3 模型【优化模型】
优化模型
通过数据收集、数据预处理、训练模型、测试模型上述四个步骤,一般可以得到一个不错的模型,但是一般得到的都是一个参数收敛的模型,然而我们模型还有超参数或不同的核函数等。我们模型优化一块主要是对模型超参数的优化,简而言之就是输入一组超参数,对每个超参数对应的模型进行测试,选择这一组超参数中最优的模型。
1、网格搜索法
网格搜索法相当于对你输入的每一个参数都进行验证,并且可以设置多个参数。
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import GridSearchCV
iris = datasets.load_iris()
X = iris.data
y = iris.target
svc = SVC(gamma="scale")
# 自定义参数,每个kernel对应一个C 总共有2*4=8种选择
parameters = {'kernel': ('linear', 'rbf'), 'C': [0.1, 1, 10, 100]}
# 使用交叉验证,获得打乱的CV
cv = ShuffleSplit(n_splits=10, test_size=0.3, random_state=1)
scoring = 'accuracy'
# 运用网格搜索法 svc模型 cv=cv交叉验证 也可以设置成cv=5
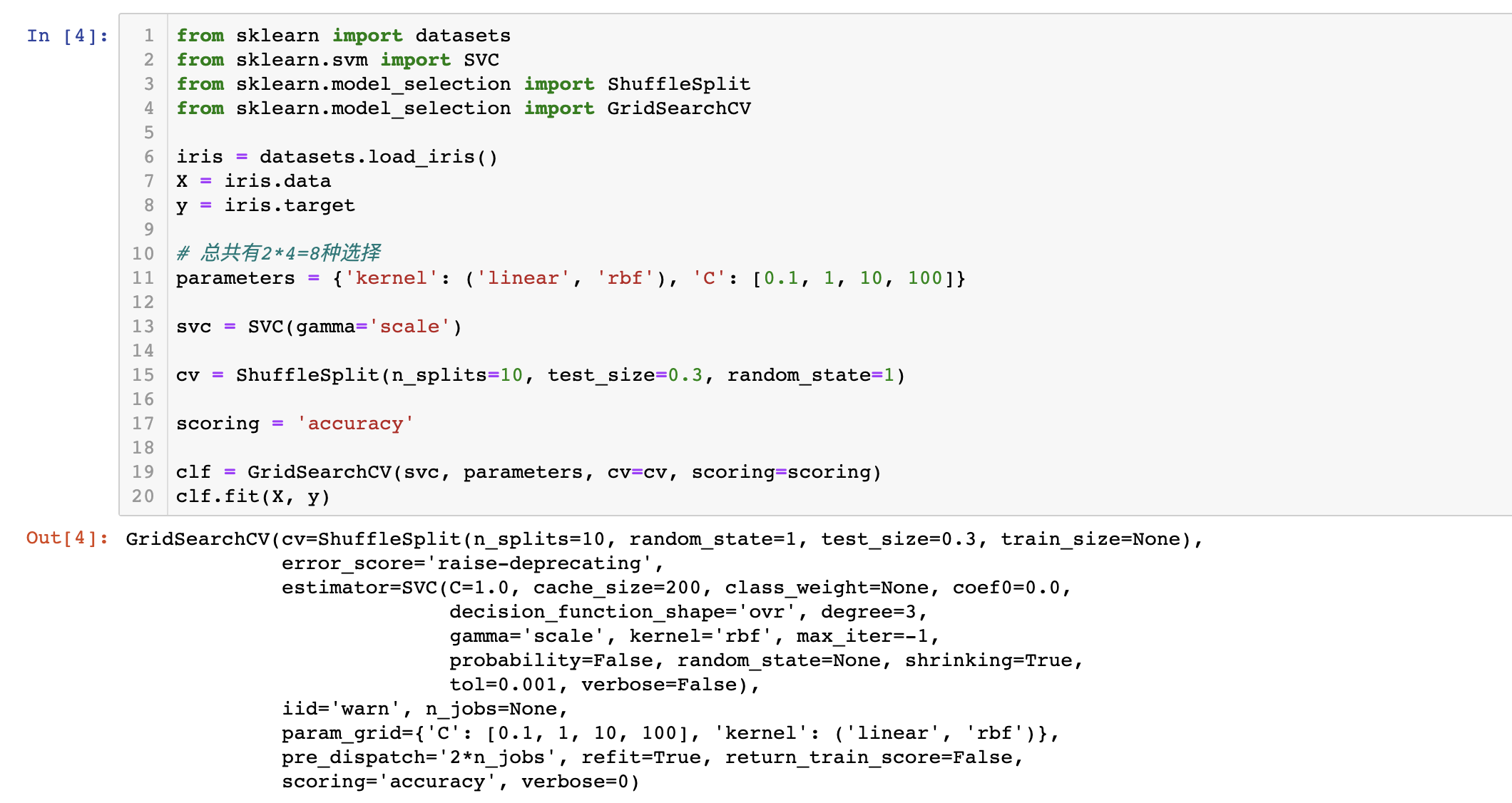
clf = GridSearchCV(svc, parameters, cv=cv, scoring=scoring)
clf.fit(X, y)
结果:
可以分为上面几类: 第一类是时间, 第二类是参数, 第三类是测试分数,其中又分为每次交叉验证的参数和统计的参数,第四类是训练分数,其中也分为每次交叉验证的参数和统计的参数。
clf.cv_results_.keys()
结果:

返回最优的参数
clf.best_params_

返回模型最好的分数
clf.best_score_
2、随机搜索法
随机搜索法一般用于超参数过多的时候,即当一组超参数有上千上万个的时候,我们会通过随机搜索法随机选择一部分超参数,对模型调优。一般随机搜索法会通过sklearn.model_selection.ParameterSampler方法进行采样。
2.1、随机采样
from sklearn.model_selection import ParameterSampler
from scipy.stats.distributions import expon
import numpy as np
np.random.seed(1)
param_grid = {'a' : [1, 2], 'b' : expon()}
# expon为指数分布,该分布取值为无数个,即param_grid有无数个参数
param_grid

# n_iter=4指定采样次数为4次
param_list = list(ParameterSampler(param_grid, n_iter=5))
rounded_list = [dict((k, round(v, 2)) for (k, v) in d.items())
for d in param_list]
rounded_list

2.2、随机搜索法
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import RandomizedSearchCV
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 总共有2*5*5=50种选择
parameters = {'kernel': ('linear', 'rbf'), 'C': [
0.1, 1, 10, 100, 1000], 'gamma': [0.1, 1, 10, 100, 1000]}
svc = SVC()
cv = ShuffleSplit(n_splits=5, test_size=0.3, random_state=1)
scoring = 'accuracy'
clf = RandomizedSearchCV(svc, parameters, cv=cv, scoring=scoring, n_iter=15)
clf.fit(X, y)

clf.cv_results_.keys()

clf.best_params_
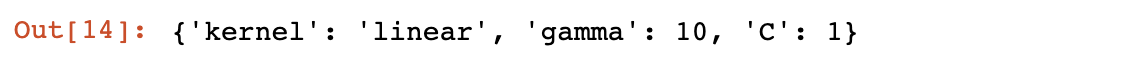



{kind=link}