A-05 前向选择法和前向梯度法
前向选择法和前向梯度法

由于前向选择法和前向梯度法的实现原理涉及过多的矩阵运算,本文只给出两种算法的思路。两者实现都是把矩阵中的向量运算具体化成平面几何中的向量运算。
前向选择法
前向选择法是一种典型的贪心算法。
通常用前向选择法解决线性模型的回归系数。对于一个有\(m\)个样本,每个样本有\(n\)个特征的训练集而言,假设可以拟合一个线性模型\(Y=\omega^TX\),其中\(Y\)是\(m*1\)的向量,\(X\)是\(m*n\)的矩阵,\(\omega\)是\(n*1\)的向量。即可通过前向选择法求得最小化该模型的参数\(\omega\)。
余弦相似度求投影
首先把矩阵\(X\)看成\(n\)个\(m*1\)的向量\(X_i \quad(i=1,2,\cdots,n)\),之后选择与向量\(Y\)余弦相似度最大,即与\(Y\)最为接近的一个变量\(X_i\),然后用\(X_i\)逼近\(Y\),即可得到
其中\(\omega_i={\frac{<X_i,Y>}{{||X_i||}^2}}\quad\text{余弦相似度}\),其中\(<X_i,Y>=|Y|*\cos\alpha\),\(\alpha\)是\(X_i\)和\(Y\)的夹角。
上述公式因此可以认为\(\hat{Y}\)是\(Y\)在\(X_i\)上的投影。
得到\(Y\)的接近值\(\hat{Y}\)后既可以得到残差值为\(Y_{err}=Y-\hat{Y}\),由于\(\hat{Y}\)是投影,则\(\hat{Y}\)和\(X_i\)是正交的,因此可以以\(Y_{err}\)为新的变量,从剩下的\(X_i\quad(i=1,2,i-1,i+2,\cdots,n)\)中,选择一个新的最接近残差\(Y_{err}\)的\(X_i\)重复上述投影和计算残差的流程,直至残差为0,停止算法。即可得到\(\omega\)。
举例
# 举例图例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
# X1*w1
plt.annotate(xytext=(2, 5), xy=(8, 5), s='', color='r',
arrowprops=dict(arrowstyle="->", color='r'))
plt.text(6, 4.5, s='$X_1*\omega_1$', color='g')
# X2*w2
plt.annotate(xytext=(8, 5), xy=(9.3, 7.5), s='', color='r',
arrowprops=dict(arrowstyle="->", color='r'))
plt.text(9.3, 7, s='$X_2*\omega_2$', color='g')
# X1
plt.annotate(xytext=(2, 5), xy=(4, 5), s='', color='r',
arrowprops=dict(arrowstyle="->", color='k'))
plt.text(2.5, 4.5, s='$X_1$', color='g')
# X2
plt.annotate(xytext=(2, 5), xy=(3, 7), s='', color='r',
arrowprops=dict(arrowstyle="->", color='k'))
plt.text(2, 6, s='$X_2$', color='g')
# X2
plt.annotate(xytext=(8, 5), xy=(9, 7), s='', color='r',
arrowprops=dict(arrowstyle="->", color='k'))
plt.text(8.2, 6.5, s='$X_2$', color='g')
# Y
plt.annotate(xytext=(2, 5), xy=(8, 8), s='', color='r',
arrowprops=dict(arrowstyle="->", color='k'))
plt.text(5, 7.5, s='$Y$', color='g')
#
plt.annotate(xytext=(8, 5), xy=(8, 8), s='', color='r',
arrowprops=dict(arrowstyle="-", color='gray'))
plt.text(7.5, 6.5, s='$Y_1$', color='g')
#
plt.annotate(xytext=(8, 8), xy=(9.3, 7.5), s='',
arrowprops=dict(arrowstyle="-", color='gray'))
plt.text(8.5, 8, s='$Y_2$', color='g')
plt.xlim(0, 11)
plt.ylim(2, 10)
plt.title('前向选择法举例', fontproperties=font, fontsize=20)
plt.show()

上图假设\(X\)为\(2\)维,首先可以看出,离\(Y\)最接近的是\(X_1\),因此画出\(Y\)在\(X_1\)上的投影红线\(X_1*\omega_1\),此时残差为灰线\(Y_1\)。由于目前只剩下\(X_2\),所以接着用残差\(Y_1\)在\(X_2\)上投影得到红线\(X_2*\omega_2\),如果不只是\(X_2\),则选择最接近\(Y_1\)的\(X_i\)。此时的\(X_1\omega_1+X_2\omega_2\)则模拟了\(Y\),即\(\omega=[\omega_1,\omega_2]\)。
前向选择法优缺点
优点
- 算法对每个\(X_i\)只做一次操作,速度快。
缺点
- 由于变量\(X_i\)之间不是正交的,所以每次都必须做投影缩小残差,所以前向选择法最后只能给出一个局部近似解。(可以考虑下面的前向梯度法)
前向梯度法

前向梯度法类似于前向选择法,不同之处在于前向梯度法废除了前向选择法的投影逼近\(Y\),取而代之的是在每次最接近\(Y\)的向量\(X_i\)的方向上移动一小步,并且向量\(X_i\)移动会不会被剔除,而是继续从\(X_i \quad(i=1,2,i-1,i,i+1,\cdots,n)\)中选择一个最接近残差\(Y_{err}\)(注:残差计算方式类似于前向选择法)的向量\(X_i\),然后再走一小步,直至残差为0,停止算法,即可得到\(\omega\)。
举例
# 举例图例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
# X1
plt.annotate(xytext=(2, 5), xy=(3, 5), s='', color='r',
arrowprops=dict(arrowstyle="->", color='r'))
plt.text(2.4, 4.8, s='$\epsilon{X_1}$', color='g')
# eX1
plt.annotate(xytext=(2, 5), xy=(4, 5), s='', color='r',
arrowprops=dict(arrowstyle="->", color='r'))
plt.text(3.2, 4.8, s='$\epsilon{X_1}$', color='g')
# eX1
plt.annotate(xytext=(2, 5), xy=(5, 5), s='', color='r',
arrowprops=dict(arrowstyle="->", color='r'))
plt.text(4.2, 4.8, s='$\epsilon{X_1}$', color='g')
# eX1
plt.annotate(xytext=(2, 5), xy=(2.8, 5), s='', color='r',
arrowprops=dict(arrowstyle="->", color='k'))
plt.text(1.9, 4.8, s='$X_1$', color='g')
# eX1
plt.annotate(xytext=(6.1, 6.2), xy=(7, 6.2), s='', color='r',
arrowprops=dict(arrowstyle="->", color='r'))
plt.text(6.2, 6, s='$\epsilon{X_1}$', color='g')
# ex2
plt.annotate(xytext=(5, 5), xy=(6.2, 6.2), s='', color='r',
arrowprops=dict(arrowstyle="->", color='r'))
plt.text(5.2, 5.8, s='$\epsilon{X_2}$', color='g')
# X2
plt.annotate(xytext=(2, 5), xy=(3, 6), s='', color='r',
arrowprops=dict(arrowstyle="->", color='k'))
plt.text(2, 5.5, s='$X_2$', color='g')
# X2
plt.annotate(xytext=(5, 5), xy=(6, 6), s='', color='r',
arrowprops=dict(arrowstyle="->", color='k'))
plt.text(5.6, 5.5, s='$X_2$', color='g')
# Y
plt.annotate(xytext=(2, 5), xy=(8, 7), s='', color='r',
arrowprops=dict(arrowstyle="->", color='k'))
plt.text(5, 6.2, s='$Y$', color='g')
plt.annotate(xytext=(5, 5), xy=(8, 7), s='', color='r',
arrowprops=dict(arrowstyle="-", color='gray'))
plt.xlim(1, 9)
plt.ylim(4, 8)
plt.title('前向梯度法举例', fontproperties=font, fontsize=20)
plt.show()
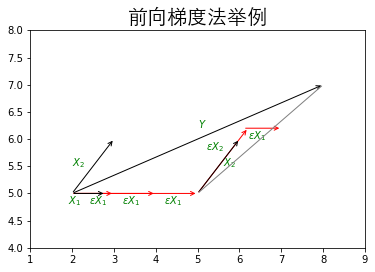
上图假设\(X\)为\(2\)维,首先可以看出,离\(Y\)最接近的是\(X_1\),因此沿着向量\(X_i\)的方向走上一段距离,此处的\(\epsilon\)是一个手动调整的超参数,走了一段距离后发现,离残差\(Y_{err}\)最近接的还是\(X_1\),因此继续接着走一段距离,直到走到离残差\(Y_{err}\)最近的为\(X_2\)的时候,沿着向量\(X_2\)的方向走上一段距离,发现此时残差\(Y_{err}\)离\(X_1\)更近,则沿着\(X_1\)走一段距离,直到走到最后残差为0,停止算法,即可得到\(\omega\)。
前向梯度法优缺点
优点
- 可以手动控制\(\epsilon\)的大小,即可以控制算法的精准度,如果\(\epsilon\)较小的时候算法精准度很高
缺点
- \(\epsilon\)小,算法精准度高,同时算法迭代次数增加;\(\epsilon\)大,算法精准度降低。类似于梯度下降,这是前向梯度法较大的一个问题。(参考最小角回归法)



{kind=link}