手写数字识别应用程序
导入模块

import os
import pylab
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from sklearn.svm import SVC
%matplotlib inline
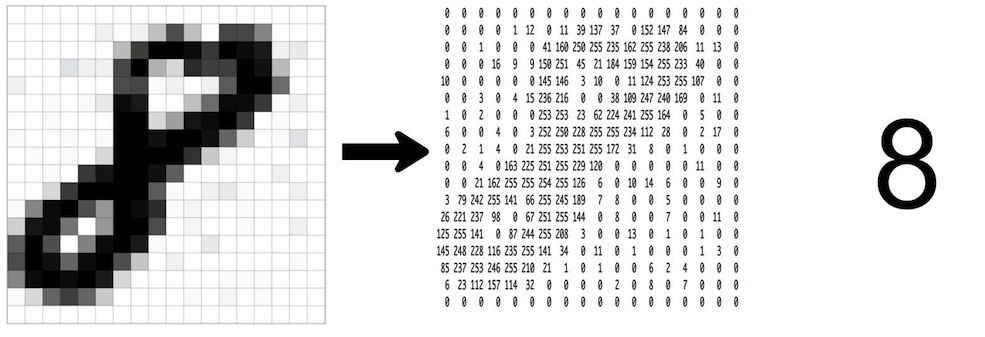
图像转向量
def img2vector(filename):
"""将32*32的二进制图像转换为1*1024向量"""
# 构造一个一行有1024个元素的即 1*1024 的零向量
return_vect = np.zeros((1, 1024))
with open(filename, 'r', encoding='utf-8') as fr:
# 读取文件的每一行的所有元素
for i in range(32):
line_str = fr.readline()
# 把文件每一行的所有元素按照顺序写入构造的 1*1024 的零矩阵
for j in range(32):
return_vect[0, 32 * i + j] = int(line_str[j])
# 返回转换后的 1*1024 向量
return return_vect
训练并测试模型
# 手写数字集另一种导入方式
# 直接导入不贴近工业
def hand_writing_class_test():
"""手写数字分类测试"""
# 对训练集数据做处理,构造一个 m*1024 的矩阵,m 是训练集数据的个数
hw_labels = []
training_file_list = os.listdir('datasets/digits/trainingDigits') # type:list
m = len(training_file_list)
# 初始化训练的Mat矩阵,测试集
training_mat = np.zeros((m, 1024))
for i in range(m): # 0,1,2,3,4,...,1933
# 取出文件中包含的数字
file_name_str = training_file_list[i] # type:str
file_str = file_name_str.split('.')[0]
class_num_str = int(file_str.split('_')[0])
# 添加标记到hw_labels中
hw_labels.append(class_num_str)
# 把该文件中的所有元素构造成 1*1024 的矩阵后存入之前构造的 m*1024 的矩阵中对应的行
training_mat[i, :] = img2vector(
'datasets/digits/trainingDigits/{}'.format(file_name_str))
# 训练模型
clf = SVC(C=200, kernel='rbf', gamma='auto')
clf.fit(training_mat, hw_labels)
# 返回testDigits目录下的文件列表
test_file_list = os.listdir('digits/testDigits')
# 错误检测计数
error_count = 0
# 测试数据的数量
m_test = len(test_file_list)
# 对测试集中的单个数据做处理
for i in range(m_test):
# 取出文件中包含的数字
file_name_str = test_file_list[i]
file_str = file_name_str.split('.')[0]
class_num_str = int(file_str.split('_')[0])
# 把该文件中的所有元素构造成一个 1*1024 的矩阵
vector_under_test = img2vector(
'digits/testDigits/{}'.format(file_name_str))
# 对刚刚构造的 1*1024 的矩阵进行分类处理判断结果
classifier_result = clf.predict(vector_under_test)
# print("分类返回结果为{}\t真实结果为{}".format(classifier_result, class_num_str))
# 对判断错误的计数加 1
if classifier_result != class_num_str:
error_count += 1
print("总共错了{}个数据\n错误率为{:.2f}".format(
error_count, error_count/m_test * 100))
return clf
clf = hand_writing_class_test()
总共错了13个数据
错误率为1.37
模型转应用程序
展示图片
img = Image.open('img/2.jpg')
plt.imshow(img)
plt.show()

处理图片
def img_binaryzation(img_filename):
"""处理图片为文本文件"""
# 调整图片的大小为 32*32px
img = Image.open(img_filename)
out = img.resize((32, 32), Image.ANTIALIAS)
img_filename = 'test.jpg'
out.save(img_filename)
# RGB 转为二值化图
img = Image.open(img_filename)
lim = img.convert('1')
lim.save(img_filename)
img = Image.open(img_filename)
# 将图像转化为数组并将像素转换到0-1之间
img_ndarray = np.asarray(img, dtype='float64') / 256
# 将图像的矩阵形式转化成一位数组保存到 data 中
data = np.ndarray.flatten(img_ndarray)
# 将一维数组转化成矩阵
a_matrix = np.array(data).reshape(32, 32)
# 将矩阵保存到 txt 文件中转化为二进制0,1存储
img_filename_list = img_filename.split('.') # type:list
img_filename_list[-1] = 'jpg'
txt_filename = '.'.join(img_filename_list)
pylab.savetxt(txt_filename, a_matrix, fmt="%.0f", delimiter='')
# 把 .txt 文件中的0和1调换
with open(txt_filename, 'r') as fr:
data = fr.read()
data = data.replace('1', '2')
data = data.replace('0', '1')
data = data.replace('2', '0')
with open(txt_filename, 'w') as fw:
fw.write(data)
return txt_filename
预测图片
def hand_writing_predict(img_filename):
# 处理图片为文本文件
txt_filename = img_binaryzation(img_filename)
# 把该文件中的所有元素构造成一个 1*1024 的矩阵
vector_under_test = img2vector(txt_filename)
# 对刚刚构造的 1*1024 的矩阵进行分类处理判断结果
classifier_result = clf.predict(vector_under_test)
return classifier_result
print('**结果:{}**'.format(hand_writing_predict('img/2.jpg')))
os.remove('test.jpg')
**结果:[2]**



{kind=link}