02-01 ceph集群安装配置文档
简介:
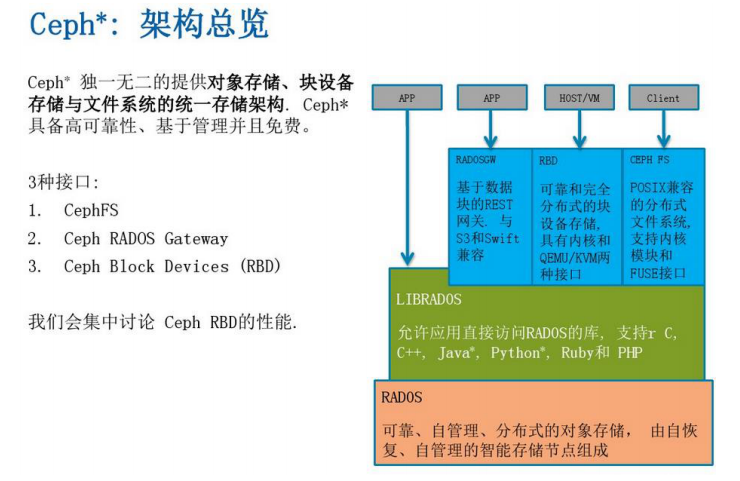
Ceph 是统一分布式存储系统,具有优异的性能、可靠性、可扩展性。Ceph 的底层是 RADOS(可靠、自动、分布式对象存储),可以通过 LIBRADOS 直接访问到 RADOS 的对象存储系统。RBD(块设备接口)、RADOS Gateway(对象存储接口)、Ceph File System(POSIX 接口)都是基于 RADOS 的。
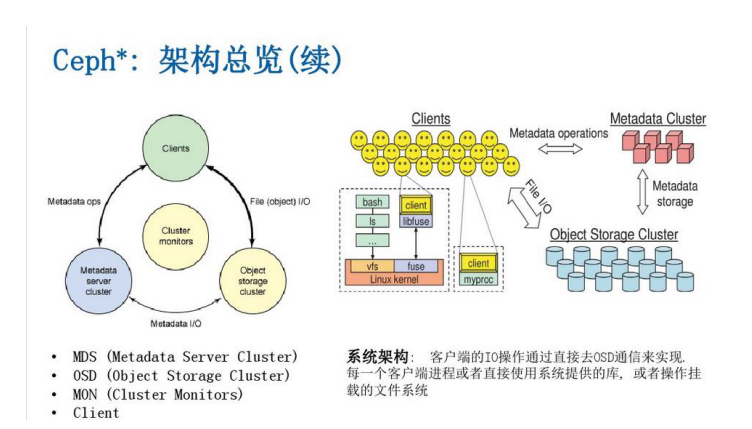
一:安装配置环境介绍
1:系统版本:
more /etc/redhat-release
CentOS Linux release 7.1.1503 (Core)
2:内核版本:
uname –a
Linux nc3 3.10.0-229.11.1.el7.x86_64 #1 SMP Thu Aug 6 01:06:18 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
3:ceph 版本:
ceph -v
ceph version 0.94.3
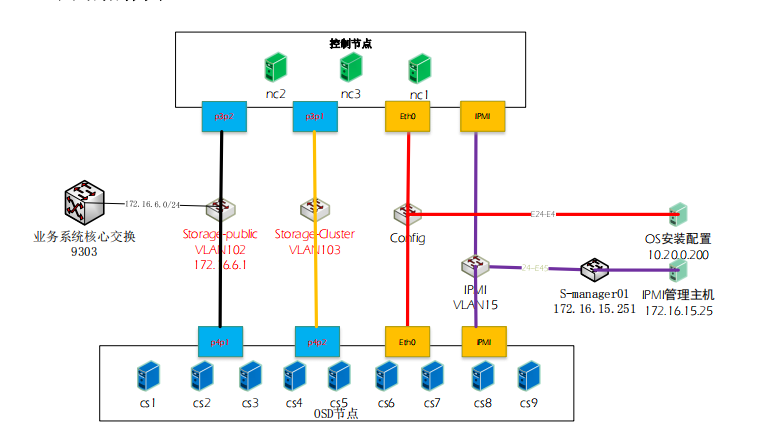
网络拓扑图
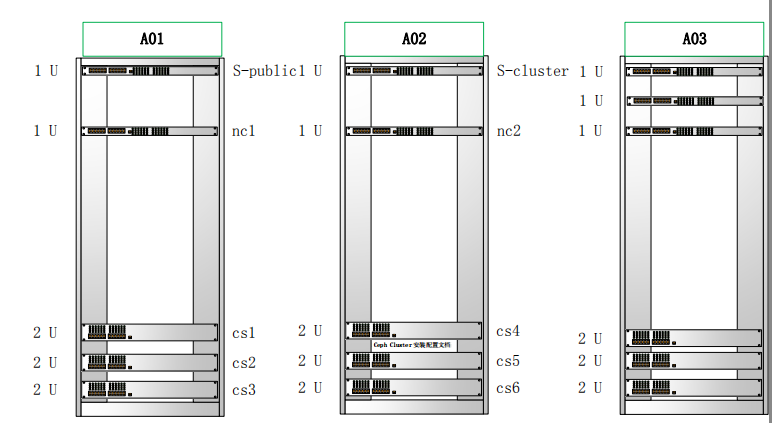
设备位置图
4:ceph-deploy 版本:
[root@nc1 ~]# ceph-deploy --version 1.5.28
业务系统核心交换9303
Storage-public VLAN102 172.16.6.1
Storage-Cluster VLAN103
Config
IPMI VLAN15
S-manager01 172.16.15.251
OS安装配置10.20.0.200
IPMI管理主机172.16.15.25
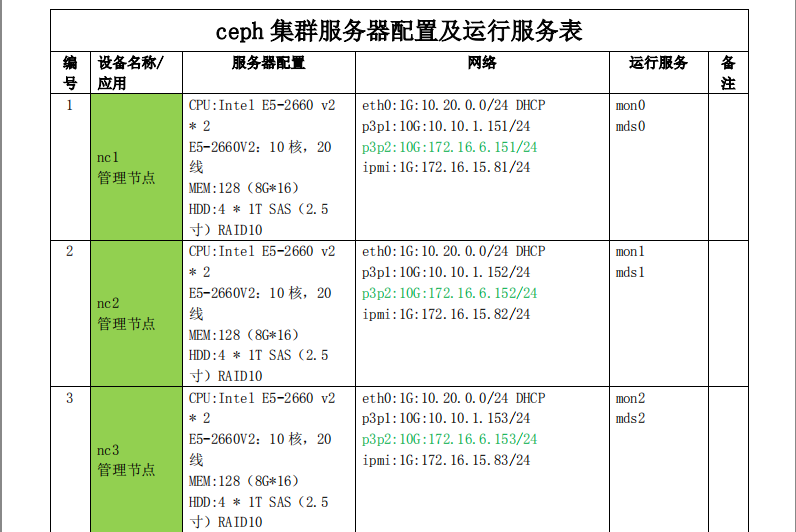
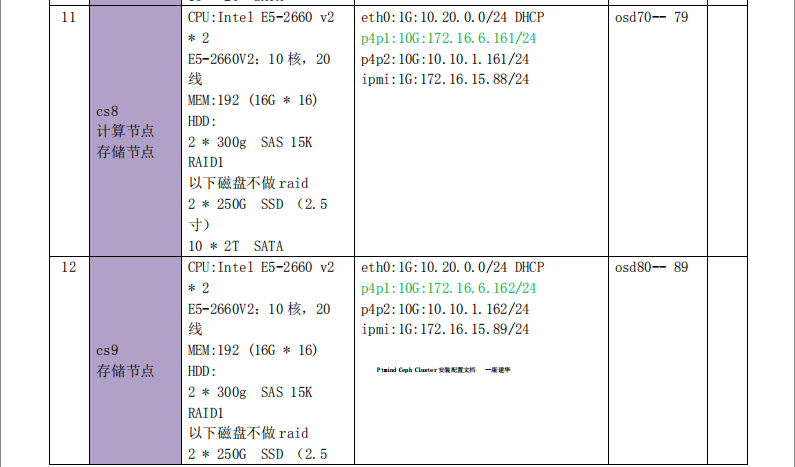
5 服务器配置信息及运行服务统计




二:系统软件基础包初始化:
1:安装 EPEL 软件源:
rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-5.noarch.rpm yum -y update
yum -y upgrade
2:常用软件包、常用工具等(非必须、推荐安装)
yum -y install gcc gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel \ zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel zip unzip ncurses ncurses-devel curl curl-devel e2fsprogs \ e2fsprogs-devel krb5-devel libidn libidn-devel openssl openssh openssl-devel nss_ldap openldap openldap-devel openldap- clients \
openldap-servers libxslt-devel libevent-devel ntp libtool-ltdl bison libtool vim-enhanced python wget lsof iptraf strace lrzsz
\
kernel-devel kernel-headers pam-devel Tcl/Tk cmake ncurses-devel bison setuptool popt-devel net-snmp screen perl- devel \
pcre-devel net-snmp screen tcpdump rsync sysstat man iptables sudo idconfig git system-config-network-tui bind-utils update \
arpscan tmux elinks numactl iftop bwm-ng net-tools
三:集群主机系统初始化准备
所有 Ceph 集群节点采用 CentOS 7.1 版本(CentOS-7-x86_64-Minimal-1503-01.iso),所有文件系统采用 Ceph
官方推荐的 xfs,所有节点的操作系统都装在 RAID1 上Ptm,ind C其eph 他Clust的er 安硬装配盘置文档单独--康建用华 ,不做任何 RAID。安装完 CentOS 后我们需要在每个节点上(包括 ceph-deploy)做以下配置:
1:规范系统主机名;
centos 使用以下命令:
hostnamectl set-hostname 主机名
2:添加 hosts 文件实现集群主机名与主机名之间相互能够解析
(host 文件添加主机名不要使用 fqdn 方式)
[root@nc1 ~]# vim /etc/hosts
172.16.6.154 cs
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.16.6.151 nc1 ceph-deploy
172.16.6.152nc2
172.16.6.153nc3
172.16.6.154cs1
172.16.6.155cs2
172.16.6.156cs3
172.16.6.157cs4
172.16.6.158cs5
172.16.6.159cs6
172.16.6.160cs7
172.16.6.161cs8
172.16.6.162cs9
3:每台 ssh-copy-id 完成这些服务器之间免 ssh 密码登录;
ssh-copy-id node###
4:关闭防火墙或者开放 6789/6800~6900 端口、关闭 SELINUX;
关闭 SELINUX
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
setenforce 0
打开 Ceph 需要的端口
firewall-cmd --zone=public --add-port=6789/tcp --permanent firewall-cmd --zone=public --add-port=6800-7100/tcp --permanent firewall-cmd --reload
5:关闭防火墙及开机启动
systemctl stop firewalld.service systemctl disable firewalld.service
5:配置 ntp 服务,保证集群服务器时间统一;
安装 ntp 同步时间
yum -y install ntp ntpdate ntp-doc systemctl enable ntpd.service systemctl start ntpd.service
或者添加 crontab ,执行自动时间同步;
cat >>/etc/crontab<<EOF
20 */1 * * * root ntpdate 172.16.5.100 && --systohc EOF
6:系统优化类
#set max user processes
sed -i 's/4096/102400/' /etc/security/limits.d/20-nproc.conf
#set ulimit
cat /etc/rc.local | grep "ulimit -SHn 102400" || echo "ulimit -SHn 102400" >> /etc/rc.local
修改最大打开文件句柄数
cat /etc/security/limits.conf | grep "^* - sigpending 256612" || cat >>/etc/security/limits.conf<<EOF
- soft nofile 102400
- hard nofile 102400
- soft nproc 102400
- hard nproc 102400
- - sigpending 256612 EOF
四:集群优化配置
1:优化前提
Processor
ceph-osd 进程在运行过程中会消耗 CPU 资源,所以一般会为每一个 ceph-osd 进程绑定一个 CPU 核上。当然如
果你使用 EC 方式,可能需要更多的 CPU 资源。
ceph-mon 进程并不十分消耗 CPU 资源,所以不必为 ceph-mon 进程预留过多的 CPU 资源。
ceph-msd 也是非常消耗 CPU 资源的,所以需要提供更多的 CPU 资源。内存
ceph-mon 和 ceph-mds 需要 2G 内存,每个 ceph-osd 进程需要 1G 内存,当然 2G 更好。
2: 开启 VT 和 HT
Hyper-Threading(HT)
基本做云平台的,VT 和 HT 打开都是必须的,超线程技术(HT)就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了 CPU 的闲置时间,提高的 CPU 的运行效率。
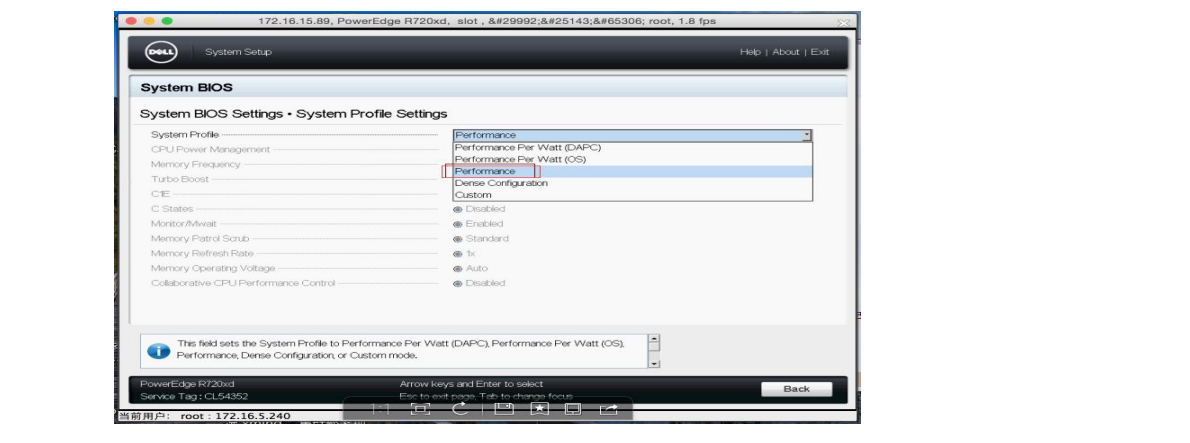
3:关闭 CPU 节能
关闭节能后,对性能还是有所提升的,所以坚决调整成性能型(Performance)。当然也可以在操作系统级别进行 调整,详细的调整过程请自行谷歌。Dellr720xd bios 配置截图如下:
也可以在系统层面进行设置,配置方法如下:
for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f $CPUFREQ ] || continue; echo -n performance > $CPUFREQ; done
4:关闭 NUMA
简单来说,NUMA 思路就是将内存和 CPU 分割为多Pt个mind 区Ceph域Clus,ter每安装个配置文区档 域--康叫建华做 NODE,然后将 NODE 高速互联。 node
内 cpu 与内存访问速度快于访问其他 node 的内存, NUMA 可能会在某些情况下影响 ceph-osd 。解决的方案,一种是通过 BIOS 关闭 NUMA,配置(dellr720xd)截图如下:
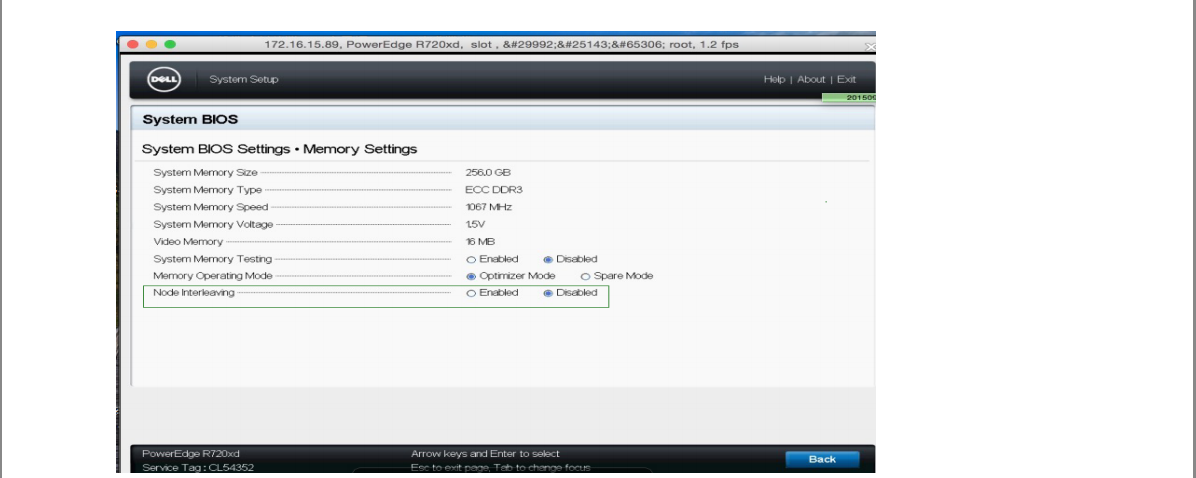
“Node Interleaving(节点交错)”这项设置是针对 CPU 内部集成的内存控制器,笔者对它开始有所了解大约是在 AMD 当年推出第一代 K8 架构的 Opteron 处理器。由于整合内存控制器的 DP/MP 系统中每个 CPU 都可以直接控制一部分内存,因此访问模式分为 NUMA(非一致性内存访问)和 Node Interleaving 两种。根据我们以往的理解, 前者具有更好的 OS/应用兼容性,而后者在单一处理器访问内存时可以提供更高的性能(跨 CPU 节点并发访问)。
另外一种就是通过 cgroup 将 ceph-osd 进程与某一个 CPU Core 以及同一 NODE 下的内存进行绑定。但是第二种看起来更麻烦,所以一般部署的时候可以在系统层面关闭 NUMA。CentOS 系统下,通过修改/etc/grub.conf 文件,添加 numa=off 来关闭 NUMA。
Centos 6 版本系统配置方法:
kernel /vmlinuz-2.6.32-504.12.2.el6.x86_64 ro root=UUID=870d47f8-0357-4a32-909f-74173a9f0633 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM biosdevname=0 numa=off
Centos7 版本系统配置方法:
修改 kernel(centos7)

运行命令 grub2-mkconfig -o /boot/grub2/grub.cfg 来重新生成 GRUB 配置并更新内核参数。

重启服务器
5:网络优化
万兆网络现在基本上是跑 Ceph 必备的,网络规划上,也尽量考虑分离 cilent 和 cluster 网络。
修改网络 MTU 值,需要交换机端需要支持该 Jumbo frames 特性,另外科普一下万兆交换机端口默认的设置的 mtu 是 9216 不需要设置,千兆交换机的 mtu 值默认是 1600。我们使用的是华为的 6700 万兆交换,查看端口详细信息如下图:
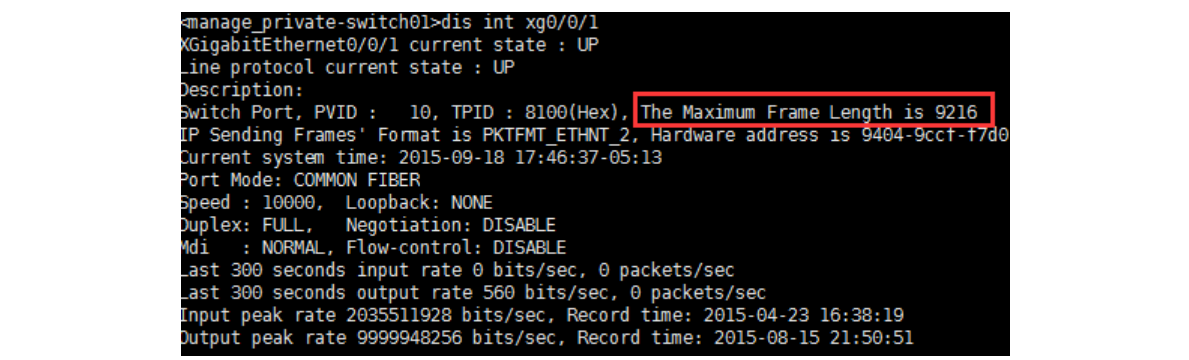
服务器需要设置一下服务器 ceph 集群使用的网卡,临时修改使用 ifconfig eth0 mtu 9000,持久生效修改方法如下:
nc 节点
echo "MTU=9000" | tee -a /etc/sysconfig/network-scripts/ifcfg-p3p*
/etc/init.d/networking restart
cs 节点
echo "MTU=9000" | tee -a /etc/sysconfig/network-scripts/ifcfg-p4p*
/etc/init.d/networking restart
6:修改 read_ahead
read_ahead, 通过数据预读并且记载到随机访问内存方式提高磁盘读操作,查看默认值
cat /sys/block/sda/queue/read_ahead_kb 128
根据一些 Ceph 的公开分享,8192 是比较理想的值。
echo "8192" > /sys/block/sda/queue/read_ahead_kb
批量修改(注意 a b c d e f g h i j 是 osd 分区):
for i in a b c d e f g h i j; do echo ---sd$i----; echo "8192" > /sys/block/sd$i/queue/read_ahead_kb;done
查看验证
for i in a b c d e f g h i j; do echo ---sd$i----; cat /sys/block/sd$i/queue/read_ahead_kb;done
这个参数服务器重启后会自动重置回默认,推荐加入开机启动脚本
chmod +x /etc/rc.d/rc.local #centos7 默认 rc.local 没有执行权限,开机无法执行脚本;
echo 'for i in a b c d e f g h i j; do echo ---sd$i----; echo "8192" >
/sys/block/sd$i/queue/read_ahead_kb;done' >>/etc/rc.d/rc.local
验证
more /etc/rc.d/rc.local
7:关闭 swap
swappiness, 主要控制系统对 swap 的使用,这个参数的调整最先见于 UnitedStack 公开的文档中,猜测调整的原因主要是使用 swap 会影响系统的性能。
echo "vm.swappiness = 0" | tee -a /etc/sysctl.conf
8:调整 Kernel pid max
允许更多的 PIDs (减少滚动翻转问题);
默认是 more /proc/sys/kernel/pid_max
49152
调整为:
echo 4194303 > /proc/sys/kernel/pid_max
永久生效
echo "kernel.pid_max= 4194303" | tee -a /etc/sysctl.conf
9:修改 I/O Scheduler
I/O Scheduler,关于 I/O Scheculder 的调整网上已经有很多资料,这里不再赘述,简单说 SSD 要用 noop,SATA/SAS
使用 deadline。默认:
[root@cs1 ceph]# more /sys/block/sdb/queue/scheduler noop [deadline] cfq
修改:
echo "deadline" > /sys/block/sd[x]/queue/scheduler echo "noop" > /sys/block/sd[x]/queue/scheduler
我们的集群情况
每台存储服务器有 2 块 SSD 盘,盘符为 SSDS=/dev/k| l"用做 journal 的 SSD;10 块 sata 机械盘为 DISKS=/dev/
a| b| c| d| e| f| g| h| i| j
Sata 盘修改方式如下:
for i in a b c d e f g h i j; do echo "deadline" > /sys/block/sd$i/queue/scheduler;done
验证
for i in a b c d e f g h i j; do cat /sys/block/sd$i/queue/schePdtmuindleCerp;hdClousntere安装配置文档
ssd 盘修改方式如下:
for i in k l; do echo "noop" > /sys/block/sd$i/queue/scheduler;done
验证
for i in k l; do cat /sys/block/sd$i/queue/scheduler;done
五:安装部署主机(ceph-deploy)安装环境准备
1:建立主机列表
mkdir -p /workspace/ceph
cat >/workspace/ceph/cephlist.txt <<EOF nc1
nc2 nc3 cs1 cs2 cs3 cs4 cs5 cs6 cs7 cs8 cs9 EOF
2:为所有集群主机创建一个 ceph 工作目录
以后的操作都在这个目录下面进行:
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh root@$ip mkdir -p /etc/ceph ;done
3:同步 hosts 文件
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;rsync -avp --delete /etc/hosts $ip:/etc/;done
4:测试主机名解析
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh $ip ping -c3 ceph-deploy;done
5:ceph-deploy 安装
cephdeploy 节点执行,在/etc/ceph/目录下面进行
1:安装 ceph-deploy
cd /etc/ceph/
yum install ceph-deploy -y
注:以下操作除特殊说明之外,均在 ceph-deploy\nc1 节点上操作。
六:创建 mon 节点
1:安装部署集群软件包:
在所有节点安装 ceph 软件包 ceph-deploy install{ceph-node}[{ceph-node}...]
(注:如果已经用 yum 在每台机器上安装了 ceph,这步可省略)
ceph-deploy install nc{1..3} cs{1..9}
2:在安装部署节使用 ceph-deploy 创建,生成 MON 信息:
命令格式:
2:初始化集群,告诉 ceph-deploy 哪些节点是监控节点,命令成功执行后会在 ceps-cluster 目录下生成 ceph.conf, ceph.log, ceph.mon.keyring 等相关文件:
cd /etc/ceph/
ceph-deploy new nc1 nc2 nc3
执行成功后该目录下会增加三个文件
[root@nc1 ceph]# ll total 12
-rw-r--r-- 1 root root 261 Sep 16 16:07 ceph.conf
-rw-r--r-- 1 root root 3430 Sep 16 16:07 ceph.log
-rw------- 1 root root 73 Sep 16 16:07 ceph.mon.keyring
3:添加初始 monitor 节点和收集秘钥
ceph-deploy mon create-initial
在本地目录下可看到如下密钥环文件:
1.{cluster-name}.client.admin.keyring
2.{cluster-name}.bootstrap-osd.keyring
3.{cluster-name}.bootstrap-mds.keyring
4:验证集群 mon 节点安装成功
[root@nc1 ceph]# ceph -s
cluster 973482fb-acf2-4a39-a691-3f810120b013 health HEALTH_ERR
64 pgs stuck inactive 64 pgs stuck unclean no osds
monmap e1: 3 mons at {nc1=172.16.6.151:6789/0,nc2=172.16.6.152:6789/0,nc3=172.16.6.153:6789/0}
election epoch 4, quorum 0,1,2 nc1,nc2,nc3
osdmap e1: 0 osds: 0 up, 0 in
pgmap v2: 64 pgs, 1 pools, 0 bytes data, 0 objects
0 kB used, 0 kB / 0 kB avail
64 creating
[root@nc1 ceph]# ceph mon_status
{"name":"nc1","rank":0,"state":"leader","election_epoch":6,"quorum":[0,1,2],"outside_quorum":[],"extra_probe_peers":[
"172.16.6.152:6789\/0","172.16.6.153:6789\/0"],"sync_provider":[],"monmap":{"epoch":1,"fsid":"179b040c-d2a2-448e- 813c-
111e0fb17e91","modified":"0.000000","created":"0.000000","mons":[{"rank":0,"name":"nc1","addr":"172.16.6.151:6789
\/0"},{"rank":1,"name":"nc2","addr":"172.16.6.152:6789\/0"},{"rank":2,"name":"nc3","addr":"172.16.6.153:6789\/0"}]}}
[root@nc1 ceph]# ll
七:安装集群 osd 服务
1:查看一下 Ceph 存储节点的硬盘情况:
ceph-deploy disk list cs{1..9}
返回信息如下:
[cs9][DEBUG ] /dev/sda : [cs9][DEBUG ] /dev/sda1 other, xfs [cs9][DEBUG ] /dev/sdb : [cs9][DEBUG ] /dev/sdb1 other, xfs [cs9][DEBUG ] /dev/sdc : [cs9][DEBUG ] /dev/sdc1 other, xfs
[cs9][DEBUG ] /dev/sdd : [cs9][DEBUG ] /dev/sdd1 other, xfs [cs9][DEBUG ] /dev/sde : [cs9][DEBUG ] /dev/sde1 other, xfs [cs9][DEBUG ] /dev/sdf : [cs9][DEBUG ] /dev/sdf1 other, xfs [cs9][DEBUG ] /dev/sdg : [cs9][DEBUG ] /dev/sdg1 other, xfs [cs9][DEBUG ] /dev/sdh : [cs9][DEBUG ] /dev/sdh1 other, xfs [cs9][DEBUG ] /dev/sdi : [cs9][DEBUG ] /dev/sdi1 other, xfs [cs9][DEBUG ] /dev/sdj : [cs9][DEBUG ] /dev/sdj1 other, xfs [cs9][DEBUG ] /dev/sdk : [cs9][DEBUG ] /dev/sdk1 other [cs9][DEBUG ] /dev/sdk2 other [cs9][DEBUG ] /dev/sdk3 other [cs9][DEBUG ] /dev/sdk4 other [cs9][DEBUG ] /dev/sdk5 other [cs9][DEBUG ] /dev/sdl : [cs9][DEBUG ] /dev/sdl1 other [cs9][DEBUG ] /dev/sdl2 other [cs9][DEBUG ] /dev/sdl3 other [cs9][DEBUG ] /dev/sdl4 other [cs9][DEBUG ] /dev/sdl5 other [cs9][DEBUG ] /dev/sdm :
[cs9][DEBUG ] /dev/sdm1 other, xfs, mounted on /boot [cs9][DEBUG ] /dev/sdm2 swap, swap
[cs9][DEBUG ] /dev/sdm3 other, xfs, mounted on /
2:批量格式化磁盘
每台存储服务器有 2 块 SSD 盘,盘符为 SSDS=/dev/k| l"用做 journal 的 SSD;10 块 sata 机械盘为 DISKS=/dev/ a| b| c| d| e| f| g| h| i| j
如果集群服务器磁盘是旧盘有分区,推荐对又有磁盘进行格式化,都是新磁盘可以忽略此步骤。服务器磁盘较多推荐使用该脚本格式化,批量格式化硬盘脚本内容如下:(按需使用)
vi parted.sh
#!/bin/bash
set -e
if [ ! -x "/sbin/parted" ]; then
echo "This script requires /sbin/parted to run!" >&2 exit 1
fi
DISKS="a b c d e f g h i j " for i in ${DISKS}; do
echo "Creating partitions on /dev/sd${i} ..."
parted -a optimal --script /dev/sd${i} -- mktable gpt
parted -a optimal --script /dev/sd${i} -- mkpart primary xfs 0% 100% sleep 1
#echo "Formatting /dev/sd${i}1 ..." mkfs.xfs -f /dev/sd${i}1 &
done
SSDS="k l"
for i in ${SSDS}; do
parted -s /dev/sd${i} mklabel gpt
parted -s /dev/sd${i} mkpart primary 0% 20% parted -s /dev/sd${i} mkpart primary 21% 40% parted -s /dev/sd${i} mkpart primary 41% 60% parted -s /dev/sd${i} mkpart primary 61% 80% parted -s /dev/sd${i} mkpart primary 81% 100%
done
将脚本传输到集群 osd 节点服务器,执行脚本批量初始化磁盘。
传输
for ip in $(cat /workspace/ceph/cephlist.txt);do echo ----$ip-----------;rsync -avp /workspace root@$ip:/ ;done
#执行(osd 节点服务器)
[root@nc1 ceph]# pwd
/workspace/ceph
[root@nc1 ceph]# more cephosd.txt cs1
cs2 cs3 cs4 cs5 cs6 cs7 cs8 cs9
for ip in $(cat /workspace/ceph/cephosd.txt);do echo ----$Pitpmi-n-d -C-ep-h--Cl-u-s-te-r;安s装sh配置r文o档ot-@-康ip sh /workspace/parted.sh;done
3:执行 osd 初始化命令
初始化 Ceph 硬盘,然后创建 osd 存储节点,存储节点:单个硬盘:对应的 journal 分区,一一对应:
for ip in $(cat /workspace/ceph/cephosd.txt);do echo ----$ip-----------; ceph-deploy --overwrite-conf osd prepare
$ip:sda1:/dev/sdk1 $ip:sdb1:/dev/sdk2 $ip:sdc1:/dev/sdk3 $ip:sdd1:/dev/sdk4 $ip:sde1:/dev/sdk5 $ip:sdf1:/dev/sdl1
$ip:sdg1:/dev/sdl2 $ip:sdh1:/dev/sdl3 $ip:sdi1:/dev/sdl4 $ip:sdj1:/dev/sdl5;done
激活 OSD
for ip in $(cat /workspace/ceph/cephosd.txt);do echo ----$ip-----------;ceph-deploy osd activate $ip:sda1:/dev/sdk1
$ip:sdb1:/dev/sdk2 $ip:sdc1:/dev/sdk3 $ip:sdd1:/dev/sdk4 $ip:sde1:/dev/sdk5 $ip:sdf1:/dev/sdl1 $ip:sdg1:/dev/sdl2
$ip:sdh1:/dev/sdl3 $ip:sdi1:/dev/sdl4 $ip:sdj1:/dev/sdl5;done
或者执行
Activate all tagged OSD partitions ceph-disk activate-all
4:验证日志写入位置在 ssd 硬盘分区成功
[root@cs1 ~]# cd /var/lib/ceph/osd/ceph-0/ [root@cs1 ceph-0]# ll
。。。。。。。。。。。。。。。。。。。。。。。
-rw-r--r-- 1 root root 37 Sep 16 18:42 fsid
-rw------- 1 root root 56 Sep 16 18:46 keyring
。。。。。。。。。。。。。。
5:验证 osd 启动状态
确保各个服务器存储磁盘都加入集群,状态为 UP。
[root@nc1 ~]# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 159.02930 root default
-2 16.60992 host cs1
0 1.81999 osd.0 up 1.00000 1.00000
1 1.81999 osd.1 up 1.00000 1.00000
2 1.81999 osd.2 up 1.00000 1.00000
3 1.81999 osd.3 up 1.00000 1.00000
4 1.81999 osd.4 up 1.00000 1.00000
5 1.81999 osd.5 up 1.00000 1.00000
6 1.81999 osd.6 up 1.00000 1.00000
host cs2 ~~~~~ cs9 省略
或者登陆一台存储服务器执行命令如下,查看 osd 磁盘挂在情况
[root@cs1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 1.8T 0 disk
└─sda1 8:1 0 1.8T 0 part /var/lib/ceph/osd/ceph-0
sdb 8:16 0 1.8T 0 disk
└─sdb1 8:17 0 1.8T 0 part /var/lib/ceph/osd/ceph-1
sdc 8:32 0 1.8T 0 disk
└─sdc1 8:33 0 1.8T 0 part /var/lib/ceph/osd/ceph-2
sdd 8:48 0 1.8T 0 disk
└─sdd1 8:49 0 1.8T 0 part /var/lib/ceph/osd/ceph-3
sde 8:64 0 1.8T 0 disk
└─sde1 8:65 0 1.8T 0 part /var/lib/ceph/osd/ceph-4
sdf 8:80 0 1.8T 0 disk
└─sdf1 8:81 0 1.8T 0 part /var/lib/ceph/osd/ceph-5
sdg 8:96 0 1.8T 0 disk
└─sdg1 8:97 0 1.8T 0 part /var/lib/ceph/osd/ceph-6
sdh 8:112 0 1.8T 0 disk
└─sdh1 8:113 0 1.8T 0 part /var/lib/ceph/osd/ceph-7
sdi 8:128 0 1.8T 0 disk
└─sdi1 8:129 0 1.8T 0 part /var/lib/ceph/osd/ceph-8
sdj 8:144 0 232.9G 0 disk
└─sdj1 8:145 0 232.9G 0 part /var/lib/ceph/osd/ceph-9
6:PGs per OSD (2 < min 30)报错解决:
Osd 添加完成后执行 ceph health 报错如下:
ceph health
HEALTH_WARN too few PGs per OSD (2 < min 30)
解决办法:
增加 PG 数目,根据 Total PGs = (#OSDs * 100) / pool size 公式来决定 pg_num(pgp_num 应该设成和 pg_num
一样),所以我们集群的设置多少合适那? 注意 pgp_num 、pg_num 值设置应一样 ,公式如下:
910(osd 数量) * 100/3 (副本数)=90100/3 =3000(最大可设置)
3000 是 2 的倍数,可以直接使用。
Ceph 官方推荐取最接近 2 的指数倍,不能整除的可以稍微加点。如果顺利的话,就应该可以看到 HEALTH_OK
了:
另外 pgp_num 、pg_num 不能一次设置的较大,过大会报错。
[root@nc1 ~]# ceph osd pool set rbd pg_num 3000
Error E2BIG: specified pg_num 3000 is too large (creating 2936 new PGs on ~64 OSDs exceeds per-OSD max of 32)
本次集群设置为 1024 ,具体设置多少比较合适,需要根据性能测试慢慢调试。修改前查看数量
[root@nc1 ~]# ceph osd dump|grep rbd
pool 0 'rbd' replicated size 3 min_size 2 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1 flags hashpspool stripe_width 0
修改配置:
ceph osd pool set rbd pg_num 2048 ceph osd pool set rbd pgp_num 2048
验证:
[root@nc1 ~]# ceph osd dump |grep rbd
pool 0 'rbd' replicated size 3 min_size 2 crush_ruleset 0 object_hash rjenkins pg_num 1024 pgp_num 1024 last_change 382 flags hashpspool stripe_width 0
7:官方推荐 pg 计算公式
详细信息:http://ceph.com/pgcalc/#userconsent#
八:添加元数据服务器
1:添加元数据服务器
cd /etc/ceph
ceph-deploy --overwrite-conf mds create nc{1..3}
2:验证 mds 服务
[root@nc1 ceph]# ceph mds stat e1: 0/0/0 up
1:状态查看。还没有创建时候的状态。
对于一个刚创建的 MDS 服务,虽然服务是运行的,但是它的状态直到创建 pools 以及文件系统的时候才会变为
Active.
[root@nc1 ~]# ceph mds dump dumped mdsmap epoch 1
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
modified 2015-09-16 17:50:47.819163
tableserver 0
root 0
session_timeout 0
session_autoclose 0
max_file_size 0
last_failure 0
last_failure_osd_epoch 0
compat compat={},rocompat={},incompat={} max_mds 0
。。。。。。。。。。。。。。。。。。。。。。
metadata_pool 0 inline_data disabled
2:通过下面的操作创建 Filesystem
[root@nc1 ~]# ceph osd pool create cephfs_data 3048 pool 'cephfs_data' created
[root@nc1 ~]# ceph osd pool create cephfs_metadata 3048 pool 'cephfs_metadata' created
[root@nc1 ~]# ceph fs new leadorfs cephfs_metadata cephfs_data new fs with metadata pool 3 and data pool 2
3:成功创建后,mds stat 的状态如下
[root@nc1 ~]# ceph mds stat
e6: 1/1/1 up {0=nc3=up:active}, 2 up:standby
4:ceph mds dump 状态如下
[root@nc1 ~]# ceph mds dump dumped mdsmap epoch 6 epoch 6
flags 0
created 2015-09-17 12:42:58.682991
modified 2015-09-17 12:43:01.863274
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
last_failure 0
last_failure_osd_epoch 0
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table}
max_mds 1
in 0
up {0=4598}
failed stopped
data_pools 2
metadata_pool 3
inline_data disabled
3:删除 mds 节点
如果你不需要 cephfs,MDS 就成了多余的,或者配置过多的 mds 服务,为了提高性能,可以把 MDS 卸载掉。关闭 mds 服务
/etc/init.d/ceph stop mds.cs7
删除 mds 节点
ceph mds rm 1 mds.cs7
卸载
Yum remove ceph-fuse ceph-mds libcephfs1 -y
4:同步集群配置文件
把生成的配置文件从 ceph-deploy 同步部署到其他几个节点,使得每个节点的 ceph 配置一致:
usage: ceph-deploy
admin Push configuration and client.admin key to a remote host.
config Copy ceph.conf to/from remote host(s)
同步配置文件和 client.admin key
ceph-deploy --overwrite-conf admin nc{1..3} cs{1..9}
单独同步配置文件
ceph-deploy --overwrite-conf config push nc{1..3} cs{1..9}
九:crush 规则配置
1:ceph crush 规则介绍
Crush 规则支持类型如下; # types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
配置细节参照官网文章, 参考链接:
http://docs.openfans.org/ceph/ceph4e2d658765876863/ceph-1/ceph-storage-
cluster3010ceph5b5850a896c67fa43011/operations301064cd4f5c3011/crush-maps3010crush66205c043011
2:集群 crush 规则配置
根据业务集群服务器所在位置计划设置规则如下:3 个 rack,然后 rack1(cs1\cs2\cs3)、rack2(cs4\cs5\cs6)、rack3
(cs7\cs8\cs9)
1:创建 rack
[root@nc1 ~]# ceph osd crush add-bucket RACKA01 rack #返回结果、后面省略
[root@nc1 ~]# ceph osd crush add-bucket RACKA02 rack [root@nc1 ~]# ceph osd crush add-bucket RACKA03 rack
2:将 host 加入到 rack
[root@nc1 ~]# ceph osd crush move cs1 rack=RACKA01
moved item id -2 name 'cs1' to location {rack=RACKA01} in crush map #返回结果、后面省略[root@nc1 ~]# ceph osd crush move cs2 rack=RACKA01
[root@nc1 ~]# ceph osd crush move cs3 rack=RACKA01
[root@nc1 ~]# ceph osd crush move cs4 rack=RACKA02 [root@nc1 ~]# ceph osd crush move cs5 rack=RACKA02 [root@nc1 ~]# ceph osd crush move cs6 rack=RACKA02
[root@nc1 ~]# ceph osd crush move cs7 rack=RACKA03 [root@nc1 ~]# ceph osd crush move cs8 rack=RACKA03 [root@nc1 ~]# ceph osd crush move cs9 rack=RACKA03
验 证 host 加 入 rack: [root@nc1 ~]# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-13 54.59976 rack RACKA03
-8 18.19992 host cs7
60 1.81999 osd.60 up 1.00000 1.00000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
69 1.81999 osd.69 up 1.00000 1.00000
-9 18.19992 host cs8
70 1.81999 osd.70 up 1.00000 1.00000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
79 1.81999 osd.79 up 1.00000 1.00000
-10 18.19992 host cs9
Ptmind Ceph Cluster 安装配置文档 --康建华
80 1.81999 osd.80 up 1.00000 1.00000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
89 1.81999 osd.89 up 1.00000 1.00000
-12 54.59976 rack RACKA02
-5 18.19992 host cs4
30 1.81999 osd.30 up 1.00000 1.00000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
39 1.81999 osd.39 up 1.00000 1.00000
-6 18.19992 host cs5
40 1.81999 osd.40 up 1.00000 1.00000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
49 1.81999 osd.49 up 1.00000 1.00000
-7 18.19992 host cs6
50 1.81999 osd.50 up 1.00000 1.00000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
59 1.81999 osd.59 up 1.00000 1.00000
-11 49.82977 rack
-2 16.60992 host cs1
0 1.81999 osd.0 up 1.00000 1.00000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
9 0.23000 osd.9 up 1.00000 1.00000
-3 16.60992 host cs2
10 1.81999 osd.10 up 1.00000 1.00000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
19 0.23000 osd.19 up 1.00000 1.00000
-4 16.60992 host cs3
20 1.81999 osd.20 up 1.00000 1.00000
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
29 0.23000 osd.29 up 1.00000 1.00000
-1 0 root default
注意:手动安装的集群 osd 可能都在 host1 里面,需要先创建 host 然后,把 osd 加入到个 host,然后在加入吧 host
加入 rack。
创建 host 操作如下:
ceph osd crush add-bucket host
added bucket host01 type host to crush map #返回结果
将 osd 加入 host
ceph osd crush add osd.0 1.0 host=host01
add item id 0 name 'osd.0' weight 1 at location {host=host01} to crush map #返回结果
加入前是否需要关闭 osd,然后初始化需要验证一下。
touch /var/lib/ceph/osd/ceph-0/sysvinit
/etc/init.d/ceph start osd.0
3:修改 crushmap 信息
对于比较熟的 crush 配置比较熟悉的老手推荐使用,在线业务集群慎用。
1:把 ceph 的 crush map 导出并转换为文本格式, 先把 crush map 以二进制的形式导入到 test 文本。
ceph osd getcrushmap -o test
2:转换为可读格式:
用 crushtool 工具把 test 里的二进制数据转换成文本形式保存到 test1 文档里。
crushtool -d test -o test1
3:把重新写的 ceph crush 导入 ceph 集群把 test1 转换成二进制形式
crushtool -c test1 -o test2
把 test2 导入集群、
ceph osd setcrushmap -i test2
十:集群配置清理
##################以下操作在 ceph-deploy 节点操作:###########
部署过程中如果出现任何奇怪的问题无法解决,可以简单的删除一切从头再来:
sudo stop ceph-all 停止所有 ceph 进程
ceph-deploy uninstall [{ceph-node}] 卸载所有 ceph 程序
ceph-deploy purge [[ceph-node} [{ceph-node}] 删除 ceph 相关的包
ceph-deploy purgedata {ceph-node} [{ceph-node}] 删除 ceph 集群所有数据
ceph-deploy forgetkeys 删除 key
详细如下:
1:清理软件包
remove Ceph packages from remote hosts and purge all data. ceph-deploy purge nc{1..3} cs{1..9}
2:卸载之前挂载的 osd 磁盘
非系统使用的会被卸载(生产环境慎用)
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh root@$ip /usr/bin/umount -a;done
3:将写入分区表的分区挂载
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh root@$ip /usr/bin/mount -a;done
4:查看一下状态,仅剩余系统盘
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh root@$ip df -h;done
5:清理残余 key 文件和残余目录
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh root@$ip rm -rf /var/lib/ceph;done
6:新建安装目录
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh root@$ip mkdir -p /etc/ceph;done
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh root@$ip mkdir -p /var/lib/ceph/;done
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh root@$ip mkdir -p mkdir -p /var/lib/ceph/bootstrap- mds bootstrap-osd bootstrap-rgw mds mon osd tmp;done
7:重新部署集群
在所有节点安装 ceph 软件包 ceph-deploy install{ceph-node}[{ceph-node}...]
(注:如果已经用 yum 在每台机器上安装了 ceph,这步可省略)
ceph-deploy install nc{1..3} cs{1..9}
或者
for ip in $(cat /workspace/ceph/cephlist.txt);do echo -----$ip-----;ssh root@$ip yum -y install ceph ceph-radosgw ;done yum -y install ceph ceph-radosgw
十一:集群配置参数优化
1:配置参数优化
fsid = 973482fb-acf2-4a39-a691-3f810120b013 mon_initial_members = nc1, nc2, nc3
mon_host = 172.16.6.151,172.16.6.152,172.16.6.153
auth_cluster_required = cephx auth_service_required = cephx
auth_client_required = cephx
数据副本数,手动设置等同于 ceph osd pool set {pool-name} size {size}。osd pool default size = 3
数据最小副本数,以向客户端确认写操作。如果未达到最小值, Ceph 就不会向客户端回复已写确认。
osd pool default min size = 1
当 Ceph 存储集群开始时,Ceph 在 OS 等级(比如, 文件描述符最大的)设置 max open fds 。它帮助阻止 Ceph OSD 守护进程在文件描述符之外运行。
max open files= 131072
集群公共网络
public network = 172.16.6.0/24
集群私有网络
cluster network = 10.10.1.0/24
OSD filestore
扩展属性(XATTRs),为 XATTRS 使用 object map,EXT4 文件系统时使用,XFS 或者 btrfs 也可以使用默认:false
为 XATTR 使用对象图,使用 ext4 文件系统的时候要设置。
filestore xattr use omap = true
在一个 CRUSH 规则内用于 chooseleaf 的桶类型。用序列号而不是名字
osd crush chooseleaf type = 1
[mon]
时钟偏移
mon clock drift allowed = .50
十一:OSD 宕机后数据开始恢复时间
mon osd down out interval = 900
MON-OSD 满比,在被 OSD 进程使用之前一个硬盘可用空间大于%20,认为状态良好。
mon osd full ratio = .80
MON-OSD nearfull 率,在被 OSD 进程使用之前一个硬盘的剩余空间大于%30,认为状态良好,另集群总空间使用率大于%70,系统会告警。
mon osd nearfull ratio = .70
[osd]
osd 格式化磁盘的分区格式 xfs osd mkfs type = xfs
强制格式化
osd mkfs options xfs = -f
每个存储池默认 pg 数
osd pool default pg num = 3000
每个存储池默认 pgp 数
osd pool default pgp num = 3000
同步间隔
从日志到数据盘最大同步间隔间隔秒数,默认:5
filestore max sync interval = 15
从日志到数据盘最小同步间隔秒数,默认 0.1 filestore min sync interval = 10
队列
数据盘最大接受的操作数,超过此设置的请求会被拒绝。默认:500
filestore queue max ops = 25000
数据盘一次操作最大字节数(bytes)默认:100 << 20 filestore queue max bytes = 10485760
数据盘能够 commit 的最大操作数默认:500
filestore queue committing max ops = 5000
数据盘能够 commit 的最大字节数(bytes)100 << 20 filestore queue committing max bytes = 10485760000
最大并行文件系统操作线程数,默认 2;
filestore op threads = 32
osd journal #注意,Ceph OSD 进程在往数据盘上刷数据的过程中,是停止写操作的。
OSD 日志大小(MB)默认 5120,推荐 20000,使用 ssd 块存储日志,可以设置为 0,使用整个块。
osd journal size = 10000 #从 v0.54 起,如果日志文件是块设备,这个选项会被忽略,且使用整个块设备。
一次性写入的最大字节数(bytes)默认:10 << 20
journal max write bytes = 1073714824
journal 一次写入日志的最大数量,默认:100 journal max write entries = 10000
journal 一次性最大在队列中的操作数,默认 500
journal queue max ops = 50000
journal 一次性最大在队列中的字节数(bytes),默认:10 << 20 journal queue max bytes = 10485760000
OSD 通讯
注意:增加 osd op threads 和 disk threads 会带来额外的 CPU 开销
OSD 一次可写入的最大值(MB),默认:90
osd max write size = 512
客户端允许在内存中的最大数据(bytes),默认:500MB 默认 500 * 1024L * 1024L =524288000 osd client message size cap = 2147483648
在 Deep Scrub 时候允许读取的字节数(bytes),默认:524288
osd deep scrub stride = 131072
OSD 进程操作的线程数,设置为 0 来禁用它。增加的数量可能会增加请求的处理速率。默认:2 osd op threads = 8
OSD 密集型操作例如恢复和 Scrubbing 时的线程,默认:1
osd disk threads = 5
OSD 映射
保留 OSD Map 的缓存(MB),默认:500
osd map cache size = 1024
OSD 进程在内存中的 OSD Map 缓存(MB),默认:50 osd map cache bl size = 128
Ceph OSD xfs Mount 选项默认:rw,noatime,inode64
osd mount options xfs = rw,noexec,nodev,noatime,nodiratime,nobarrier
OSD recovery
osd 异常数据恢复启动的恢复进程数量,默认:1
osd recovery threads = 2
恢复操作优先级,它是相对 OSD 客户端 运算 优先级。取值 1-63,值越高占用资源越高,默认:10 。
osd recovery op priority = 4
同一时间内活跃的恢复请求数,更多的请求将加速复苏,但请求放置一个增加的群集上的负载。默认:15 osd recovery max active = 10
一个 OSD 允许的最大 backfills 数,默认:10
osd max backfills = 4
[client]
启用缓存 RADOS 块设备,默认:false rbd cache = true
RBD 缓存大小(以字节为单位)默认:33554432
rbd cache size = 268435456
缓存为 write-back 时允许的最大 dirty 字节数(bytes),如果为 0,使用 write-through ,默认:25165824 #Write-through:向高速 Cache 写入数据时同时也往后端慢速设备写一份,两者都写完才返回。
Write-back:向高速 Cache 写完数据后立即返回,数据不保证立即写入后端设备。给调用者的感觉是速度快,但需要额外的机制来防止掉电带来的数据不一致。
rbd cache max dirty = 134217728
在被刷新到存储盘前 dirty 数据存在缓存的时间(seconds)默认:
1 rbd cache max dirty age = 5
[mon.nc1]
host = nc1
mon data = /var/lib/ceph/mon/ceph-nc1/ mon addr = 172.16.6.151:6789
[mon.nc2]
host = nc2
mon data = /var/lib/ceph/mon/ceph-nc2/ mon addr = 172.16.6.152:6789
[mon.nc3]
host = nc3
mon data = /var/lib/ceph/mon/ceph-nc3/ mon addr = 172.16.6.153:6789
[mds.nc1]
host = nc1
mon data = /var/lib/ceph/mds/ceph-nc1/ mon addr = 172.16.6.151:6800
[mds.nc2]
host = nc2
mon data = /var/lib/ceph/mds/ceph-nc2/ mon addr = 172.16.6.152:6800
[mds.nc3]
host = nc3
mon data = /var/lib/ceph/mds/ceph-nc3/ mon addr = 172.16.6.153:6800
[osd.0]
[osd.1]
[osd.2]
[osd.3]
[osd.4]
[osd.5]
host = cs1
devs = /dev/disk/by-id/wwn-0x5000cca22df6b022-part1 osd data = /var/lib/ceph/osd/ceph-0
public addr = 172.16.6.154 cluster addr = 10.10.1.154
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a10-part1 osd journal size = 10000
host = cs1
devs = /dev/disk/by-id/wwn-0x5000cca24ec1ee58-part1 osd data = /var/lib/ceph/osd/ceph-1
public addr = 172.16.6.154 cluster addr = 10.10.1.154
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a10-part2 osd journal size = 10000
host = cs1
devs = /dev/disk/by-id/wwn-0x5000cca24ec1bfa5-part1 osd data = /var/lib/ceph/osd/ceph-2
public addr = 172.16.6.154 cluster addr = 10.10.1.154
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a10-part3 osd journal size = 10000
host = cs1
devs = /dev/disk/by-id/wwn-0x5000cca24ec1df52-part1 osd data = /var/lib/ceph/osd/ceph-3
public addr = 172.16.6.154 cluster addr = 10.10.1.154
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a10-part4 osd journal size = 10000
host = cs1
devs = /dev/disk/by-id/wwn-0x5000cca248d3e494-part1 osd data = /var/lib/ceph/osd/ceph-4
public addr = 172.16.6.154 cluster addr = 10.10.1.154
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a10-part5 osd journal size = 10000
host = cs1
devs = /dev/disk/by-id/wwn-0x5000cca248d3c153-part1 osd data = /var/lib/ceph/osd/ceph-5
public addr = 172.16.6.154 cluster addr = 10.10.1.154
[osd.6]
[osd.7]
[osd.8]
[osd.9]
[osd.10]
osd journal = /dev/disk/by-id/wwn-0x5000cca248d44fd8-part1 osd journal size = 10000
host = cs1
devs = /dev/disk/by-id/wwn-0x5000cca24ec4a9cc-part1 osd data = /var/lib/ceph/osd/ceph-6
public addr = 172.16.6.154 cluster addr = 10.10.1.154
osd journal = /dev/disk/by-id/wwn-0x5000cca248d44fd8-part2 osd journal size = 10000
host = cs1
devs = /dev/disk/by-id/wwn-0x5000cca22df5b22a-part1 osd data = /var/lib/ceph/osd/ceph-7
public addr = 172.16.6.154 cluster addr = 10.10.1.154
osd journal = /dev/disk/by-id/wwn-0x5000cca248d44fd8-part3 osd journal size = 10000
host = cs1
devs = /dev/disk/by-id/wwn-0x5000cca248d356cf-part1 osd data = /var/lib/ceph/osd/ceph-8
public addr = 172.16.6.154 cluster addr = 10.10.1.154
osd journal = /dev/disk/by-id/wwn-0x5000cca248d44fd8-part4 osd journal size = 10000
host = cs1
devs = /dev/disk/by-id/wwn-0x5002538d400259ae-part1 osd data = /var/lib/ceph/osd/ceph-9
public addr = 172.16.6.154 cluster addr = 10.10.1.154
osd journal = /dev/disk/by-id/wwn-0x5000cca248d44fd8-part5 osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5000cca22df6b03d-part1 osd data = /var/lib/ceph/osd/ceph-10
public addr = 172.16.6.155 cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5002538d40025963-part1
[osd.11]
osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5000cca24ec526bd-part1 osd data = /var/lib/ceph/osd/ceph-11
public addr = 172.16.6.155
[osd.12]
[osd.13]
[osd.14]
[osd.15]
[osd.16]
[osd.17]
cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5002538d40025963-part2 osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5000cca24ec14814-part1 osd data = /var/lib/ceph/osd/ceph-12
public addr = 172.16.6.155 cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5002538d40025963-part3 osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5000cca24ec06d75-part1 osd data = /var/lib/ceph/osd/ceph-13
public addr = 172.16.6.155 cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5002538d40025963-part4 osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5000cca24ec522ba-part1 osd data = /var/lib/ceph/osd/ceph-14
public addr = 172.16.6.155 cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5002538d40025963-part5 osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5000cca24ec54b92-part1 osd data = /var/lib/ceph/osd/ceph-15
public addr = 172.16.6.155 cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5000cca22df5b4b9-part1 osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5000cca248d2d970-part1 osd data = /var/lib/ceph/osd/ceph-16
public addr = 172.16.6.155 cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5000cca22Pdtmifn5d bCep4h bCl9ust-epr 安a装r配t2置文档
osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5000cca24ec54b99-part1 osd data = /var/lib/ceph/osd/ceph-17
[osd.18]
[osd.19]
[osd.20]
[osd.21]
[osd.22]
public addr = 172.16.6.155 cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5000cca22df5b4b9-part3 osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5000cca24ec53d45-part1 osd data = /var/lib/ceph/osd/ceph-18
public addr = 172.16.6.155 cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5000cca22df5b4b9-part4 osd journal size = 10000
host = cs2
devs = /dev/disk/by-id/wwn-0x5002538d40025a1f-part1 osd data = /var/lib/ceph/osd/ceph-19
public addr = 172.16.6.155 cluster addr = 10.10.1.155
osd journal = /dev/disk/by-id/wwn-0x5000cca22df5b4b9-part5 osd journal size = 10000
host = cs3
devs = /dev/disk/by-id/wwn-0x5000cca22df6b04e-part1 osd data = /var/lib/ceph/osd/ceph-20
public addr = 172.16.6.156 cluster addr = 10.10.1.156
osd journal = /dev/disk/by-id/wwn-0x5002538d40025879-part1 osd journal size = 10000
host = cs3
devs = /dev/disk/by-id/wwn-0x5000cca24ec51566-part1 osd data = /var/lib/ceph/osd/ceph-21
public addr = 172.16.6.156 cluster addr = 10.10.1.156
osd journal = /dev/disk/by-id/wwn-0x5002538d40025879-part2 osd journal size = 10000
host = cs3
devs = /dev/disk/by-id/wwn-0x5000cca24ec55cdd-part1 osd data = /var/lib/ceph/osd/ceph-22
public addr = 172.16.6.156
cluster addr = 10.10.1.156
[osd.23]
osd journal = /dev/disk/by-id/wwn-0x5002538d40025879-part3 osd journal size = 10000
host = cs3
devs = /dev/disk/by-id/wwn-0x5000cca22df5e40e-part1
[osd.24]
[osd.25]
[osd.26]
[osd.27]
[osd.28]
osd data = /var/lib/ceph/osd/ceph-23 public addr = 172.16.6.156
cluster addr = 10.10.1.156
osd journal = /dev/disk/by-id/wwn-0x5002538d40025879-part4 osd journal size = 10000
host = cs3
devs = /dev/disk/by-id/wwn-0x5000cca24ec53f40-part1 osd data = /var/lib/ceph/osd/ceph-24
public addr = 172.16.6.156 cluster addr = 10.10.1.156
osd journal = /dev/disk/by-id/wwn-0x5002538d40025879-part5 osd journal size = 10000
host = cs3
devs = /dev/disk/by-id/wwn-0x5000cca24ec54887-part1 osd data = /var/lib/ceph/osd/ceph-25
public addr = 172.16.6.156 cluster addr = 10.10.1.156
osd journal = /dev/disk/by-id/wwn-0x5000cca24ec531e4-part1 osd journal size = 10000
host = cs3
devs = /dev/disk/by-id/wwn-0x5000cca248d3843c-part1 osd data = /var/lib/ceph/osd/ceph-26
public addr = 172.16.6.156 cluster addr = 10.10.1.156
osd journal = /dev/disk/by-id/wwn-0x5000cca24ec531e4-part2 osd journal size = 10000
host = cs3
devs = /dev/disk/by-id/wwn-0x5000cca24ec32c79-part1 osd data = /var/lib/ceph/osd/ceph-27
public addr = 172.16.6.156 cluster addr = 10.10.1.156
osd journal = /dev/disk/by-id/wwn-0x5000cca24ec531e4-part3 osd journal size = 10000
host = cs3
devs = /dev/disk/by-id/wwn-0x5000cca24ec55cd2-part1 osd data = /var/lib/ceph/osd/ceph-28
public addr = 172.16.6.156 cluster addr = 10.10.1.156
[osd.29]
osd journal = /dev/disk/by-id/wwn-0x5000cca24ec531e4-part4 osd journal size = 10000
host = cs3
[osd.30]
[osd.31]
[osd.32]
[osd.33]
[osd.34]
devs = /dev/disk/by-id/wwn-0x5002538d4002597d-part1 osd data = /var/lib/ceph/osd/ceph-29
public addr = 172.16.6.156 cluster addr = 10.10.1.156
osd journal = /dev/disk/by-id/wwn-0x5000cca24ec531e4-part5 osd journal size = 10000
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca22df60e46-part1 osd data = /var/lib/ceph/osd/ceph-30
public addr = 172.16.6.157 cluster addr = 10.10.1.157
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0c-part1 osd journal size = 10000
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca248d302da-part1 osd data = /var/lib/ceph/osd/ceph-31
public addr = 172.16.6.157 cluster addr = 10.10.1.157
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0c-part2 osd journal size = 10000
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca24ec52b3f-part1 osd data = /var/lib/ceph/osd/ceph-32
public addr = 172.16.6.157 cluster addr = 10.10.1.157
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0c-part3 osd journal size = 10000
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca22df5b51f-part1 osd data = /var/lib/ceph/osd/ceph-33
public addr = 172.16.6.157 cluster addr = 10.10.1.157
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0c-part4 osd journal size = 10000
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca24ec1e300-part1
osd data = /var/lib/ceph/osd/ceph-34 public addr = 172.16.6.157
cluster addr = 10.10.1.157
[osd.35]
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0c-part5 osd journal size = 10000
[osd.36]
[osd.37]
[osd.38]
[osd.39]
[osd.40]
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca248d44fb4-part1 osd data = /var/lib/ceph/osd/ceph-35
public addr = 172.16.6.157 cluster addr = 10.10.1.157
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a1c-part1 osd journal size = 10000
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca24ec521fd-part1 osd data = /var/lib/ceph/osd/ceph-36
public addr = 172.16.6.157 cluster addr = 10.10.1.157
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a1c-part2 osd journal size = 10000
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca22df5b539-part1 osd data = /var/lib/ceph/osd/ceph-37
public addr = 172.16.6.157 cluster addr = 10.10.1.157
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a1c-part3 osd journal size = 10000
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca248d385eb-part1 osd data = /var/lib/ceph/osd/ceph-38
public addr = 172.16.6.157 cluster addr = 10.10.1.157
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a1c-part4 osd journal size = 10000
host = cs4
devs = /dev/disk/by-id/wwn-0x5000cca24ec1ed9a-part1 osd data = /var/lib/ceph/osd/ceph-39
public addr = 172.16.6.157 cluster addr = 10.10.1.157
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a1c-part5 osd journal size = 10000
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca22df5e58Ptemi-ndpCaeprh tC1luster 安装配置文档
osd data = /var/lib/ceph/osd/ceph-40 public addr = 172.16.6.158
cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d400259ba-part1 osd journal size = 10000
[osd.41]
[osd.42]
[osd.43]
[osd.44]
[osd.45]
[osd.46]
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca22df5b53c-part1 osd data = /var/lib/ceph/osd/ceph-41
public addr = 172.16.6.158 cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d400259ba-part2 osd journal size = 10000
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca24ec5485f-part1 osd data = /var/lib/ceph/osd/ceph-42
public addr = 172.16.6.158 cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d400259ba-part3 osd journal size = 10000
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca24ec541a3-part1 osd data = /var/lib/ceph/osd/ceph-43
public addr = 172.16.6.158 cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d400259ba-part4 osd journal size = 10000
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca24ec56029-part1 osd data = /var/lib/ceph/osd/ceph-44
public addr = 172.16.6.158 cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d400259ba-part5 osd journal size = 10000
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca22df5e3f3-part1 osd data = /var/lib/ceph/osd/ceph-45
public addr = 172.16.6.158 cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0d-part1 osd journal size = 10000
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca22df5b5cc-part1 osd data = /var/lib/ceph/osd/ceph-46
public addr = 172.16.6.158 cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0d-part2
[osd.47]
[osd.48]
[osd.49]
[osd.50]
[osd51]
[osd.52]
osd journal size = 10000
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca24ec5483d-part1 osd data = /var/lib/ceph/osd/ceph-47
public addr = 172.16.6.158 cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0d-part3 osd journal size = 10000
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca248d38106-part1 osd data = /var/lib/ceph/osd/ceph-48
public addr = 172.16.6.158 cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0d-part4 osd journal size = 10000
host = cs5
devs = /dev/disk/by-id/wwn-0x5000cca24ec5304f-part1 osd data = /var/lib/ceph/osd/ceph-49
public addr = 172.16.6.158 cluster addr = 10.10.1.158
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a0d-part5 osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca24ec0c263-part1 osd data = /var/lib/ceph/osd/ceph-50
public addr = 172.16.6.159 cluster addr = 10.10.1.159
osd journal = /dev/disk/by-id/wwn-0x5002538d40025978-part1 osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca22df5e3f2-part1 osd data = /var/lib/ceph/osd/ceph-51
public addr = 172.16.6.159 cluster addr = 10.10.1.159
osd journal = /dev/disk/by-id/wwn-0x5002538d40025978-part2 osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca248d3a0c7-part1 osd data = /var/lib/ceph/osd/ceph-52
public addr = 172.16.6.159 cluster addr = 10.10.1.159
[osd.53]
[osd.54]
[osd.55]
[osd.56]
[osd.57]
osd journal = /dev/disk/by-id/wwn-0x5002538d40025978-part3 osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca248d384fa-part1 osd data = /var/lib/ceph/osd/ceph-53
public addr = 172.16.6.159 cluster addr = 10.10.1.159
osd journal = /dev/disk/by-id/wwn-0x5002538d40025978-part4 osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca22df5b494-part1 osd data = /var/lib/ceph/osd/ceph-54
public addr = 172.16.6.159 cluster addr = 10.10.1.159
osd journal = /dev/disk/by-id/wwn-0x5002538d40025978-part5 osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca24ec547d0-part1 osd data = /var/lib/ceph/osd/ceph-55
public addr = 172.16.6.159 cluster addr = 10.10.1.159
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597e-part1 osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca22df5362d-part1 osd data = /var/lib/ceph/osd/ceph-56
public addr = 172.16.6.159 cluster addr = 10.10.1.159
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597e-part2 osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca24ec55daa-part1 osd data = /var/lib/ceph/osd/ceph-57
public addr = 172.16.6.159 cluster addr = 10.10.1.159
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597e-part3
[osd.58]
osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca24ec50cbe-part1 osd data = /var/lib/ceph/osd/ceph-58
public addr = 172.16.6.159
[osd.59]
[osd.60]
[osd.61]
[osd.62]
[osd.63]
[osd.64]
cluster addr = 10.10.1.159
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597e-part4 osd journal size = 10000
host = cs6
devs = /dev/disk/by-id/wwn-0x5000cca248d457a2-part1 osd data = /var/lib/ceph/osd/ceph-59
public addr = 172.16.6.159 cluster addr = 10.10.1.159
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597e-part5 osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca24ec1dece-part1 osd data = /var/lib/ceph/osd/ceph-60
public addr = 172.16.6.160 cluster addr = 10.10.1.160
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a1e-part1 osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca24ec06226-part1 osd data = /var/lib/ceph/osd/ceph-61
public addr = 172.16.6.160 cluster addr = 10.10.1.160
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a1e-part2 osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca24ec0816f-part1 osd data = /var/lib/ceph/osd/ceph-62
public addr = 172.16.6.160 cluster addr = 10.10.1.160
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a1e-part3 osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca24ec546a4-part1 osd data = /var/lib/ceph/osd/ceph-63
public addr = 172.16.6.160 cluster addr = 10.10.1.160
osd journal = /dev/disk/by-id/wwn-0x5002538d4Pt0min0d 2Ce5phaCl1usete-rp安a装r配t置4文档
osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca24ec554c5-part1 osd data = /var/lib/ceph/osd/ceph-64
[osd.65]
[osd.66]
[osd.67]
[osd.68]
[osd.69]
public addr = 172.16.6.160 cluster addr = 10.10.1.160
osd journal = /dev/disk/by-id/wwn-0x5002538d40025a1e-part5 osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca22df5e747-part1 osd data = /var/lib/ceph/osd/ceph-65
public addr = 172.16.6.160 cluster addr = 10.10.1.160
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597c-part1 osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca248d3e5f1-part1 osd data = /var/lib/ceph/osd/ceph-66
public addr = 172.16.6.160 cluster addr = 10.10.1.160
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597c-part2 osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca22df5e574-part1 osd data = /var/lib/ceph/osd/ceph-67
public addr = 172.16.6.160 cluster addr = 10.10.1.160
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597c-part3 osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca24ec49ccd-part1 osd data = /var/lib/ceph/osd/ceph-68
public addr = 172.16.6.160 cluster addr = 10.10.1.160
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597c-part4 osd journal size = 10000
host = cs7
devs = /dev/disk/by-id/wwn-0x5000cca24ec5278f-part1 osd data = /var/lib/ceph/osd/ceph-69
public addr = 172.16.6.160
cluster addr = 10.10.1.160
[osd.70]
osd journal = /dev/disk/by-id/wwn-0x5002538d4002597c-part5 osd journal size = 10000
host = cs8
devs = /dev/disk/by-id/wwn-0x5000cca248d383b4-part1
[osd.71]
[osd.72]
[osd.73]
[osd.74]
[osd.75]
osd data = /var/lib/ceph/osd/ceph-70 public addr = 172.16.6.161
cluster addr = 10.10.1.161
osd journal = /dev/disk/by-id/wwn-0x5002538d4002595e-part1 osd journal size = 10000
host = cs8
devs = /dev/disk/by-id/wwn-0x5000cca24ec52fbb-part1 osd data = /var/lib/ceph/osd/ceph-71
public addr = 172.16.6.161 cluster addr = 10.10.1.161
osd journal = /dev/disk/by-id/wwn-0x5002538d4002595e-part2 osd journal size = 10000
host = cs8
devs = /dev/disk/by-id/wwn-0x5000cca24ec51614-part1 osd data = /var/lib/ceph/osd/ceph-72
public addr = 172.16.6.161 cluster addr = 10.10.1.161
osd journal = /dev/disk/by-id/wwn-0x5002538d4002595e-part3 osd journal size = 10000
host = cs8
devs = /dev/disk/by-id/wwn-0x5000cca248d41aa1-part1 osd data = /var/lib/ceph/osd/ceph-73
public addr = 172.16.6.161 cluster addr = 10.10.1.161
osd journal = /dev/disk/by-id/wwn-0x5002538d4002595e-part4 osd journal size = 10000
host = cs8
devs = /dev/disk/by-id/wwn-0x5000cca22df5e4ba-part1 osd data = /var/lib/ceph/osd/ceph-74
public addr = 172.16.6.161 cluster addr = 10.10.1.161
osd journal = /dev/disk/by-id/wwn-0x5002538d4002595e-part5 osd journal size = 10000
host = cs8
devs = /dev/disk/by-id/wwn-0x5000cca24ec4afbf-part1 osd data = /var/lib/ceph/osd/ceph-75
public addr = 172.16.6.161 cluster addr = 10.10.1.161
[osd.76]
osd journal = /dev/disk/by-id/wwn-0x5002538d40025977-part1 osd journal size = 10000
host = cs8
[osd.77]
[osd.78]
[osd.79]
[osd.80]
[osd.81]
devs = /dev/disk/by-id/wwn-0x5000cca24ec1df2e-part1 osd data = /var/lib/ceph/osd/ceph-76
public addr = 172.16.6.161 cluster addr = 10.10.1.161
osd journal = /dev/disk/by-id/wwn-0x5002538d40025977-part2 osd journal size = 10000
host = cs8
devs = /dev/disk/by-id/wwn-0x5000cca248d3123b-part1 osd data = /var/lib/ceph/osd/ceph-77
public addr = 172.16.6.161 cluster addr = 10.10.1.161
osd journal = /dev/disk/by-id/wwn-0x5002538d40025977-part3 osd journal size = 10000
host = cs8
devs = /dev/disk/by-id/wwn-0x5000cca24ec55ce5-part1 osd data = /var/lib/ceph/osd/ceph-78
public addr = 172.16.6.161 cluster addr = 10.10.1.161
osd journal = /dev/disk/by-id/wwn-0x5002538d40025977-part4 osd journal size = 10000
host = cs8
devs = /dev/disk/by-id/wwn-0x5000cca22df5b53f-part1 osd data = /var/lib/ceph/osd/ceph-79
public addr = 172.16.6.161 cluster addr = 10.10.1.161
osd journal = /dev/disk/by-id/wwn-0x5002538d40025977-part5 osd journal size = 10000
host = cs9
devs = /dev/disk/by-id/wwn-0x5000cca22df5b51c-part1 osd data = /var/lib/ceph/osd/ceph-80
public addr = 172.16.6.162 cluster addr = 10.10.1.162
osd journal = /dev/disk/by-id/wwn-0x5002538d400259cc-part1 osd journal size = 10000
host = cs9
devs = /dev/disk/by-id/wwn-0x5000cca24ec55cc9-part1
osd data = /var/lib/ceph/osd/ceph-81 public addr = 172.16.6.162
cluster addr = 10.10.1.162
[osd.82]
osd journal = /dev/disk/by-id/wwn-0x5002538d400259cc-part2 osd journal size = 10000
[osd.83]
[osd.84]
[osd.85]
[osd.86]
[osd.87]
host = cs9
devs = /dev/disk/by-id/wwn-0x5000cca248d3522c-part1 osd data = /var/lib/ceph/osd/ceph-82
public addr = 172.16.6.162 cluster addr = 10.10.1.162
osd journal = /dev/disk/by-id/wwn-0x5002538d400259cc-part3 osd journal size = 10000
host = cs9
devs = /dev/disk/by-id/wwn-0x5000cca24ec51fb3-part1 osd data = /var/lib/ceph/osd/ceph-83
public addr = 172.16.6.162 cluster addr = 10.10.1.162
osd journal = /dev/disk/by-id/wwn-0x5002538d400259cc-part4 osd journal size = 10000
host = cs9
devs = /dev/disk/by-id/wwn-0x5000cca248d3e241-part1 osd data = /var/lib/ceph/osd/ceph-84
public addr = 172.16.6.162 cluster addr = 10.10.1.162
osd journal = /dev/disk/by-id/wwn-0x5002538d400259cc-part5 osd journal size = 10000
host = cs9
devs = /dev/disk/by-id/wwn-0x5000cca24ec54b9d-part1 osd data = /var/lib/ceph/osd/ceph-85
public addr = 172.16.6.162 cluster addr = 10.10.1.162
osd journal = /dev/disk/by-id/wwn-0x5002538d400259c2-part1 osd journal size = 10000
host = cs9
devs = /dev/disk/by-id/wwn-0x5000cca22df5e6d5-part1 osd data = /var/lib/ceph/osd/ceph-86
public addr = 172.16.6.162 cluster addr = 10.10.1.162
osd journal = /dev/disk/by-id/wwn-0x5002538d400259c2-part2 osd journal size = 10000
host = cs9
osd data = /var/lib/ceph/osd/ceph-87 public addr = 172.16.6.162
cluster addr = 10.10.1.162
osd journal = /dev/disk/by-id/wwn-0x5002538d400259c2-part3 osd journal size = 10000
[osd.88]
[osd.89]
host = cs9
devs = /dev/disk/by-id/wwn-0x5000cca24ec546ae-part1 osd data = /var/lib/ceph/osd/ceph-88
public addr = 172.16.6.162 cluster addr = 10.10.1.162
osd journal = /dev/disk/by-id/wwn-0x5002538d400259c2-part4 osd journal size = 10000
host = cs9
devs = /dev/disk/by-id/wwn-0x5000cca24ec54883-part1 osd data = /var/lib/ceph/osd/ceph-89
public addr = 172.16.6.162 cluster addr = 10.10.1.162
osd journal = /dev/disk/by-id/wwn-0x5002538d400259c2-part5 osd journal size = 10000
2:同步集群配置文件
把生成的配置文件从 ceph-deploy 同步部署到其他几个节点,使得每个节点的 ceph 配置一致:
usage: ceph-deploy
admin Push configuration and client.admin key to a remote host.
config Copy ceph.conf to/from remote host(s)
同步配置文件和 client.admin key
ceph-deploy --overwrite-conf admin nc{1..3} cs{1..9}
单独同步配置文件
ceph-deploy --overwrite-conf config push nc{1..3} cs{1..9}
十二:ceph 集群启动、重启、停止
1:ceph 命令的选项
ceph 命令的选项如下: 选项 简写 描述
--verbose -v 详细的日志。
--valgrind N/A (只适合开发者和质检人员)用 Valgrind 调试。
--allhosts -a 在 ceph.conf 里配置的所有主机上执行,Ptm否ind Ce则ph Cl它uste只r 安装在配置本文档机--执行 。
--restart N/A 核心转储后自动重启。
--norestart N/A 核心转储后不自动重启。
--conf -c 使用另外一个配置文件。
Ceph 子命令包括:
命令 描述
start 启动守护进程。
stop 停止守护进程。
forcestop 暴力停止守护进程,等价于 kill -9
killall 杀死某一类守护进程。
cleanlogs 清理掉日志目录。
cleanalllogs 清理掉日志目录内的所有文件。
2:启动所有守护进程
要启动、关闭、重启 Ceph 集群,执行 ceph 时加上 相关命令,语法如下:
/etc/init.d/ceph [options] [start|restart|stop] [daemonType|daemonID]
下面是个典型启动实例:
sudo /etc/init.d/ceph -a start
加 -a (即在所有节点上执行)执行完成后 Ceph 本节点所有进程启动。
把 CEPH 当服务运行,按此语法:
service ceph [options] [start|restart] [daemonType|daemonID]
典型实例:
service ceph -a start
3:启动单一实例
要启动、关闭、重启一类守护进程 本例以要启动本节点上某一类的所有 Ceph 守护进程,
/etc/init.d/ceph [start|restart|stop] [daemonType|daemonID]
/etc/init.d/ceph start osd.0
把 ceph 当做服务运行,启动一节点上某个 Ceph 守护进程, 按此语法:
service ceph sta
十三:维护常用命令
1:检查集群健康状况
1:检查集群健康状况
启动集群后、读写数据前,先检查下集群的健康状态。你可以用下面的命令检查:
ceph health 或者 ceph health detail (输出信息更详细)
要观察集群内正发生的事件,打开一个新终端,然后输入:
ceph -w
输出信息里包含: 集群唯一标识符 集群健康状况
监视器图元版本和监视器法定人数状态
OSD 版本和 OSD 状态摘要
其内存储的数据和对象数量的粗略统计,以及数据总量等。新版本新增选项如下:
-s, --status show cluster status
-w, --watch watch live cluster changes
--watch-debug watch debug events
--watch-info watch info events
--watch-sec watch security events
--watch-warn watch warn events
--watch-error watch error events
--version, -v display version
--verbose make verbose
--concise make less verbose
使用方法演示:
ceph -w --watch-info
2:检查集群的使用情况
检查集群的数据用量及其在存储池内的分布情况,可以用 df 选项,它和 Linux 上的 df 相似。如下:
ceph df
输出的 GLOBAL 段展示了数据所占用集群存储空间的概要。
SIZE: 集群的总容量;
AVAIL: 集群的空闲空间总量;
RAW USED: 已用存储空间总量;
% RAW USED: 已用存储空间比率。用此值参照 full ratio 和 near full \ ratio 来确保不会用尽集群空间。详情见存储容量。
输出的 POOLS 段展示了存储池列表及各存储池的大致使用率。没有副本、克隆品和快照占用情况。例如,如果你把 1MB 的数据存储为对象,理论使用率将是 1MB ,但考虑到副本数、克隆数、和快照数,实际使用率可能是 2MB 或更多。
NAME: 存储池名字;
ID: 存储池唯一标识符;
USED: 大概数据量,单位为 KB 、 MB 或 GB ;
%USED: 各存储池的大概使用率;
Objects: 各存储池内的大概对象数。
新版本新增 ceph osd df 命令,可以详细列出集群每块磁盘的使用情况,包括大小、权重、使用多少空间、使用率等等
3:检查集群状态
要检查集群的状态,执行下面的命令:
ceph status
4:检查 MONITOR 状态
查看监视器图,执行下面的命令:
ceph mon stat
或者:
ceph mon dump
要检查监视器的法定人数状态,执行下面的命令:
ceph quorum_status
5:检查 MDS 状态:
元数据服务器为 Ceph 文件系统提供元数据服务,元数据服务器有两种状态: up | \ down 和 active | inactive , 执行下面的命令查看元数据服务器状态为 up 且 active :
ceph mds stat
要展示元数据集群的详细状态,执行下面的命令:
ceph mds dump
删除一个 mds 节点
ceph mds rm 0 mds.nc3
十四:集群命令详解
1:mon 相关
1:查看 mon 的状态信息
[mon@ptmind~]# ceph mon stat
2:查看 mon 的选举状态
[mon@ptmind~]# ceph quorum_status
3:查看 mon 的映射信息
[mon@ptmind~]# ceph mon dump
4:删除一个 mon 节点
[mon@ptmind~]# ceph mon remove cs1
5:获得一个正在运行的 mon map,并保存在 1.txt 文件中
[mon@ptmind~]# ceph mon getmap -o 1.txt
6: 读 取 上 面 获 得 的 map
[mon@ptmind~]# monmaptool --print 1.txt
7:把上面的 mon map 注入新加入的节点
[mon@ptmind~]# ceph-mon -i nc3 --inject-monmap 1.txt
8:查看 mon 的 amin socket
[mon@ptmind~]# ceph-conf --name mon.nc3 --show-config-value admin_socket
9:查看 ceph mon log 日志所在的目录
[mon@ptmind~]# ceph-conf --name mon.nc1 --show-config-value log_file
/var/log/ceph/ceph-mon.nc1.log
10:查看一个集群 ceph-mon.nc3 参数的配置、输出信息特别详细,集群所有配置生效可以在此参数下确认
[mon@ptmind~]# ceph --admin-daemon /var/run/ceph/ceph-mon.nc3.asok config show | less
2: msd 相 关
1:查看 msd 状态
[mon@ptmind~]# ceph mds stat
2:删除一个 mds 节点
[mon@ptmind~]# ceph mds rm 0 mds.nc1
3:设置 mds 状态为失败
[mon@ptmind~]# ceph mds rmfailed <int[0-]>
4:新建 pool
[mon@ptmind~]# ceph mds add_data_pool <poolname>
5:关闭 mds 集群
[mon@ptmind~]# mds cluster_down
6:启动 mds 集群
[mon@ptmind~]# mds cluster_up
7:设置 cephfs 文件系统存储方式最大单个文件尺寸
[mon@ptmind~]# ceph mds set max_file_size 1024000000000
8:清除 cephfs 文件系统步骤
强 制 mds 状 态 为 featrue
[mon@ptmind~]# ceph mds fail 0
删除 mds 文件系统
[mon@ptmind~]# ceph fs rm leadorfs --yes-i-really-mean-it
删除 fs 数据文件夹
[mon@ptmind~]# ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it #删除元数据文件夹
[mon@ptmind~]# ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
然后再删除 mds key ,残留文件等
拆除文件系统前推荐先删除节点,待验证
[mon@ptmind~]# ceph mds rm 0 mds.node242
4:ceph auth 相关
1:查看 ceph 集群中的认证用户及相关的 key
[mon@ptmind~]# ceph auth list
2:为 ceph 创建一个 admin 用户并为 admin 用户创建一个密钥,把密钥保存到/etc/ceph 目录下:
[mon@ptmind~]# ceph auth get-or-create client.admin mds 'allow' osd 'allow *' mon 'allow *' >
/etc/ceph/ceph.client.admin.keyring
或
[mon@ptmind~]# ceph auth get-or-create client.admin mds 'allow' osd 'allow *' mon 'allow *' -o
/etc/ceph/ceph.client.admin.keyring
3:为 osd.0 创建一个用户并创建一个 key
[mon@ptmind~]# ceph auth get-or-create osd.0 mon 'allow rwx' osd 'allow *' -o /var/lib/ceph/osd/ceph-0/keyring
4:为 mds.nc3 创建一个用户并创建一个 key
[mon@ptmind~]# ceph auth get-or-create mds.nc3 mon 'allow rwx' osd 'allow *' mds 'allow *' -o /var/lib/ceph/mds/ceph- cs1/keyring
5:导入 key 信息
[mon@ptmind~]# ceph auth import /var/lib/ceph/mds/ceph-cs1/keyring
6:删除集群中的一个认证用户
[mon@ptmind~]# ceph auth del osd.0
5:osd 相关
1:查看 osd 列表
[mon@ptmind~]# ceph osd tree
2:查看数据延迟
[mon@ptmind~]# ceph osd perf
osd fs_commit_latency(ms) fs_apply_latency(ms)
0 3 4
1 333 871
2 33 49
3 1 2
。。。。。。。。。。。。
3:详细列出集群每块磁盘的使用情况,包括大小、权重、使用多少空间、使用率等等
[mon@ptmind~]# ceph osd df
4:down 掉一个 osd 硬盘
[mon@ptmind~]# ceph osd down 0 #down 掉 osd.0 节点
5:在集群中删除一个 osd 硬盘
[mon@ptmind~]# ceph osd rm 0
6:在集群中删除一个 osd 硬盘 crush map
[mon@ptmind~]# ceph osd crush rm osd.0
7:在集群中删除一个 osd 的 host 节点
[mon@ptmind~]# ceph osd crush rm cs1
8:查看最大 osd 的个数
[mon@ptmind~]# ceph osd getmaxosd
max_osd = 90 in epoch 1202 #默认最大是 90 个 osd 节点
9:设置最大的 osd 的个数(当扩大 osd 节点的时候必须扩大这个值)
[mon@ptmind~]# ceph osd setmaxosd 2048
10:设置 osd crush 的权重为 1.0
ceph osd crush set {id} {weight} [{loc1} [{loc2} ...]]
例如:
[mon@ptmind~]# ceph osd crush set osd.1 0.5 host=node241
11:设置 osd 的权重
[mon@ptmind~]# ceph osd reweight 3 0.5
reweighted osd.3 to 0.5 (8327682)
或者用下面的方式
[mon@ptmind~]# ceph osd crush reweight osd.1 1.0
12:把一个 osd 节点逐出集群
[mon@ptmind~]# ceph osd out osd.3:
3 1 osd.3 up 0 # osd.3 的 rewPetmiingd hCetph 变Clus为ter 安0装配了置文就档不再分配数据,但是设备还是存活的
13:把逐出的 osd 加入集群
[mon@ptmind~]# ceph osd in osd.3 marked in osd.3.
14:暂停 osd (暂停后整个集群不再接收数据)
[mon@ptmind~]# ceph osd pause
15:再次开启 osd (开启后再次接收数据)
[mon@ptmind~]# ceph osd unpause
16:查看一个集群 osd.0 参数的配置、输出信息特别详细,集群所有配置生效可以在此参数下确认
[mon@ptmind~]# ceph --admin-daemon /var/run/ceph/ceph-osd.0.asok config show | less
17:设置标志 flags ,不允许关闭 osd、解决网络不稳定,osd 状态不断切换的问题
[mon@ptmind~]# ceph osd set nodown
取消设置
[mon@ptmind~]# ceph osd unset nodown
6:pool 相关
1:查看 ceph 集群中的 pool 数量
[mon@ptmind~]# ceph osd lspools 或者 ceph osd pool ls
2:在 ceph 集群中创建一个 pool
[mon@ptmind~]# ceph osd pool create rbdtest 100 #这里的 100 指的是 PG 组:
3:查看集群中所有 pool 的副本尺寸
[mon@ptmind~]# ceph osd dump | grep 'replicated size'
4:查看 pool 最大副本数量
[mon@ptmind~]# ceph osd pool get rbdpool size size: 3
5:查看 pool 最小副本数量
[root@node241 ~]# ceph osd pool get rbdpool min_size min_size: 2
6:设置一个 pool 的 pg 数量
[mon@ptmind~]# ceph osd pool set rbdtest pg_num 100
7:设置一个 pool 的 pgp 数量
[mon@ptmind~]# ceph osd pool set rbdtest pgp_num 100
8: 修改 ceph,数据最小副本数、和副本数
ceph osd pool set $pool_name min_size 1
ceph osd pool set $pool_name size 2
示例:
[mon@ptmind~]# ceph osd pool set rbdpool min_size 1 [mon@ptmind~]# ceph osd pool set rbdpool size 2
验证:
[mon@ptmind~]# ceph osd dump
pool 3 'rbdpool' replicated size 2 min_size 1
9:设置 rbdtest 池的最大存储空间为 100T(默认是 1T)
[mon@ptmind~]# ceph osd pool set rbdtest target_max_bytes 100000000000000
10: 为一个 ceph pool 配置配额、达到配额前集群会告警,达到上限后无法再写入数据
[mon@ptmind~]# ceph osd pool set-quota rbdtest max_objects 10000
11: 在集群中删除一个 pool,注意删除 poolpool 映射的 image 会直接被删除,线上操作要谨慎。
[mon@ptmind~]# ceph osd pool delete rbdtest rbdtest --yes-i-really-really-mean-it #集群名字需要重复两次
12: 给一个 pool 创建一个快照
[mon@ptmind~]# ceph osd pool mksnap rbdtest rbdtest-snap20150924
13: 查看快照信息
[mon@ptmind~]# rados lssnap -p rbdtest
1 rbdtest-snap20150924 2015.09.24 19:58:55
2 rbdtest-snap2015092401 2015.09.24 20:31:21
2 snaps
14:删除 pool 的快照
[mon@ptmind~]# ceph osd pool rmsnap rbdtest rbdtest-snap20150924
验证,剩余一个 snap
[mon@ptmind~]# rados lssnap -p rbdtest
2 rbdtest-snap2015092401 2015.09.24 20:31:21
1 snaps
7:rados 命令相关
是和 的对象存储集群( ), 的分布式文件系统的一部分进行交互是一种实用工具。
1: 查 看 ceph 集 群 中 有 多 少 个 pool ( 只 是 查 看 pool)
[mon@ptmind~]# rados lspools 同 ceph osd pool ls 输出结果一致
2:显示整个系统和被池毁掉的使用率统计,包括磁盘使用(字节)和对象计数
[mon@ptmind~]# rados df
3:创建一个 pool
[mon@ptmind~]# rados mkpool test
4:创建一个对象 object
[mon@ptmind~]# rados create test-object -p test
5:查看对象文件
[mon@ptmind~]# rados -p test ls
test-object
6:删除一个对象
[mon@ptmind~]# rados rm test-object-1 -p test
7:删除 foo 池 (和它所有的数据)
[mon@ptmind~]# rados rmpool test test –yes-i-really-really-mean-it
8:查看 ceph pool 中的 ceph object (这里的 object 是以块形式存储的)
[mon@ptmind~]# rados ls -p test | more
9:为 test pool 创建快照
[mon@ptmind~]# rados -p test mksnap testsnap created pool test snap testsnap
10:列出给定池的快照
[mon@ptmind~]# rados -p test lssnap
1 testsnap 2015.09.24 21:14:34
11:删除快照
[mon@ptmind~]# rados -p test rmsnap testsnap removed pool test snap testsnap
12:上传一个对象到 test pool
[mon@ptmind~]# rados -p test put myobject blah.txt
13:使用 rados 进行性能测试
测试用例如下:
rados bench 600 write rand -t 100 -b 4K -p datapool
选项解释: 测试时间 :600
支持测试类型:write/read ,加 rand 就是随机,不加就是顺序
并发数( -t 选项):100
pool 的名字是:datapool
8:PG 相关
PG =“放置组”。当集群中的数据,对象映射到编程器,被映射到这些 PGS 的 OSD。
1:查看 pg 组的映射信息
[mon@ptmind~]# ceph pg dump 或 者 ceph pg ls
2: 查 看 一 个 PG 的 map
[mon@ptmind~]# ceph pg map 0.3f
osdmap e88 pg 0.3f (0.3f) -> up [0,2] acting [0,2] #其中的[0,2]代表存储在 osd.0、osd.2 节点,osd.0 代表主副本的存储位置
3:查看 PG 状态
[mon@ptmind~]# ceph pg stat
4:查询一个 pg 的详细信息
[mon@ptmind~]# ceph pg 0.26 query
5:要洗刷一个 pg 组,执行命令:
[mon@ptmind~]# ceph pg scrub {pg-id}
6:查看 pg 中 stuck 的状态
要获取所有卡在某状态的归置组统计信息,执行命令:
ceph pg dump_stuck inactive|unclean|stale [--format <format>] [-t|--threshold <seconds>]
[mon@ptmind~]# ceph pg dump_stuck unclean [mon@ptmind~]# ceph pg dump_stuck inactive [mon@ptmind~]# ceph pg dump_stuck stale
Inactive (不活跃)归置组不能处理读写,因为它们在等待一个有最新数据的 OSD 复活且进入集群。
Unclean (不干净)归置组含有复制数未达到期望数量的对象,它们应该在恢复中。
Stale (不新鲜)归置组处于未知状态:存储它们的 OSD 有段时间没向监视器报告了(由 mon_osd_report_timeout
配置)。
可用格式有 plain (默认)和 json 。阀值定义的是,归置组被认为卡住前等待的最小时间(默认 300 秒)
7:显示一个集群中的所有的 pg 统计
[mon@ptmind~]# ceph pg dump --format plain
8:恢复一个丢失的 pg
如果集群丢了一个或多个对象,而且必须放弃搜索这些数据,你就要把未找到的对象标记为丢失( lost )。
如果所有可能的位置都查询过了,而仍找不到这些对象,你也许得放弃它们了。这可能是罕见的失败组合导致的, 集群在写入完成前,未能得知写入是否已执行。
当前只支持 revert 选项,它使得回滚到对象的前一个版本(如果它是新对象)或完全忽略它。要把 unfound 对象标记为 lost ,执行命令:
ceph pg {pg-id} mark_unfound_lost revert|delete
9:查看某个 PG 内分布的数据状态,具体状态可以使用选项过滤输出
ceph pg ls {<int>}
{active|clean|down|replay|splitting|scrubbing|scrubq|degraded|inconsistent|peering|repair|recovering|backfill_wait|i ncomplete|stale|remapped|deep_scrub|backfill|
backfill_toofull|recovery_wait|undersized [active|clean|down|replay|splitting|scrubbing|scrubq|degraded|inconsistent|peering|repair|recovering|backfill_wait|i ncomplete|stale|remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|undersized...]} : list pg with specific pool, osd, state
实例如下:
pg 号 过滤输出的状态
[mon@ptmind~]# ceph pg ls 1 clean
10:查询 osd 包含 pg 的信息,过滤输出 pg 的状态信息
pg ls-by-osd <osdname (id|osd.id)> list pg on osd [osd]
{<int>} {active|clean|down|replay|splitting|scrubbing|scrubq|degraded| inconsistent|peering|repair|recovering|
backfill_wait|incomplete|stale|remapped|deep_scrub|backfill|backfill_toofull|recovery_wait|undersized[active|clean|d own|replay|splitting|
scrubbing|scrubq|degraded|inconsistent| peering|repair|recovering|backfill_ wait|incomplete|stale|remapped|deep_scrub|backfill|backfill_toofull|recovery_wait|undersized...]}
实例如下:
[mon@ptmind~]# ceph pg ls-by-osd osd.5
11:查询 pool 包含 pg 的信息,过滤输出 pg 的状态信息
ceph pg ls-by-pool poolname 选项
ceph pg ls-by-pool
实例如下:
[mon@ptmind~]# ceph pg ls-by-pool test
12:查询某个 osd 状态为 primary pg ,可以根据需要过滤状态
pg ls-by-primary <osdname (id|osd.id)> {
{active|clean|down|replay|splitting|scrubbing|scrubq|dePtgmirndaCdepeh dClu|stienr 安co装配n置s文is档ten--t|peering|repair|recovering|backfill_wait|i ncomplete|stale|remapped|deep_scrub|backfill|
backfill_toofull|recovery_wait|undersized [active|clean|down|replay|splitting|scrubbing|scrubq|degraded|inconsistent|peering|repair|recovering|backfill_wait|i ncomplete|stale|remapped|deep_scrub|backfill|
backfill_toofull|recovery_wait|undersized...]} : list pg with primary = [osd]
实例如下:
osd 号 过滤输出的状态
[mon@ptmind~]# ceph pg ls-by-primary osd.3 clean
9: rbd 命令相关
1:在 test 池中创建一个命名为 kjh 的 10000M 的镜像
[mon@ptmind~]# rbd create -p test --size 10000 kjh
2:查看 ceph 中一个 pool 里的所有镜像
[mon@ptmind~]# rbd ls test kjh
3:查看新建的镜像的信息
[mon@ptmind~]# rbd -p test info kjh
4:查看 ceph pool 中一个镜像的信息
[mon@ptmind~]# rbd info -p test --image kjh rbd image 'kjh':
size 1000 MB in 250 objects
order 22 (4096 kB objects) block_name_prefix: rb.0.92bd.74b0dc51 format: 1
5:删除一个镜像
[mon@ptmind~]# rbd rm -p test kjh
6:调整一个镜像的尺寸
[mon@ptmind~]# rbd resize -p test --size 20000 kjh
[mon@ptmind~]# rbd -p test info kjh #调整后的镜像大小rbd image 'kjh':
size 2000 MB in 500 objects
order 22 (4096 kB objects) block_name_prefix: rb.0.92c1.74b0dc51 format: 1
7 :快照测试
1:新建个 pool 叫’ptmindpool’同时在下面创建一个’kjhimage’
[mon@ptmind~]# ceph osd pool create ptmindpool 256 256 pool 'ptmindpool' created
2:创建镜像
[mon@ptmind~]# rbd create kjhimage --size 1024 --pool ptmindpool
3:查看镜像
[mon@ptmind~]# rbd --pool ptmindpool ls kjhimage
4:创建 snap,快照名字叫’snapkjhimage’
[mon@ptmind~]# rbd snap create ptmindpool/kjhimage@snapkjhimage
5:查看 kjhimage 的 snap
[mon@ptmind~]# rbd snap ls ptmindpool/kjhimage SNAPID NAME SIZE
2 snapkjhimage 1024 MB
6:回滚快照,
[mon@ptmind~]# rbd snap rollback ptmindpool/kjhimage@snapkjhimage
7:删除 snap 删除 snap 报(rbd: snapshot 'snapshot-xxxx' is protected from removal.)写保护 ,使用 rbd snap unprotect volumes/snapshot-xxx' 解锁,然后再删除
[mon@ptmind~]# rbd snap rm ptmindpool/kjhimage@snapkjhimage
8:删除 kjhimage 的全部 snapshot
[mon@ptmind~]# rbd snap purge ptmindpool/kjhimage
9: 把 ceph pool 中的一个镜像导出导出镜像
[mon@ptmind~]# rbd export -p ptmindpool --image kjhimage /tmp/kjhimage.img Exporting image: 100% complete...done.
验证查看导出文件
l /tmp/kjhimage.img
-rw-r--r-- 1 root root 1073741824 Sep 24 23:15 /tmp/kjhimage.img
10:把一个镜像导入 ceph 中
[mon@ptmind~]# rbd import /tmp/kjhimage.img -p ptmindpool --image importmyimage1
Importing image: 100% complete...done.
验证查看导入镜像文件
rbd -pptmindpool ls
importmyimage1
十五:ceph 日志和调试设置
启动集群出现问题时,可以通过添加调试日志(默认在/var/log/ceph)选项到 Ceph 设置文件中来排错。开启或增加日志内容级别前,请确保系统磁盘上有足够的空余空间。如果系统运行良好,最好去除不必要的调试日志,想做性能优化可以将内存中的日志关掉以优化集群。在集群运行过程中输出debug 信息会拖慢系统,也浪费系统资源。
Ceph 的日志级别从 1 到 20,1 最精简,20 最详细,日志可分为系统设置日志文件输出级别和内存日志输出级别{log- level}/{memory-level},配置要参数先设定日志文件级别,再设定内存级别,两个数值必须用斜杠(/)分隔。
1:配置文件修改
要想在启动时激活 Ceph 的调试输出(即 dout()),就必须在 Ceph 配置文件中添加相应设置项。配置文件中
[global]组内的设置影响所有所有子系统守护进程,针对特定子系统守护进程的配置可以单独设置(即在[mon], [osd],
[mds]组内),比如:
[global]
debug ms = 1/5
[mon]
debug mon = 20 debug paxos = 1/5 debug auth = 2
[osd]
debug osd = 1/5 debug filestore = 1/5 debug journal = 1 debug monc = 5/20
[mds]
debug mds = 1
debug mds balancer = 1 debug mds log = 1 debug mds migrator = 1
2:在线修改日志输出级别
如果在运行时查看设置内容,你必须登录到运行守护进程的主机上,并按以下步骤操作:
ceph daemon {/path/to/admin/socket} config show | less
ceph daemon /run/ceph/ceph-mon.node241.asok config show|grep debug
要在运行时激活 Ceph 的调试输出(即 dout()),请使用 ceph tell 命令将相关参数注入到配置文件中:
ceph tell {daemon-type}.{daemon id or *} injectargs --{name} {value} [--{name} {value}]
{daemon-type}选项有 osd, mon 或者 mds。通过使用通配符*,你可以把设置应用到所有守护进程中去,或者通过 ID
号(即相应数字或字母)来应用到指定守护进程上去。
例如,增加名为 0,类型为 osd 的守护进程的日志级别,可使用下面的命令行: 查看默认值:
[root@node241 ~]# ceph daemon /run/ceph/ceph-osd.1.asok config show|grep debug_osd "debug_osd": "0/5",
[root@node241 ~]# ceph tell osd.1 injectargs --debug_osd 1/5 debug_osd=1/5
你也可以通过 ceph --admin-daemon 命令,登录到你要修改配置的守护进程主机上。比如:
[root@node241 ~]# ceph daemon osd.1 config set debug_osd 1/5
{
"success": ""
}
验证修改结果:
[root@node241 ~]# ceph daemon /run/ceph/ceph-osd.1.asok config show|grep debug_osd "debug_osd": "1/5
3:修改集群子系统,日志和调试设置
在多数情况下,你需要通过子系统开启调试日志输出功能。每一个子系统输出到磁盘上的日志文件和内存中的日志数据,都有一个日志级别。所以,你可以给这些子系统设置日志文件输出级别和内存日志输出级别。 Ceph 的日志级别从 1 到 20,1 最精简,20 最详细。
Ptmind Ceph Cluster 安装配置文档 --康建华
你可以通过只设定一个值,来使调试输出日志的文件级别和内存级别相同。比如,设定 debug ms = 5,Ceph 会
把日志的文件级别和内存级别都设为 5.也可以分别设置日志组织。先设定日志文件级别,再设定内存级别,两个数值必须用斜杠(/)分隔。
比如,你准备为名为 ms 的子系统设定日志文件级别为 1,日志内存级别为 5,应该写成 debug ms = 1/5.举例:
debug {subsystem} = {log-level}/{memory-level} #for example
debug mds log = 1/20
4:日志输出级别默认值
参考文章:
http://xiaoquqi.github.io/blog/2015/06/28/ceph-performance-optimization-summary/?utm_source=tuicool http://cloud.51cto.com/art/201501/464162_2.htm http://docs.openfans.org/ceph/ceph4e2d658765876863 http://docs.ceph.com/docs/master/rados/configuration/ceph-conf/?highlight=osd journal size
http://mirrors.myccdn.info/ceph/doc/docs_zh/output/html/search/?q=filestore+queue+max+ops&check_keywords=yes& area=default
http://mp.weixin.qq.com/s? biz=MzA3NjkwNjM4Nw==&mid=210896948&idx=1&sn=19d9449e24a1e6155add01a675b9 bc2d&scene=1&srcid=0916ZendiZMRgMVji22676A0#rd
http://baike.baidu.com/link?url=2NVF_-7rznBadF XddOIm5VfJKma6g9Tk2MYDYfa4wbd-4e6kUnbA6oUTAT7JMnK6- 808AiM- m3LI6tXcWVf_&ADUIN=3312909837&ADSESSION=1442382049&ADTAG=CLIENT.QQ.5385_.0&ADPUBNO=26450#usercons
ent# http://shuechaolau.iteye.com/blog/1558046#userconsent#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}