过来的cluster map之后,这个新OSD计算出自己所承载的PG以及和自己承载同一个PG的其他OSD。然后与这些OSD取得联系。如果这个PG目前处于降级状态(即承载该PG的OSD个数少于正常值),则其他OSD将把这个PG内的所有对象和元数据赋值给新OSD。数据复制完成后,新OSD被置为up且in状态,cluster map也更新。
自动化的re-balancing过程
如果该PG目前一切正常,则这个新OSD将替换掉现有OSD中的一个(PG内将重新选出Primary OSD),并承担其数据。在数据复制完成后,新OSD被置为up且in状态,而被替换的OSD将推出该PG。而cluster map内容也将据此更新。
自动化的故障探测(Failure detection)过程
如果一个OSD发现和自己共同承担一个PG的另一个OSD无法联通,则会将这一情况上报monitor。此外,如果一个OSD deamon发现自身工作状态异常,也将把异常情况主动上报给monitor。此时,monitor将把出现问题的OSD的状态设置为down且in。如果超过某一预定时间期限该OSD仍然无法恢复正常,则其状态将被设置为down且out。如果该OSD能够恢复正常,则其状态会恢复成up且in。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}